目录
- 一.协程概述
- 1.概念
- 2.特点
- 3.原理
- 二.协程基础
- 1.协程的上下文
- 2.协程的作用域
- 3.协程调度器
- 4.协程的启动模式
- 5.协程的生命周期
- 三.协程使用
- 1.协程的启动
- 2.协程间通信
- 3.多路复用
- 4.序列生成器
- 5.协程异步流
- 6.全局上下文
一.协程概述
1.概念
协程是Coroutine的中文简称,co表示协同、协作,routine表示程序。协程可以理解为多个互相协作的程序。协程是轻量级的线程,它的轻量体现在启动和切换,协程的启动不需要申请额外的堆栈空间;协程的切换发生在用户态,而非内核态,避免了复杂的系统调用。
2.特点
1)更加轻量级,占用资源更少。
2)避免“回调地狱”,增加代码可读性。
3)协程的挂起不阻塞线程。
3.原理
Kotlin协程原理核心体现在“续体传递”与“状态机”两部分。
1)续体传递
续体传递是一种代码编写风格——续体传递风格(Continuation-Passing-Style),简称为CPS。续体传递本质上是代码的回调与结果的传递。假设将顺序执行代码分成两部分,第一部分执行完成,返回一个结果(可能为空、一个对象引用、一个具体的值)。接着通过回调执行第二部分代码,并传入第一部分代码返回的结果,这种形式的代码编写风格就是续体传递风格。
具体地,假设要计算一个复杂的计算,正常情况会这样编写,代码如下:
fun calculate(a: Int, b: Int): Int = a + b
fun main() {
val result = calculate(1, 2)
Log.d("liduo",result)
}
把上面的代码改造成续体传递风格。首先,定义一个续体传递接口,代码如下:
interface Continuation {
fun next(result: Int)
}
对calculate方法进行改造,代码如下:
fun calculate(a: Int, b: Int, continuation: Continuation) =
continuation.next(a + b)
fun main() {
calculate(1, 2) { result ->
Log.d("liduo", result)
}
}
经过续体传递改造后,打印日志的操作被封装到了Continuation中,并且依赖计算操作的回调。如果continuation方法不回调执行参数continuation,打印日志的操作将永远不会被执行。
原本顺序执行一段代码(逻辑),在经过一次续体改造后变成了两段代码(逻辑)。
2)状态机
协程的代码在经过Kotlin编译器处理时,会被优化成状态机模型。每段代码有三个状态:未执行、挂起、已恢复(完成)。处于未执行状态的代码可以被执行,执行过程中发生挂起,会进入挂起状态,从挂起中恢复或执行完毕会进入已恢复(完成)状态。当多个像这样的代码进行协作时,可以组合出更复杂的状态机。
二.协程基础
1.协程的上下文
协程上下文是一组可以附加到协程中的持久化用户定义对象,代码如下:
interface CoroutineContext {
// 重载"[]"操作
operator fun <E : Element> get(key: Key<E>): E?
