目录
- 遗传算法基本思想
- 遗传算法的主要步骤
- 遗传编码
- 二进制编码
- 实数编码
- 遗传算法流程
- 实际演示
遗传算法基本思想
遗传算法(Genetic Algorithm, GA)起源于对生物系统所进行的计算机模拟研究。它是模仿自然界生物进化机制发展起来的随机全局搜索和优化方法,借鉴了达尔文的进化论和孟德尔的遗传学说。其本质是一种高效、并行、全局搜索的方法,能在搜索过程中自动获取和积累有关搜索空间的知识,并自适应地控制搜索过程以求得最佳解。
遗传算法的主要步骤
(1)编码:将问题的候选解用染色体表示,实现解空间向编码空间的映射过程。遗传算法不直接处理解空间的决策变量,而是将其转换成由基因按一定结构组成的染色体。编码方式有很多,如二进制编码、实数向量编码、整数排列编码、通用数据结构编码等等。本文将采用二进制编码的方式,将十进制的变量转换成二进制,用0和1组成的数字串模拟染色体,可以很方便地实现基因交叉、变异等操作。
(2)种群初始化:产生代表问题可能潜在解集的一个初始群体(编码集合)。种群规模设定主要有以下方面的考虑:从群体多样性方面考虑,群体越大越好,避免陷入局部最优;从计算效率方面考虑,群体规模越大将导致计算量的增加。应该根据实际问题确定种群的规模。产生初始化种群的方法通常有两种:一是完全随机的方法产生;二是根据先验知识设定一组必须满足的条件,然后根据这些条件生成初始样本。
(3)计算个体适应度:利用适应度函数计算各个个体的适应度大小。适应度函数(Fitness Function)的选取直接影响到遗传算法的收敛速度以及能否找到最优解,因为在进化搜索中基本不利用外部信息,仅以适应度函数为依据,利用种群每个个体的适应程度来指导搜索。
(4)进化计算:通过选择、交叉、变异,产生出代表新的解集的群体。选择(selection):根据个体适应度大小,按照优胜劣汰的原则,淘汰不合理的个体;交叉(crossover):编码的交叉重组,类似于染色体的交叉重组;变异(mutation):编码按小概率扰动产生的变化,类似于基因突变。
(5)解码:末代种群中的最优个体经过解码实现从编码空间向解空间的映射,可以作为问题的近似最优解。这是整个遗传算法的最后一步,经过若干次的进化过程,种群中适应度最高的个体代表问题的最优解,但这个最优解还是一个由0和1组成的数字串,要将它转换成十进制才能供我们理解和使用。
遗传编码
遗传编码将变量转化为基因组的表示形式,优化变量的编码机制有二进制编码、十进制编码(实数编码)等。
二进制编码
这里简单介绍以下二进制编码的实现原理。例如,求实数区间[0,4]上函数f(x)的最大值,传统的方法是不断调整自变量x的值,假设使用二进制编码新式,我们可以由长度6的未穿表示变量x,即从000000到111111,并将中间的取值映射到实数区间[0,4]内。由于哦才能够整数上来看,6位长度二进制表示范围为0~63,所以对应的[0,4]区间,每个相邻值之间的阶跃值为4/64≈0.00635。这个就是编码的精度,编码精度越高,所得到的解的质量也越高。
实数编码
在解决高维、连续优化问题等是,经常采用实数编码方式。实数编码的优点是计算精度搞,便于和经典连续优化算法结合。
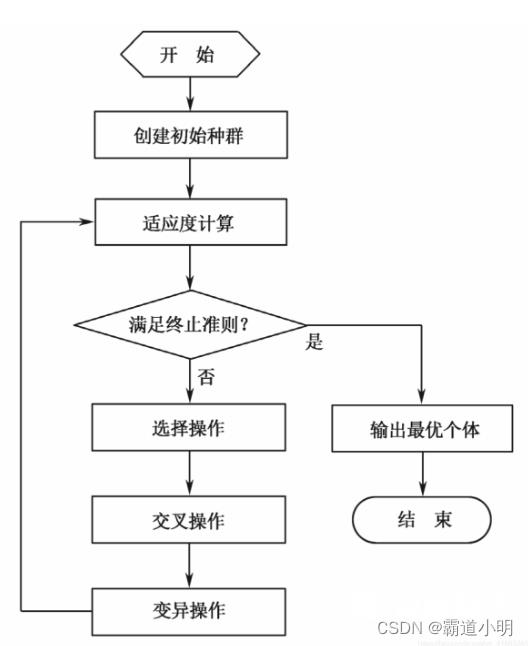
遗传算法流程
1)初始化。设置进化代数计数器g=0,设置最大进化代数G,随机生成NP个个体作为初始群体P(0)
2)个体评价P(t)。计算群体中各个个体的适应度
3)选择运算。将选择算子作用域群体,根据个体适应度,按照一定的规则和方法,选择一些优良个体遗传到下一代群体。
4)交叉运算。将交叉算子作用于群体,对选中的成对个体,以某一概率交换他们之间的部分染色体,产生新的个体
5)变异运算。将变异算子作用于群体,对选中的个体,以某一概率改变某一个或某一些基因值为其他的等位基因。群体P(t)经过选择、交叉、和变异运算之后得到下一代群体P(t+1)。计算其适应度值,并根据适应度值进行排序,准备进行下一代遗传操作。
6)终止条件判断:若g≤G,则g=g+1,转到步骤2);若g>G,则终止计算
实际演示
计算函数
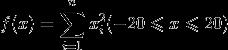
的最小值。这是一个简单的平方和问函数,只有一个极小点,理论最小值f(0,0,...,0)=0
仿真过程如下:
(1)初始化种群数目为NP=100,染色体基因维数D=10,最大进化迭代数G=1000,交叉概率为Pc=0.8,变异概率Pm=0.1
