目录
- 前言
- 一、什么是字节对齐
- 二、结构体字节对齐
- 三、#pragma pack()的使用
- 总结
前言
本教程可能会用到一点汇编的知识,看不懂没关系,知道是那个意思就行了。使用的工具是vs2010。
一、什么是字节对齐
字节对齐是字节按照一定规则在空间上排列。
现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特 定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。
在我们之前写程序的时候可能会发现有的时候你定义的变量是一个字节,但是他在内存中依然按照四个字节给你存储,因为在32为系统中,4字节对齐执行效率是最快的。这就是一种牺牲内存换取性能的方案。
举个栗子
我们知道,全局变量在在内存中是有一个固定的地址的,如果不重新编译的话,这个地址是不会改变的。所以我们拿全局变量举例。
如下,我们定义两个全局变量:

一个是char(单字节)的一个是int(4字节的)
然后我们在main函数中给他们赋值,如下:

然后断点、F7编译、F5调试、ALT+8转到反汇编:
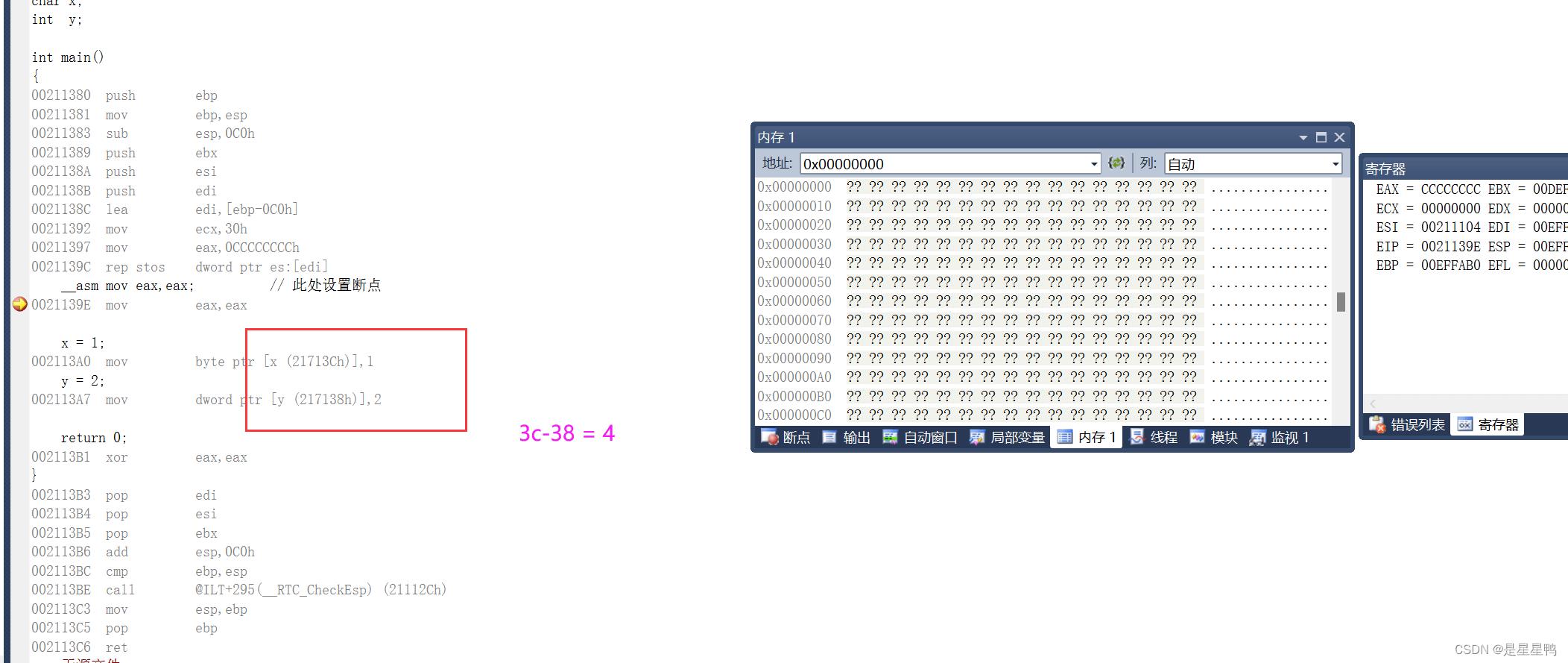
可以看到他们之间差值为4字节
再次测试,如下:
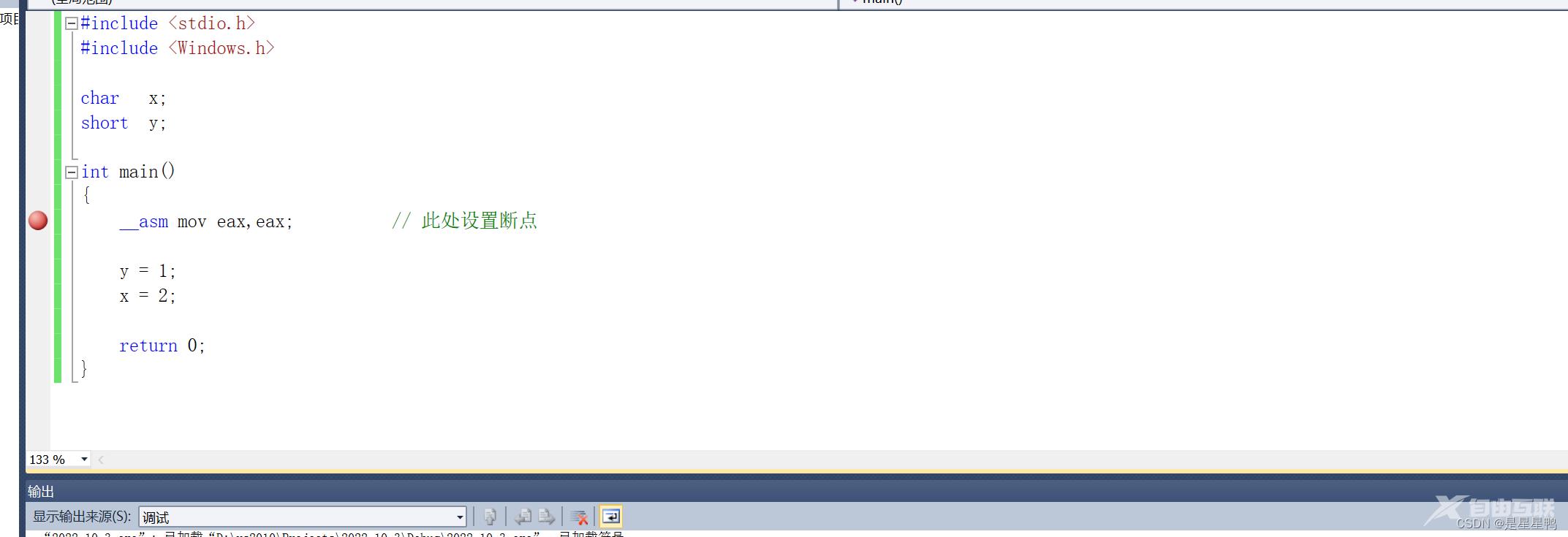
反汇编:

差值为2。
因为字节对齐的原因,int类型的起始地址必须是4的整数倍,short类型的起始地址也必须是2的倍数,当然char就没有那么约束了,因为它只是一个字节的。并不是说char类型的变量与int变量的差值是因为int类型占了四个字节所以差值才为4 。
再做测试,如下:
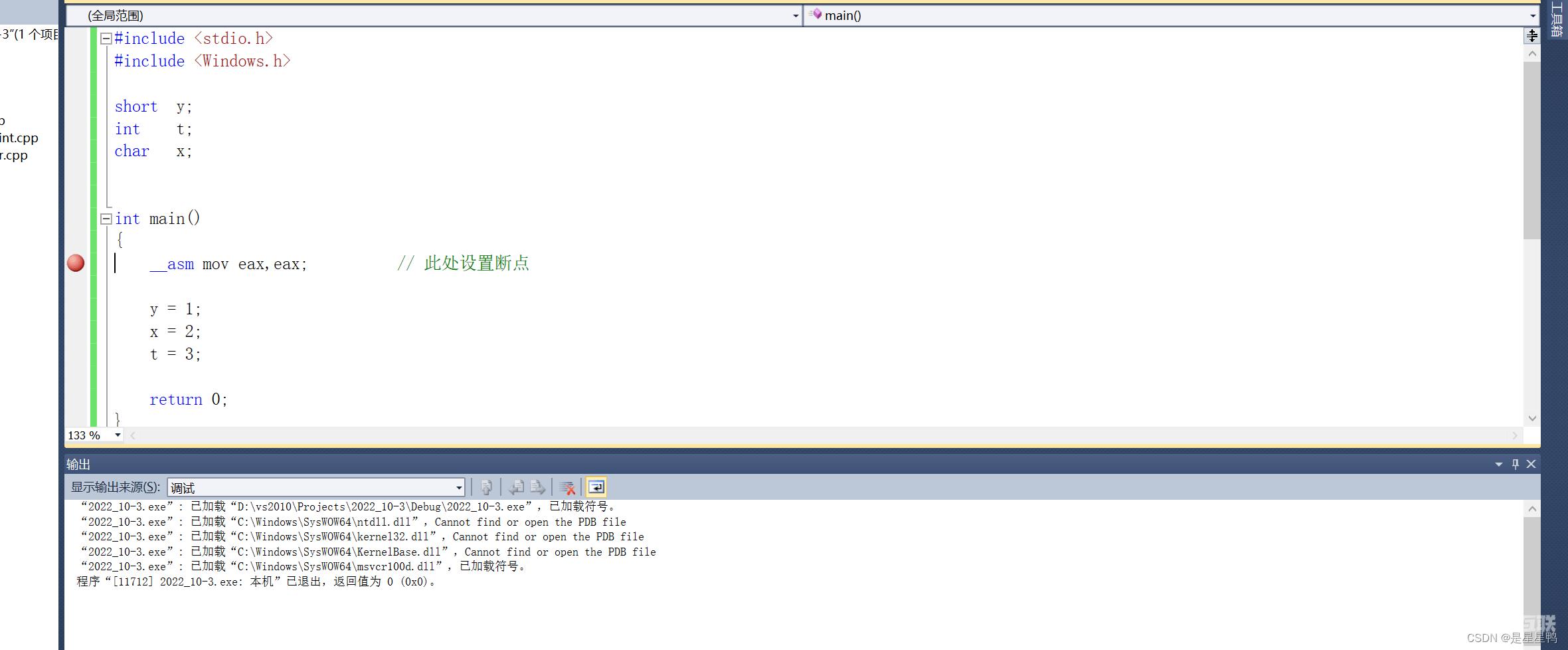
打乱顺序。查看反汇编:
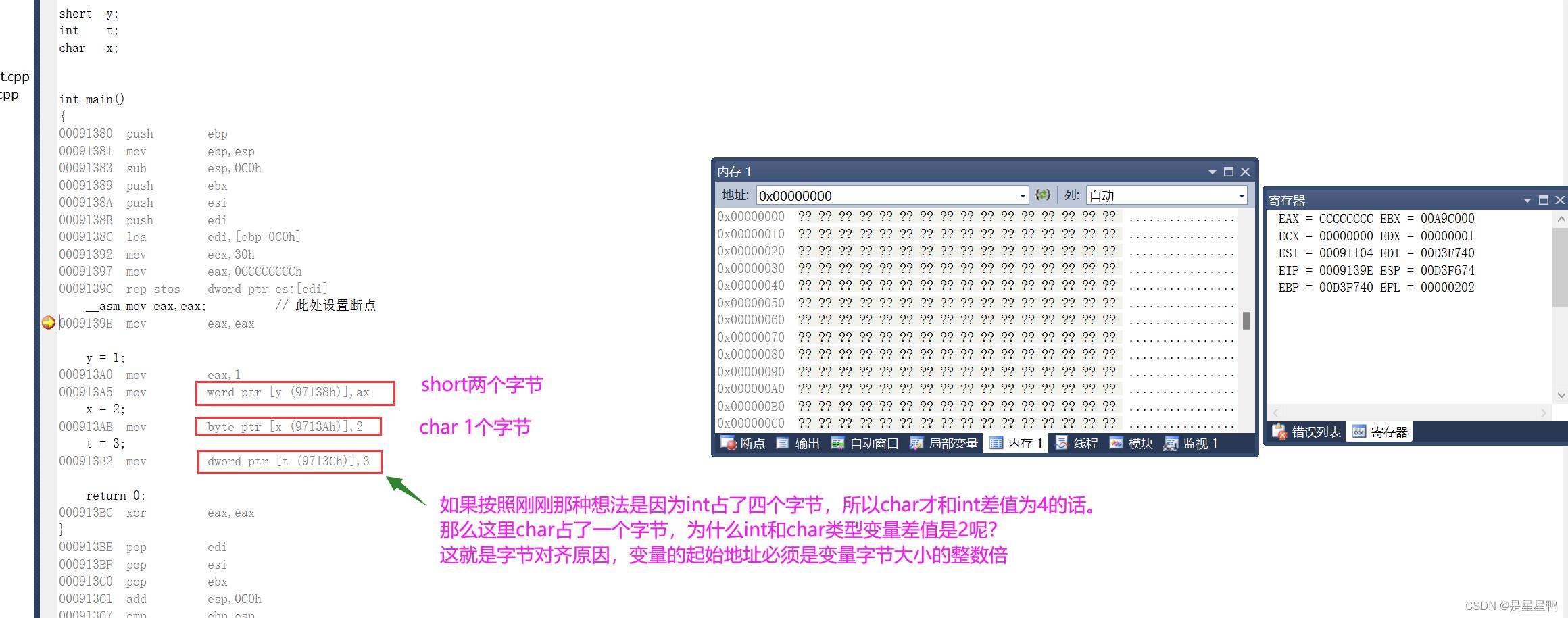
总结如图。
再次强掉、因为字节对齐的原因,变量的起始地址必须是变量字节大小的整数倍
二、结构体字节对齐