// 单值归一化操作
fun <R> fold(initial: R, operation: (R, Element) -> R): R
// 重载 "+"操作
operator fun plus(context: CoroutineContext): CoroutineContext
// 获取当前指定key外的其他上下文
fun minusKey(key: Key<*>): CoroutineContext
interface Element : CoroutineContext {
val key: Key<*>
}
interface Key<E : Element>
}
Element接口继承自CoroutineContext接口,协程中的拦截器、调度器、异常处理器以及代表协程自身生命周期等重要的类,都实现了Element接口。
Element接口规定每个实现该接口的对象都要有一个独一无二的Key,以便在需要的时候可以在协程上下文中快速的找到。因此,协程上下文可以理解为是一个Element的索引集,一个结构介于Set和Map之间的索引集。
2.协程的作用域
协程作用域用于管理作用域内协程的生命周期,代码如下:
interface CoroutineScope {
// 作用域内启动协程的默认上下文
val coroutineContext: CoroutineContext
}
协程中提供了两个常用的方法来创建新的协程作用域,一个是coroutineScope方法,一个是supervisorScope方法,这两种方法创建的作用域中的上下文会自动继承父协程的上下文。除此之外,使用GlobalScope启动协程,也会为协程创建一个新的协程作用域,但协程作用域的上下文为空上下文。
当父协程被取消或发生异常时,会自动取消父协程所有的子协程。当子协程取消或发生异常时,在coroutineScope作用域下,会导致父协程取消;而在supervisorScope作用域下,则不会影响父协程。
协程的作用域只对父子协程有效,对子孙协程无效。例如:启动父协程,在supervisorScope作用域内启动子协程。当子协程在启动孙协程时,在不指定为supervisorScope作用域的情况下,默认为coroutineScope作用域。
3.协程调度器
协程调度器用于切换执行协程的线程。常见的调度器有以下4种:
- Dispatchers.Default:默认调度器。它使用JVM的共享线程池,该调度器的最大并发度是CPU的核心数,默认为2。
- Dispatchers.Unconfined:非受限调度器。该调度器不会限制代码在指定的线程上执行。即挂起函数后面的代码不会主动恢复到挂起之前的线程去执行,而是在执行挂起函数的线程上执行。
- Dispatchers.IO:IO调度器。它将阻塞的IO任务分流到一个共享的线程池中。该调度器和Dispatchers.Default共享线程。
- Dispatchers.Main:主线程调度器。一般用于操作与更新UI。
注意:Dispatchers.Default调度器和Dispatchers.IO 调度器分配的线程为守护线程。
4.协程的启动模式
协程共有以下四种启动模式:
- CoroutineStart.DEFAULT:立即执行协程,可以随时取消。
- CoroutineStart.LAZY:创建一个协程,但不执行,在用户需要时手动触发执行。
- CoroutineStart.ATOMIC:立即执行协程,但在协程执行前无法取消。目前处于试验阶段。
- CoroutineStart.UNDISPATCHED:立即在当前线程执行协程,直到遇到第一个挂起。目前处于试验阶段。
5.协程的生命周期
每个协程在创建后都会返回一个Job接口指向的对象,一个Job对象代表一个协程,用于控制生命周期,代码如下:
interface Job : CoroutineContext.Element {
...
// 三个状态标志
val isActive: Boolean
val isCompleted: Boolean
val isCancelled: Boolean
// 获取具体的取消异常
fun getCancellationException(): CancellationException
// 启动协程
fun start(): Boolean
// 取消协程
fun cancel(cause: CancellationException? = null)
...
// 等待协程执行结束
suspend fun join()
// 用于select语句
val onJoin: SelectClause0
// 用于注册协程执行结束的回调
fun invokeOnCompletion(handler: CompletionHandler): DisposableHandle
...
}
1)协程状态的转换
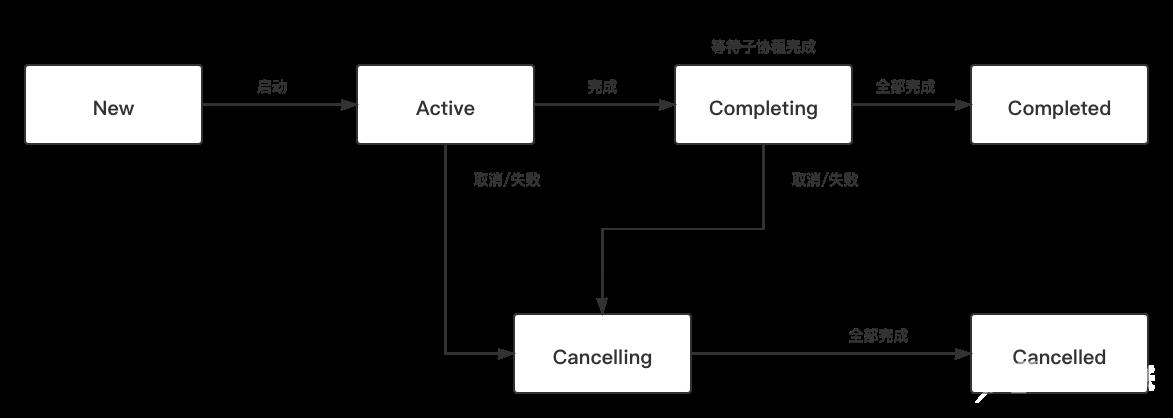
在DEFAULT、ATOMIC、UNDISPATCHED这三个模式下,启动协程会进入Active状态,而在LAZY模式下启动的协程会进入New状态,需要在手动调用start方法后进入Active状态。
Completing是一个内部状态,对外不可感知。
