目录
- xml格式简单介绍
- xml格式解析过程浅析
- 代码实现
- 实现存储解析数据的类——Element
- 关键代码1——实现整体的解析
- 关键代码2——解析所有元素
- 开发技巧
- 有关C++的优化
- 额外注意
xml格式简单介绍
<?xml version="1.0"?>
<!--这是注释-->
<workflow>
<work name="1" switch="on">
<plugin name="echoplugin.so" switch="on" />
</work>
</workflow>
我们来简单观察下上面的xml文件,xml格式和html格式十分类似,一般用于存储需要属性的配置或者需要多个嵌套关系的配置。
xml一般使用于项目的配置文件,相比于其他的ini格式或者yaml格式,它的优势在于可以将一个标签拥有多个属性,比如上述xml文件格式是用于配置工作流的,其中有name属性和switch属性,且再work标签中又嵌套了plugin标签,相比较其他配置文件格式是要灵活很多的。
具体的应用场景有很多,比如使用过Java中Mybatis的同学应该清楚,Mybatis的配置文件就是xml格式,而且也可以通过xml格式进行sql语句的编写,同样Java的maven项目的配置文件也是采用的xml文件进行配置。
而我为什么要写一个xml解析器呢?很明显,我今后要写的C++项目需要用到。
xml格式解析过程浅析
同样回到之前的那段代码,实际上已经把xml文件格式的不同情况都列出来了。
从整体上看,所有的xml标签分为:
- xml声明(包含版本、编码等信息)
- 注释
- xml元素:1.单标签元素。 2.成对标签元素。
其中xml声明和注释都是非必须的。 而xml元素,至少需要一个成对标签元素,而且在最外层有且只能有一个,它作为根元素。
从xml元素来看,分为:
- 名称
- 属性
- 内容
- 子节点
根据之前的例子,很明显,名称是必须要有的而且是唯一的,其他内容则是可选。 根据元素的结束形式,我们把他们分为单标签和双标签元素。
代码实现
完整代码仓库:xml-parser
实现存储解析数据的类——Element
代码如下:
namespace xml
{
using std::vector;
using std::map;
using std::string_view;
using std::string;
class Element
{
public:
using children_t = vector<Element>;
using attrs_t = map<string, string>;
using iterator = vector<Element>::iterator;
using const_iterator = vector<Element>::const_iterator;
string &Name()
{
return m_name;
}
string &Text()
{
return m_text;
}
//迭代器方便遍历子节点
iterator begin()
{
return m_children.begin();
}
[[nodiscard]] const_iterator begin() const
{
return m_children.begin();
}
iterator end()
{
return m_children.end();
}
[[nodiscard]] const_iterator end() const
{
return m_children.end();
}
void push_back(Element const &element)//方便子节点的存入
{
m_children.push_back(element);
}
string &operator[](string const &key) //方便key-value的存取
