目录
- 一、问题引入
- 二、线段树的构建
- 三、线段树的单点修改与查询
- 1、修改
- 2、查询
- 四、线段树的区间修改与查询
- 1、修改
- 2、查询
一、问题引入
对于一般的区间问题,比如RMQ(区间的最值)、区间的和,如果使用朴素算法,即通过遍历的方式求取,则时间复杂度为O(N),在常数次查询的情况下可以接受,但是当区间长度为N,查询次数为M时,查询复杂度就变成O(M*N)。在M和N较大时,这样的复杂度无法满足要求。
对于这类问题,有一个神奇的数据结构,能够在O(M*logN)的时间内解决问题——线段树。
二、线段树的构建
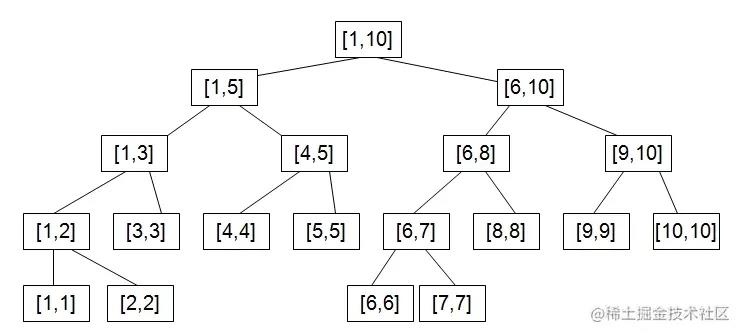
线段树的每个节点可以根据需要存储一个区间的最大/最小值/和等内容。它的构建方式与堆的构建方式类似,即线段树是基于数组实现的树。
以构建区间和的线段树为例:对于给定数组nums,设大小为n,则区间范围为[0, n-1]。
- 规定线段树的根节点,即
SegmentTree[0]存储[0, n)的和。 - 根据堆的构建方法,父节点的左孩子为2*parent+1,右孩子为2*parent+2。
- 假设父节点存储[start, end]的和,
mid=start+(end - start>>1),则左孩子存储[start, mid]的和,右孩子存储[mid+1, end]的和 - 注:
mid=start+(end - start>>1)是一种避免整形溢出的写法,等价于mid=(start+end)/2。 - 由于父节点的值依赖于两个子节点,因此线段树的构建是一种后序遍历。
// nums是给定大小为n的数组,par表示当前正在构建的线段树节点下标,start和end是当前需要计算的区间。
void build(vector<int>& nums, int par, int start, int end)
{
if (start == end) // 区间大小为1,即单个点,因此当前节点的区间和就是单点的值
{
_segmentTree[par] = nums[start];
return;
}
// 如果区间大于1,则先求当前节点的左孩子和右孩子
int mid = start + (end - start >> 1);
int lchild = 2 * par + 1;
int rchild = 2 * par + 2;
build(nums, lchild, start, mid); // 递归求左节点的区间和
build(nums, rchild, mid + 1, end); // 递归求右孩子的区间和
// 当前节点的值就是左孩子的值+右孩子的值
_segmentTree[par] = _segmentTree[lchild] + _segmentTree[rchild];
}
注:在极端情况下,最后一层有n个结点,此时线段树是一棵完全二叉树,树的高度h=log2N向上取整+1≤log2N+2。
因此,树的节点数量为2^h-1^≤2^logN+2^-1=4N-1。
所以,线段树数组的大小一般为4*n。
此外,如果想要避免因为n过大而导致MLE,则可以选择map/unordered_map来存储线段树,不过这会增加时间成本。一般来说直接开辟4*n的线段树数组是最方便书写的。
三、线段树的单点修改与查询
1、修改
单点修改要求:修改原数组下标index处的值。此时我们需要对线段树进行更新:
- 依然是从根节点开始进行修改。
- 根据修改的下标index,判断应当修改当前节点的左子树还是右子树。
- 在递归修改左右孩子节点以后,再根据左右孩子的值重新对父节点进行赋值(
pushUp())。
void update(int index, int val, int par, int start, int end)
{
if (start == end) // 递归结束条件依然是当前区间为单点
{
segtree[par] = val;
return;
}
int mid = start + (end - start >> 1);
// 递归修改左孩子或右孩子
if (index <= mid)
update(index, val, 2 * par + 1, start, mid);
else
update(index, val, 2 * par + 2, mid + 1, end);
// 修改完成后重新对父节点赋值
pushUp(par);
}
// pushUp负责利用左右孩子的值更新父节点
void pushUp(int par)
{
segtree[par] = segtree[2 * par + 1] + segtree[2 * par + 2];
}
2、查询
由于每个节点可以存储最值和区间和,因此求最值与求和的过程几乎相同,这里以求和为例:
假设当前节点的区间为[start, end],中点为mid。
对于给定区间[left, right],它有三种分布情况:
- right<=mid,即给定区间全部在左节点中,因此只需要递归左子树计算区间和即可。
- left>mid,即给定区间全部在右节点中,因此只需要递归右子树计算区间和即可。
- 给定区间有一部分在左子树,一部分在右子树,因此需要分成两部分,一部分是[left, mid],这部分到左子树中递归求取。另一部分是[mid+1,right],这部分到右子树中递归求取。
// [left, right]是目标求和区间,par是当前节点编号,当前节点存储区间[start, end]的和
int query(int left, int right, int par, int start, int end)
{
// 目标求和区间与当前节点的区间吻合,直接返回当前节点的值即可
if (left == start && right == end)
return segtree[par];
int mid = start + (end - start >> 1);
if (right <= mid) // 目标求和区间全部在左子树
return query(left, right, 2 * par + 1, start, mid);
else if (left > mid) // 目标求和区间全部在右子树
return query(left, right, 2 * par + 2, mid + 1, end);
else // 目标求和区间分布在左右子树上
return query(left, mid, 2 * par + 1, start, mid) +
query(mid + 1, right, 2 * par + 2, mid + 1, end);
}
四、线段树的区间修改与查询
1、修改
区间修改要求:修改原数组[left, right]处的值,将它们全部加/减value,或者全部改为value。此时我们需要对线段树进行更新。