2)状态标识的变化
三.协程使用
1.协程的启动
1)runBlocking方法
fun <T> runBlocking(context: CoroutineContext = EmptyCoroutineContext, block: suspend CoroutineScope.() -> T): T
该方法用于在非协程作用域环境中启动一个协程,并在这个协程中执行lambda表达式中的代码。同时,调用该方法会阻塞当前线程,直到lambda表达式执行完毕。该方法不应该在协程中被调用,该方法设计的目的是为了让suspend编写的代码可以在常规的阻塞代码中调用。如果不设置协程调度器,那么协程将在当前被阻塞的线程中执行。示例代码如下:
private fun main() {
// 不指定调度器,在方法调用的线程执行
runBlocking {
// 这里是协程的作用域
Log.d("liduo", "123")
}
}
private fun main() {
// 指定调度器,在IO线程中执行
runBlocking(Dispatchers.IO) {
// 这里是协程的作用域
Log.d("liduo", "123")
}
}
2)launch方法
fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job
该方法用于在协程作用域中异步启动一个新的协程,调用该方法不会阻塞线程。示例代码如下:
private fun test() {
// 作用域为GlobalScope
// 懒启动,主线程执行
val job = GlobalScope.launch(
context = Dispatchers.Main,
start = CoroutineStart.LAZY) {
Log.d("liduo", "123")
}
// 启动协程
job.start()
}
3)async方法
fun <T> CoroutineScope.async(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> T
): Deferred<T>
该方法用于在协程作用域中中异步启动一个新的协程,调用该方法不会阻塞线程。async方法与launch方法的不同之处在于可以携带返回值。调用该方法会返回一个Deferred接口指向的对象,调用该对象可以获取协程执行的结果。同时,Deferred接口继承自Job接口,因此仍然可以操作协程的生命周期。示例代码如下:
// suspend标记
private suspend fun test(): Int {
// 作用域为GlobalScope,返回值为Int类型,,泛型可省略,自动推断
val deffer = GlobalScope.async<Int> {
Log.d("liduo", "123")
// 延时1s
delay(1000)
1
}
// 获取返回值
return deffer.await()
}
通过调用返回的Deferred接口指向对象的await方法可以获取返回值。在调用await方法时,如果协程执行完毕,则直接获取返回值。如果协程还在执行,则该方法会导致协程挂起,直到执行结束或发生异常。
4)suspend关键字
suspend关键字用于修饰一个方法(lambda表达式)。suspend修饰的方法称为suspend方法,表示方法在执行中可能发生挂起。为什么是可能呢?比如下面的代码虽然被suspend修饰,但实际并不会发生挂起:
private suspend fun test() {
Log.d("liduo", "123")
}
由于会发生挂起,因此suspend方法只能在协程中使用。suspend方法内部可以调用其他的suspend方法,也可以非suspend方法。但suspend方法只能被其他的suspend方法调用。
5)withContext方法
suspend fun <T> withContext(
context: CoroutineContext,
block: suspend CoroutineScope.() -> T
): T
该方法用于在当前协程的执行过程中,切换到调度器指定的线程去执行参数block中的代码,并返回一个结果。调用该方法可能会使当前协程挂起,并在方法执行结束时恢复挂起。示例代码如下:
private suspend fun test() {
// IO线程启动并执行,启动模式DEFAULT
GlobalScope.launch(Dispatchers.IO) {
Log.d("liduo", "start")
// 线程主切换并挂起,泛型可省略,自动推断
val result = withContext<String>(Dispatchers.Main) {
// 网络请求
"json data"
}
// 切换回IO线程
Log.d("liduo", result)
}
}
6)suspend方法
inline fun <R> suspend(noinline block: suspend () -> R): suspend () -> R = block
该方法用于对挂起方法进行包裹,使挂起方法可以在非挂起方法中调用。该方法需要配合createCoroutine方法启动协程。示例代码如下:
// 返回包含当前的协程代码的续体
val continuation = suspend {
// 执行协程代码
// 泛型可以修改需要的类型
}.createCoroutine(object : Continuation<Any> {
override val context: CoroutineContext
get() = EmptyCoroutineContext + Dispatchers.Main
override fun resumeWith(result: Result<Any>) {
// 获取最终结果
}
})
// 执行续体内容
continuation.resume(Unit)
一般开发中不会通过该方法启动协程,但该方法可以更本质的展示协程的启动、恢复、挂起。
2.协程间通信
1)Channel
Channel用于协程间的通信。Channel本质上是一个并发安全的队列,类似BlockingQueue。在使用时,通过调用同一个Channel对象的send和receive方法实现通信,示例代码如下:
suspend fun main() {
// 创建
val channel = Channel<Int>()
val producer = GlobalScope.launch {
var i = 0
while (true){
// 发送
channel.send(i++)
delay(1000)
// channel不需要时要及时关闭
if(i == 10)
channel.close()
}
}
// 写法1:常规
val consumer = GlobalScope.launch {
while(true){
// 接收
val element = channel.receive()
Log.d("liduo", "$element")
}
}
// 写法2:迭代器
val consumer = GlobalScope.launch {
val iterator = channel.iterator()
while(iterator.hasNext()){
// 接收
val element = iterator.next()
Log.d("liduo", "$element")
}
}
// 写法3:增强for循环
val consumer = GlobalScope.launch {
for(element in channel){
Log.d("liduo", "$element")
}
}
// 上面的协程由于不是懒启动,因此创建完成直接就会start去执行
// 也就是说,代码走到这里,上面的两个协程已经开始工作
// join方法会挂起当前协程,而不是上面已经启动的两个协程
// 在Android环境中,下面两行代码可以不用添加
// producer.join()
// consumer.join()
}
上述例子是一个经典的生产者-消费者模型。在写法1中,由于send方法和receive方法被suspend关键字修饰,因此,在默认情况下,当生产速度与消费速度不匹配时,调用这两个方法会导致协程挂起。
除此之外,Channel支持使用迭代器进行接收。其中,hasNext方法也可能会导致协程挂起。
Channel对象在不使用时要及时关闭,可以由发送者关闭,也可以由接收者关闭,具体取决于业务场景。
2)Channel的容量
Channel方法不是Channel的构造方法,而是一个工厂方法,代码如下:
fun <E> Channel(capacity: Int = RENDEZVOUS): Channel<E> =
when (capacity) {
RENDEZVOUS -> RendezvousChannel()
UNLIMITED -> LinkedListChannel()
CONFLATED -> ConflatedChannel()
BUFFERED -> ArrayChannel(CHANNEL_DEFAULT_CAPACITY)
else -> ArrayChannel(capacity)
}
在创建Channel时可以指定容量:
- RENDEZVOUS:创建一个容量为0的Channel,类似于SynchronousQueue。send之后会挂起,直到被receive。枚举值为0。
- UNLIMITED:创建一个容量无限的Channel,内部通过链表实现。枚举值为Int.MAX_VALUE。
- CONFLATED:创建一个容量为1的Channel,当后一个的数据会覆盖前一个数据。枚举值为-1。
- BUFFERED:创建一个默认容量的Channel,默认容量为kotlinx.coroutines.channels.defaultBuffer配置变量指定的值,未配置情况下,默认为64。枚举值为-2。
- 如果capacity的值不为上述的枚举值,则创建一个指定容量的Channel。
3)produce方法与actor方法
fun <E> CoroutineScope.produce(
context: CoroutineContext = EmptyCoroutineContext,
capacity: Int = 0,