{
return m_attrs[key];
}
string to_string()
{
return _to_string();
}
private:
string _to_string();
private:
string m_name;
string m_text;
children_t m_children;
attrs_t m_attrs;
};
}
上述代码,我们主要看成员变量。
- 我们用string类型表示元素的name和text
- 用vector嵌套表示孩子节点
- 用map表示key-value对的属性
其余的方法要么是Getter/Setter,要么是方便操作孩子节点和属性。 当然还有一个to_string()方法这个待会讲。
关键代码1——实现整体的解析
关于整体结构我们分解为下面的情形:
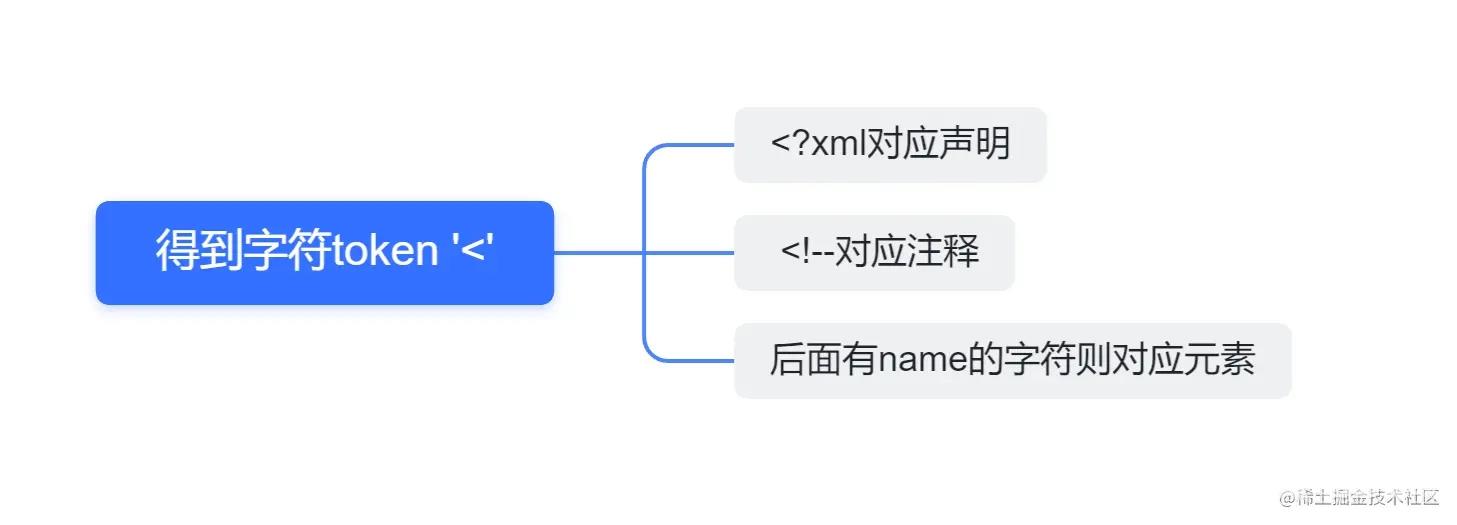
代码如下:
Element xml::Parser::Parse()
{
while (true)
{
char t = _get_next_token();
if (t != '<')
{
THROW_ERROR("invalid format", m_str.substr(m_idx, detail_len));
}
//解析版本号
if (m_idx + 4 < m_str.size() && m_str.compare(m_idx, 5, "<?xml") == 0)
{
if (!_parse_version())
{
THROW_ERROR("version parse error", m_str.substr(m_idx, detail_len));
}
continue;
}
//解析注释
if (m_idx + 3 < m_str.size() && m_str.compare(m_idx, 4, "<!--") == 0)
{
if (!_parse_comment())
{
THROW_ERROR("comment parse error", m_str.substr(m_idx, detail_len));
}
continue;
}
//解析element
if (m_idx + 1 < m_str.size() && (isalpha(m_str[m_idx + 1]) || m_str[m_idx + 1] == '_'))
{
return _parse_element();
}
//出现未定义情况直接抛出异常
THROW_ERROR("error format", m_str.substr(m_idx, detail_len));
}
}
上述代码我们用while循环进行嵌套的原因在于注释可能有多个。
关键代码2——解析所有元素
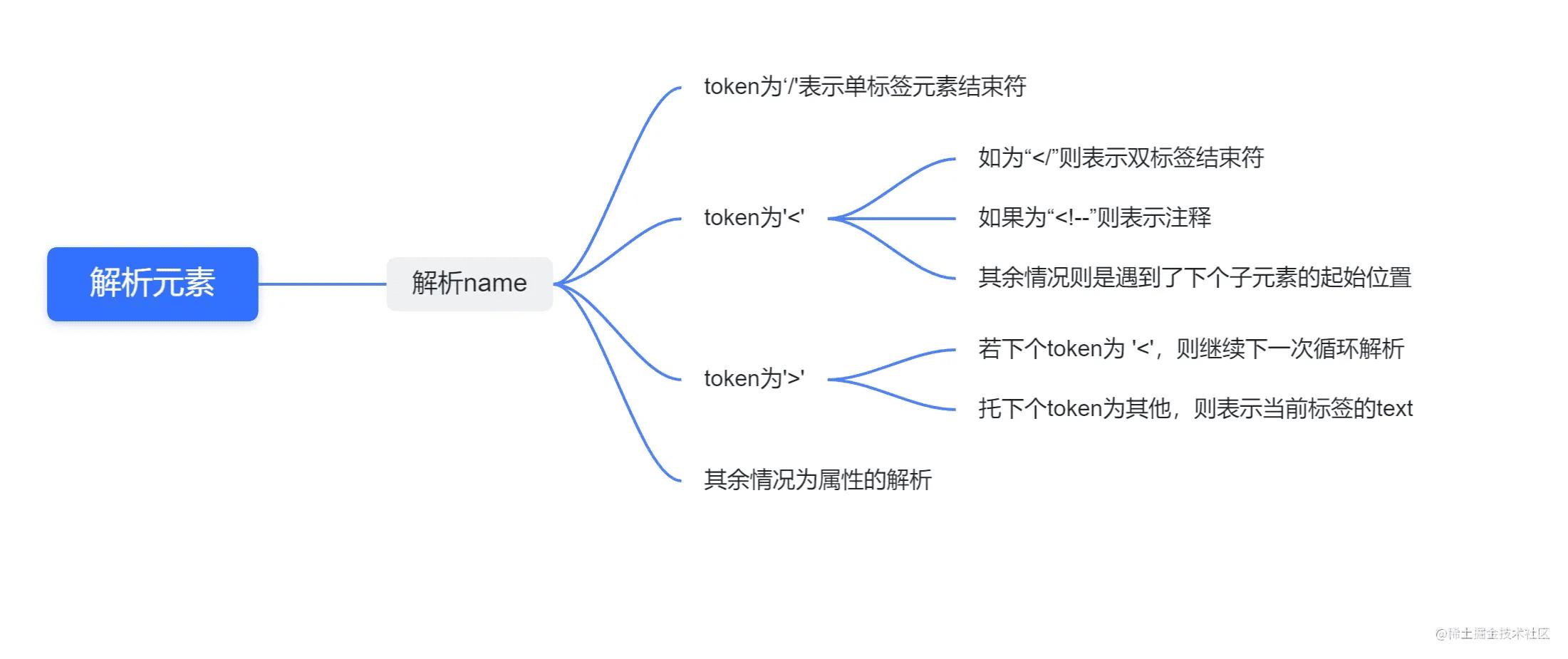
对应代码:
Element xml::Parser::_parse_element()
{
Element element;
auto pre_pos = ++m_idx; //过掉<
//判断name首字符合法性
if (!(m_idx < m_str.size() && (std::isalpha(m_str[m_idx]) || m_str[m_idx] == '_')))
{
THROW_ERROR("error occur in parse name", m_str.substr(m_idx, detail_len));
}
//解析name
while (m_idx < m_str.size() && (isalpha(m_str[m_idx]) || m_str[m_idx] == ':' ||
m_str[m_idx] == '-' || m_str[m_idx] == '_' || m_str[m_idx] == '.'))