(2)产生初始种群,计算给体适应度值;进行始数编码的安泽以及交叉和变异操作。选择和交叉操作采用“君主方案”,即在对群体根据适应度值高低进行排序的基础上,用最优个体与其他偶数位的所有个体进行交叉,每次交叉产生两个新个体。在交叉过后,对信产所的群体进行多点变异产生子群体,再计算器适应度值,然后和父群体合并,并且根据适应度值进行排序,取前NP个个体为新群体,进行下一次遗传操作。
(3)判断是否满足终止条件:若满足,结束搜索过程,输出最优值;若不满足,继续迭代优化
%%%%%%%%%%%%%%%%%%%%实值遗传算法求函数极值%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%初始化%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
clear all; %清除所有变量
close all; %清图
clc; %清屏
D=10; %基因数目
NP=100; %染色体数目
Xs=20; %上限
Xx=-20; %下限
G=1000; %最大遗传代数
f=zeros(D,NP); %初始种群赋空间
nf=zeros(D,NP); %子种群赋空间
Pc=0.8; %交叉概率
Pm=0.1; %变异概率
f=rand(D,NP)*(Xs-Xx)+Xx; %随机获得初始种群
%%%%%%%%%%%%%%%%%%%%%%按适应度升序排列%%%%%%%%%%%%%%%%%%%%%%%
for np=1:NP
MSLL(np)=func2(f(:,np));
end
[SortMSLL,Index]=sort(MSLL);
Sortf=f(:,Index);
%%%%%%%%%%%%%%%%%%%%%%%遗传算法循环%%%%%%%%%%%%%%%%%%%%%%%%%%
for gen=1:G
%%%%%%%%%%%%%%采用君主方案进行选择交叉操作%%%%%%%%%%%%%%%%
Emper=Sortf(:,1); %君主染色体
NoPoint=round(D*Pc); %每次交叉点的个数
PoPoint=randi([1 D],NoPoint,NP/2); %交叉基因的位置
nf=Sortf;
for i=1:NP/2
nf(:,2*i-1)=Emper;
nf(:,2*i)=Sortf(:,2*i);
for k=1:NoPoint
nf(PoPoint(k,i),2*i-1)=nf(PoPoint(k,i),2*i);
nf(PoPoint(k,i),2*i)=Emper(PoPoint(k,i));
end
end
%%%%%%%%%%%%%%%%%%%%%%%%%%变异操作%%%%%%%%%%%%%%%%%%%%%%%%%
for m=1:NP
for n=1:D
r=rand(1,1);
if r<Pm
nf(n,m)=rand(1,1)*(Xs-Xx)+Xx;
end
end
end
%%%%%%%%%%%%%%%%%%%%%子种群按适应度升序排列%%%%%%%%%%%%%%%%%%
for np=1:NP
NMSLL(np)=func2(nf(:,np));
end
[NSortMSLL,Index]=sort(NMSLL);
NSortf=nf(:,Index);
%%%%%%%%%%%%%%%%%%%%%%%%%产生新种群%%%%%%%%%%%%%%%%%%%%%%%%%%
f1=[Sortf,NSortf]; %子代和父代合并
MSLL1=[SortMSLL,NSortMSLL]; %子代和父代的适应度值合并
[SortMSLL1,Index]=sort(MSLL1); %适应度按升序排列
Sortf1=f1(:,Index); %按适应度排列个体
SortMSLL=SortMSLL1(1:NP); %取前NP个适应度值
Sortf=Sortf1(:,1:NP); %取前NP个个体
trace(gen)=SortMSLL(1); %历代最优适应度值
end
Bestf=Sortf(:,1); %最优个体
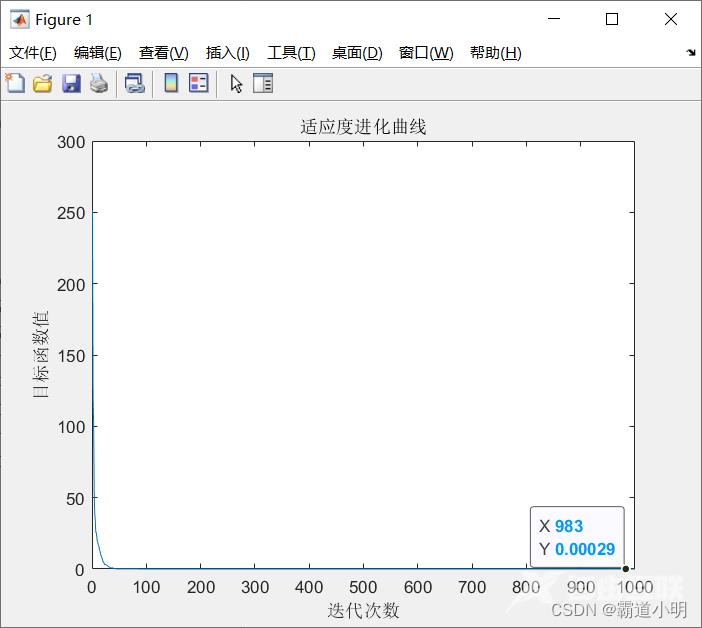
trace(end) %最优值
figure
plot(trace)
xlabel('迭代次数')
ylabel('目标函数值')
title('适应度进化曲线')
%%%%%%%%%%%%%%%%%%%%%%%%%%%适应度函数%%%%%%%%%%%%%%%%%%%%%%%%%%%
function result=func2(x)
summ=sum(x.^2);
result=summ;
end
到此这篇关于Matlab利用遗传算法GA求解非连续函数问题详解的文章就介绍到这了,更多相关Matlab遗传算法求解非连续函数内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!