@BuilderInference block: suspend ProducerScope<E>.() -> Unit
): ReceiveChannel<E>
fun <E> CoroutineScope.actor(
context: CoroutineContext = EmptyCoroutineContext,
capacity: Int = 0,
start: CoroutineStart = CoroutineStart.DEFAULT,
onCompletion: CompletionHandler? = null,
block: suspend ActorScope<E>.() -> Unit
): SendChannel<E>
与launch方法和async方法相同,使用produce方法与actor方法也可以启动协程。但不同的是,在produce方法与actor方法中可以更简洁的使用Channel。示例代码如下:
// 启动协程,返回一个接收Channel
val receiveChannel: ReceiveChannel<Int> = GlobalScope.produce {
while(true){
delay(100)
// 发送
send(1)
}
}
// 启动协程,返回一个发送Channel
val sendChannel: SendChannel<Int> = GlobalScope.actor<Int> {
while(true){
// 接收
val element = receive()
Log.d("liduo","$element")
}
}
produce方法与actor方法内部对Channel对象做了处理,当协程执行完毕,自动关闭Channel对象。
但目前,produce方法还处于试验阶段(被ExperimentalCoroutinesApi注解修饰)。而actor方法也已经过时(被ObsoleteCoroutinesApi注解修饰)。因此在实际开发中最好不要使用!
4)BroadcastChannel
当遇到一个发送者对应多个接收者的场景时,可以使用BroadcastChannel。代码如下:
fun <E> BroadcastChannel(capacity: Int): BroadcastChannel<E> =
when (capacity) {
0 -> throw IllegalArgumentException("Unsupported 0 capacity for BroadcastChannel")
UNLIMITED -> throw IllegalArgumentException("Unsupported UNLIMITED capacity for BroadcastChannel")
CONFLATED -> ConflatedBroadcastChannel()
BUFFERED -> ArrayBroadcastChannel(CHANNEL_DEFAULT_CAPACITY)
else -> ArrayBroadcastChannel(capacity)
}
创建BroadcastChannel对象时,必须指定容量大小。接收者通过调用BroadcastChannel对象的openSubscription方法,获取ReceiveChannel对象来接收消息。示例代码如下:
// 创建BroadcastChannel,容量为5
val broadcastChannel = BroadcastChannel<Int>(5)
// 创建发送者协程
GlobalScope.launch {
// 发送 1
broadcastChannel.send(1)
delay(100)
// 发送 2
broadcastChannel.send(2)
// 关闭
broadcastChannel.close()
}.join()
// 创建接收者1协程
GlobalScope.launch {
// 获取ReceiveChannel
val receiveChannel = broadcastChannel.openSubscription()
// 接收
for (element in receiveChannel) {
Log.d("receiver_1: ", "$element")
}
}.join()
// 创建接收者2协程
GlobalScope.launch {
// 获取ReceiveChannel
val receiveChannel = broadcastChannel.openSubscription()
// 接收
for (element in receiveChannel) {
Log.d("receiver_2: ", "$element")
}
}.join()
每个接收者都可以收到发送者发送的每一条消息。使用扩展方法broadcast可以直接将Channel对象转化为BroadcastChannel对象,示例代码如下:
val channel = Channel<Int>() val broadcastChannel = channel.broadcast(10)
BroadcastChannel的很多方法也处于试验阶段(被ExperimentalCoroutinesApi注解修饰),使用时需慎重!