{
m_idx++;
}
if (m_idx >= m_str.size())
THROW_ERROR("error occur in parse name", m_str.substr(m_idx, detail_len));
element.Name() = m_str.substr(pre_pos, m_idx - pre_pos);
//正式解析内部
while (m_idx < m_str.size())
{
char token = _get_next_token();
if (token == '/') //1.单元素,直接解析后结束
{
if (m_str[m_idx + 1] == '>')
{
m_idx += 2;
return element;
} else
{
THROW_ERROR("parse single_element failed", m_str.substr(m_idx, detail_len));
}
}
if (token == '<')//2.对应三种情况:结束符、注释、下个子节点
{
//结束符
if (m_str[m_idx + 1] == '/')
{
if (m_str.compare(m_idx + 2, element.Name().size(), element.Name()) != 0)
{
THROW_ERROR("parse end tag error", m_str.substr(m_idx, detail_len));
}
m_idx += 2 + element.Name().size();
char x = _get_next_token();
if (x != '>')
{
THROW_ERROR("parse end tag error", m_str.substr(m_idx, detail_len));
}
m_idx++; //千万注意把 '>' 过掉,防止下次解析被识别为初始的tag结束,实际上这个element已经解析完成
return element;
}
//是注释的情况
if (m_idx + 3 < m_str.size() && m_str.compare(m_idx, 4, "<!--") == 0)
{
if (!_parse_comment())
{
THROW_ERROR("parse comment error", m_str.substr(m_idx, detail_len));
}
continue;
}
//其余情况可能是注释或子元素,直接调用parse进行解析得到即可
element.push_back(Parse());
continue;
}
if (token == '>') //3.对应两种情况:该标签的text内容,下个标签的开始或者注释(直接continue跳到到下次循环即可
{
m_idx++;
//判断下个token是否为text,如果不是则continue
char x = _get_next_token();
if (x == '<')//不可能是结束符,因为xml元素不能为空body,如果直接出现这种情况也有可能是中间夹杂了注释
{
continue;
}
//解析text再解析child
auto pos = m_str.find('<', m_idx);
if (pos == string::npos)
THROW_ERROR("parse text error", m_str.substr(m_idx, detail_len));
element.Text() = m_str.substr(m_idx, pos - m_idx);
m_idx = pos;
//注意:有可能直接碰上结束符,所以需要continue,让element里的逻辑来进行判断
continue;
}
//4.其余情况都为属性的解析
auto key = _parse_attr_key();
auto x = _get_next_token();
if (x != '=')
{
THROW_ERROR("parse attrs error", m_str.substr(m_idx, detail_len));
}
m_idx++;
auto value = _parse_attr_value();
element[key] = value;
}
THROW_ERROR("parse element error", m_str.substr(m_idx, detail_len));
}
开发技巧
无论是C++开发,还是各种其他语言的造轮子,在这个造轮子的过程中,不可能是一帆风顺的,需要不断的debug,然后再测试,然后再debug。。。实际上这类格式的解析,单纯的进行程序的调试效率是非常低下的!
特别是你用的语言还是C++,那么如果出现意外宕机行为,debug几乎是不可能简单的找出原因的,所以为了方便调试,或者是意外宕机行为,我们还是多做一些错误、异常处理的工作比较好。
比如上述的代码中,我们大量的用到了 THROW_ERROR 这个宏,实际上这个宏输出的内容是有便于调试和快速定位的。 具体代码如下:
//用于返回较为详细的错误信息,方便错误追踪
#define THROW_ERROR(error_info, error_detail) \
do{ \
string info = "parse error in "; \
string file_pos = __FILE__; \
file_pos.append(":"); \
file_pos.append(std::to_string(__LINE__));\
info += file_pos; \
info += ", "; \
info += (error_info); \
info += "\ndetail:"; \
info += (error_detail);\
throw std::logic_error(info); \
}while(false)
如果发生错误,这个异常携带的信息如下:

打印出了两个非常关键的信息:
内部的C++代码解析抛出异常的位置
解析发生错误的字符串
按理来说这些信息应该是用日志来进行记录的,但是由于这个项目比较小型,直接用日常信息当日志来方便调试也未尝不可