结构体中成员的存储方式也是按照上面的字节对齐方式进行存储的。不过有一点区别:结构体的起始地址是其最宽数据类型的整数倍(千万不要死记:结构体宽度就是最宽数据类型的整数倍,因为这样容易忘,下面我来和大家分析为什么是这样,知道为什么才能记得更久)。
举个栗子

结果:

我们分析一下:
int 4字节、char 1字节、double 8字节,按理说应该是13字节对吧。
分析如下:

int类型占了4个字节,这个时候char类型因为字节对齐的原因、他的起始地址是1的整数倍,所以它可以挨着int类型。但是double,他是8个字节的,由于字节对齐的原因、他的起始地址必须是8的倍数,所以他和char类型之间会差3。但是int、char、double他们是一个结构体的成员,不是分开存储的。所以char和double之间空的三个字节因为字节对齐的原因必须补齐。
再来:

可以先猜测一下结果。
结果如下:

这里大家可以试着推测,只需要记住因为字节对齐的原因,char起始地址必须是1的整数倍、int必须是4的整数倍等等。
三、#pragma pack()的使用
当对内存要求较高的时候,我们不得不抛弃性能。这个时候可以通过#pragma pack(n)来强制结构体成员的对齐方式
#pragma pack(1)
struct st_info
{
char a;
int b;
};
#pragma pack()
<1> #pragma pack(n)中的n用来设定变量以n字节的方式对齐,可以设定的值包括:1、2、4、8,VC编译器默认是8。
<2> 若需要强制取消字节对齐方式,则可使用#pragma pak()取消。
举个栗子:
示例代码:
#include <stdio.h>
#include <Windows.h>
#pragma pack(2)
struct stinfo
{
char t;
int x;
char y;
double m;
};
#pragma pack()
int main()
{
printf("%d\n", sizeof(stinfo));
while(1);
return 0;
}
如下:
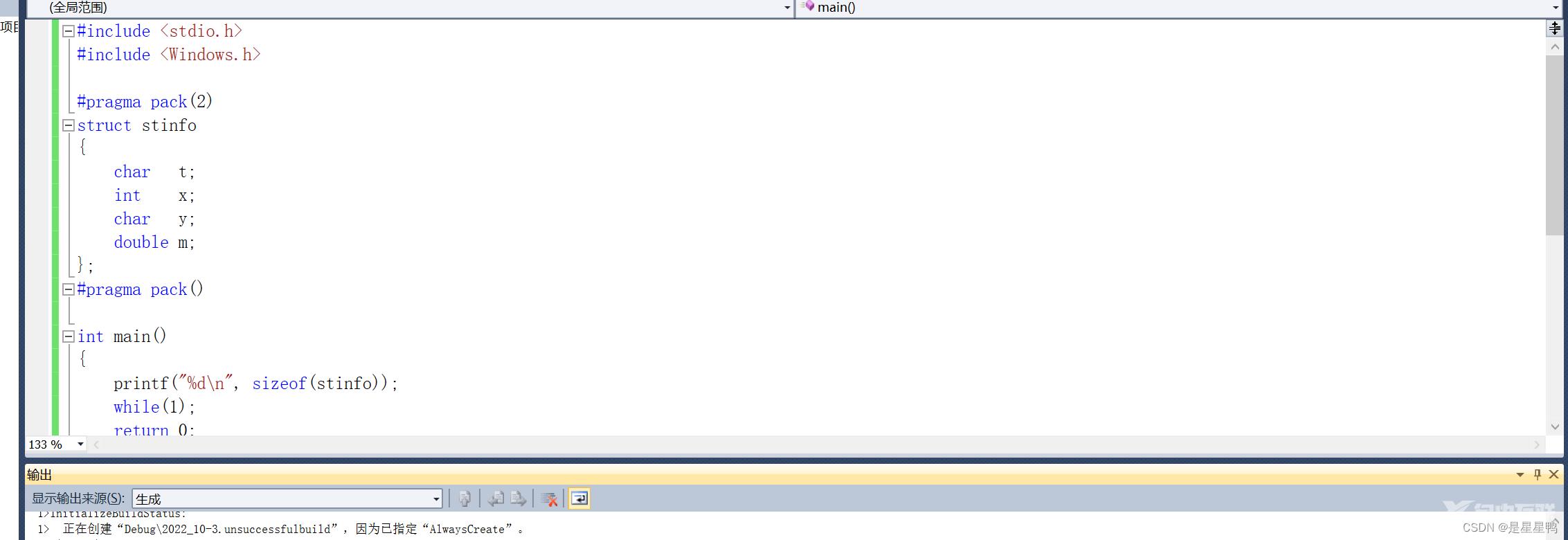