我们可以选择将[left, right]看成一个个点,然后进行单点修改,但是一个点的修改消耗为log2N,修改整个区间就是C*log2N了,M次修改就是M*C*log2N,这比暴力法的M*C还要差。
我们使用懒标记法,引入一个lazy变量:
依然从根节点开始修改。
如果节点对应的区间[start, end]完全包含在[left, right]中时,即left≤start≤end≤right,此时将这个节点的值进行修改,并按要求修改lazy,比如:对给定区间整体加4,则lazy加4,整体减3,则lazy减3。
修改完lazy数组后,我们不再需要修改它的子节点,因此lazy的意义在于减少向下更新的次数,从而降低时间复杂度**「懒的体现」**。
如果节点对应的区间[start, end]不完全包含在[left, right]中时,则递归修改左右节点,直至对应节点的区间与待修改的区间没有交集**「递归的结束条件」**。子树修改完成后,再利用子节点的值更新父节点(pushUp())。
注意:由于lazy变量的存在,使用子节点的值更新父节点时,需要加上父节点的lazy值,因为该值是由于"偷懒"而没有添加在子节点上的。
// 以「将给定区间内的数加x,查询每个节点存储对应区间的和」为例:
void update(int left, int right, int x, int node, int start, int end)
{
// 区间没有交集,无需修改
if (end < left || right < start)
return;
// 当前节点对应的区间被需要修改的区间完全包含
if (left <= start && right >= end)
{
segtree[node].val += x * (end - start + 1);
segtree[node].lazy += x;
return;
}
// 不被[left, right]完全包含,则说明本轮只会更新[start, end]的一部分,因此不能再"偷懒"直接将x加在lazy上了
// 而是先根据lazy的值修改左右子节点,然后再递归修改左右子树
int mid = start + ((end - start) >> 1);
// 先利用lazy修改孩子节点
pushDown(node, mid - start + 1, end - mid);
// 递归修改孩子节点
update(left, right, 2 * node + 1, start, mid);
update(left, right, 2 * node + 2, mid + 1, end);
// 利用左右子树的区间最大值确定父节点的区间最大值
pushUp(par);
}
void pushUp(int par)
{
segtree[par].val = segtree[2 * par + 1] + segtree[2 * par + 2] + segtree[par].lazy;
}
// par表示父节点,ln表示左孩子的区间长度,rn表示右孩子的区间长度
void pushDown(int par, int ln, int rn)
{
if (segtree[par].lazy != 0)
{
segtree[2 * par + 1].val += segtree[par].lazy * ln; // 修改左孩子的值
segtree[2 * par + 1].lazy += segtree[par].lazy; // 偷懒,不再往下继续修改,因此左孩子继承父节点的lazy值
segtree[2 * par + 2].lazy += segtree[par].lazy * rn;
segtree[2 * par + 2].lazy += segtree[par].lazy;
segtree[par].lazy = 0; // 父节点的lazy已经分配到子节点了,因此父节点lazy清零
}
}
2、查询
查询的过程与修改几乎相同:
- 依然从根节点开始查询。
- 如果当前节点有懒标记,此时返回节点的值,无需向下遍历。
- 当某个节点对应的区间[start, end]完全包含在[left, right]中时,即
left≤start≤end≤right,则该节点的值是我们最终结果的子集,直接返回节点值即可。 - 如果不完全包含,则递归查询左右子树,直至对应节点的区间与待修改的区间没有交集**「递归的结束条件」**。利用子树的查询结果作为最终的返回结果。
// 以「将给定区间内的数加x,查询每个节点存储对应区间的和」为例:
bool query(int left, int right, int node, int start, int end)
{
// 区间没有交集,无需查询
if (end < left || right < start)
return false;
// 有懒标记,则无需查询左右孩子,而是直接返回节点值,外加懒标记
// 或者当前节点对应的区间被需要查询的区间完全包含,则直接返回节点值
if (segtree[node].lazy || left <= start && right >= end)
return segtree[node].val;
int mid = start + ((end - start) >> 1);
// 不完全包含,则先根据lazy修改子节点,再递归查询左右子树的和
pushDown(node, mid - start + 1, end - mid);
return query(left, right, 2 * node + 1, start, mid) +
query(left, right, 2 * node + 2, mid + 1, end);
}
// par表示父节点,ln表示左孩子的区间长度,rn表示右孩子的区间长度
void pushDown(int par, int ln, int rn)
{
if (segtree[par].lazy != 0)
{
segtree[2 * par + 1].val += segtree[par].lazy * ln; // 修改左孩子的值
segtree[2 * par + 1].lazy += segtree[par].lazy; // 偷懒,不再往下继续修改,因此左孩子继承父节点的lazy值
segtree[2 * par + 2].lazy += segtree[par].lazy * rn;
segtree[2 * par + 2].lazy += segtree[par].lazy;
segtree[par].lazy = 0; // 父节点的lazy已经分配到子节点了,因此父节点lazy清零
}
}
以上就是C++ 线段树原理与实现示例详解的详细内容,更多关于C++ 线段树原理的资料请关注自由互联其它相关文章!