这里我们让结构体以2字节的方式对齐,所以猜想:
char t因为字节对齐的原因起始地址应该是2的整数倍,但是他是首地址,不用管。
t = 1个字节。
int x类型因为pack(2)的原因,起始地址应该是2的整数倍,所以它和chart的差值应该为2,也就是补1个字节。
t+1+x = 6个字节
到这里,t和x已经占有6个字节。
char y因为pack(2)的原因,他的起始地址应该是2的整数倍,但是上面六个字节正好是2的倍数。
t+1+x+y = 7个字节
到这里t、x、y三个成员已经占有7个字节。
double m因为pack(2)的原因,起始地址不得不是2的整数倍,但是上面7个字节显然不对,所以因为字节对齐的原因,上面t、x、y三个成员需要再补一个字节,这个时候加上double的8个字节。
t+1+x+y+1+8 = 16个字节
结果如下:
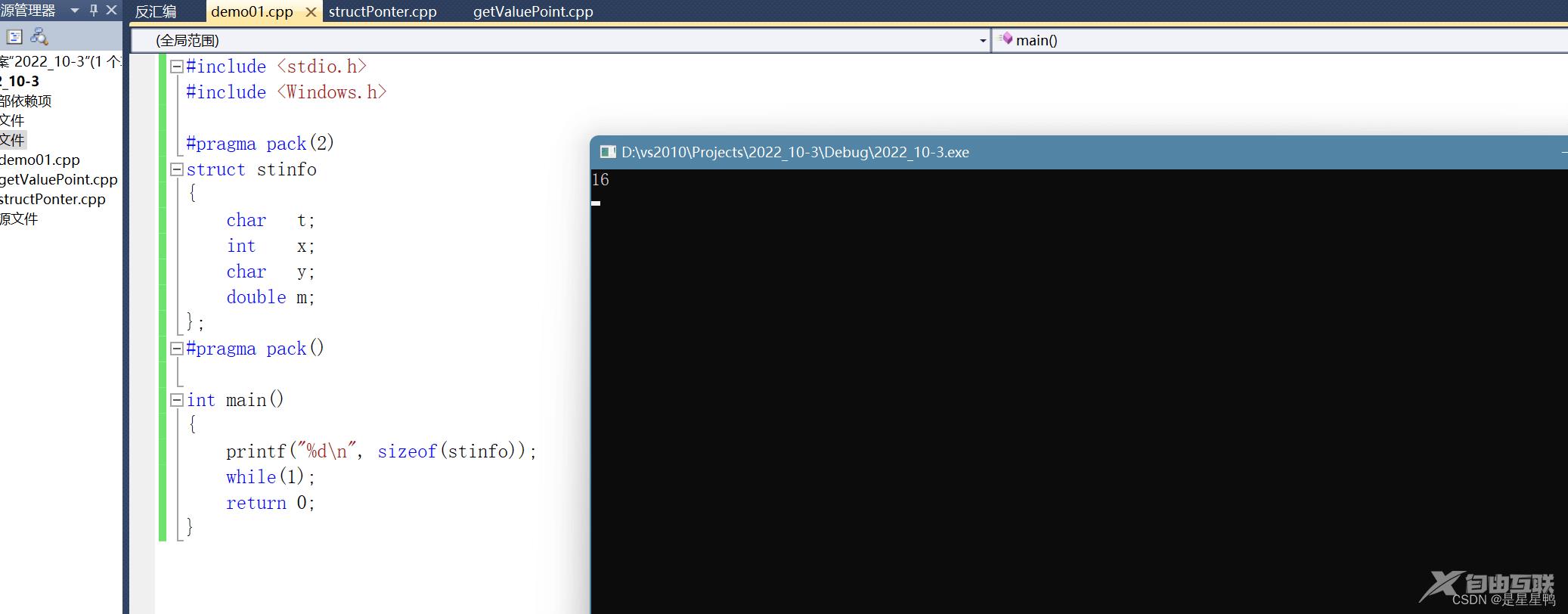
猜想正确。
如果我们不强制字节对齐的话:
char t一个字节
int x起始地址必须是4的整数倍,所以t必须补3个字节
x+t+3 = 8个字节
char y一个字节
x+t+3+y = 9个字节
double m起始地址必须是8的倍数,所以x+t+y需要补7个字节。
x+t+3+y+7+8 = 24个字节
结果如下:

对于pack(1)、pack(4)、pack(8)大家自己尝试下吧。
总结
通过上面的讲解,想必大家应该知道结构体的字节数为什么是成员中最宽数据类型字节数的整数倍了的,但是还是那句话,不要死记这一点,明白为什么才是重点、才能记得更久。
因为字节对齐的原因、结构体中成员的起始地址、假设该成员是int类型,那么它的起始地址必须是4的整数倍,如果是double类型,那么他的起始地址必须是8的整数倍。当然也可以强制他们的起始地址是一个固定数字(1、2、4、8)的整数倍。通过#pragma pack(n)即可。
到此这篇关于C语言结构体字节对齐的实现深入分析的文章就介绍到这了,更多相关C语言结构体字节对齐内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!