3.多路复用
协程中提供了类似Java中Nio的select方法,用于多路复用,代码如下:
suspend inline fun <R> select(crossinline builder: SelectBuilder<R>.() -> Unit): R
以Channel的多路复用为例,具体看一下select方法的使用。示例代码如下:
private suspend fun test() {
// 创建一个Channel列表
val channelList = mutableListOf<Channel<Int>>()
// 假设其中有5个Channel
channelList.add(Channel())
channelList.add(Channel())
channelList.add(Channel())
channelList.add(Channel())
channelList.add(Channel())
// 调用select方法,协程挂起
val result = select<Int> {
// 对5个Channel进行注册监听,等待接收
channelList.forEach {
it.onReceive
}
}
// 当5个Channel中任意一个接收到消息时,select挂起恢复
// 并将返回值赋给result
Log.d("liduo", "$result")
}
除此之外,协程中还有很多接口定义了名字为"onXXX"的方法,比如Job接口的onJoin方法,Deferred接口的onAwait方法,都是用于配合select方法来进行多路复用。
4.序列生成器
协程中提供了sequence方法来生成序列。示例代码如下:
private suspend fun test() {
// 创建一个可以输出奇数的序列,泛型可省略,自动推断
val singleNumber = sequence<Int> {
val i = 0
while (true) {
// 在需要输出的地方调用yield方法
yield(2 * i - 1)
}
}
// 调用迭代器,获取序列的输出
singleNumber.iterator().forEach {
Log.d("liduo", "$it")
}
// 获取序列前五项,迭代输出
singleNumber.take(5).forEach {
Log.d("liduo", "$it")
}
}
调用yield方法会使协程挂起,同时输出这个序列当前生成的值。除此之外,也可以调用yieldAll方法来输出序列产生值的合集,示例代码如下:
private suspend fun test() {
// 创建一个可以输出奇数的序列,泛型可省略,自动推断
val singleNumber = sequence<Int> {
yieldAll(listOf(1,3,5,7))
yieldAll(listOf(9,11,13))
yieldAll(listOf(15,17))
}
// 调用迭代器,获取序列的输出,最多为9项
singleNumber.iterator().forEach {
Log.d("liduo", "$it")
}
// 获取序列前五项,迭代输出
singleNumber.take(5).forEach {
// 1,3,5,7,9
Log.d("liduo", "$it")
}
}
5.协程异步流
协程中提供了类似RxJava的响应式编程API——Flow(官方称为异步冷数据流,官方也提供了创建热数据流的方法)。
1)基础使用
// 在主线程上调用
GlobalScope.launch(Dispatchers.Main) {
// 创建流
flow<Int> {
// 挂起,输出返回值
emit(1)
// 设置流执行的线程,并消费流
}.flowOn(Dispatchers.IO).collect {
Log.d("liduo", "$it")
}
}.join()
emit方法是一个挂起方法,类似sequence中的yield方法,用于输出返回值。flowOn方法等同于Rxjava中的subscribeOn方法,用于切换flow执行的线程。为了避免理解混淆,Flow中没有提供类似Rxjava中的observeOn方法,但可以通过指定流所在协程的上下文参数确定。collect方法等同于RxJava中的subscribe方法,用于触发和消费流。
一个流可以被多次消费,示例代码如下:
GlobalScope.launch(Dispatchers.IO) {
val mFlow = flow<Int> {
emit(1)
}.flowOn(Dispatchers.Main)
mFlow.collect { Log.d("liduo1", "$it") }
mFlow.collect { Log.d("liduo2", "$it") }
}.join()
2)异常处理
Flow支持类似try-catch-finally的异常处理。示例代码如下:
flow<Int> {
emit(1)
// 抛出异常
throw NullPointerException()
}.catch { cause: Throwable ->
Log.d("liduo", "${cause.message}")
}.onCompletion { cause: Throwable? ->
Log.d("liduo", "${cause?.message}")
}
catch方法用于捕获异常。onCompletion方法等同于finally代码块。Kotlin不建议直接在flow中通过try-catch-finally代码块去捕获异常!
Flow中还提供了类似RxJava的onErrorReturn方法的操作,示例代码如下:
flow<Int> {
emit(1)
// 抛出异常
throw NullPointerException()
}.catch { cause: Throwable ->
Log.d("liduo", "${cause.message}")
emit(-1)
}
3)触发分离
Flow支持提前写好流的消费,在必要的时候再去触发消费的操作。示例代码如下:
// 创建Flow的方法
fun myFlow() = flow<Int> {
// 生产过程
emit(1)
}.onEach {
// 消费过程
Log.d("liduo", "$it")
}
suspend fun main() {
// 写法1
GlobalScope.launch {
// 触发消费
myFlow().collect()
}.join()
// 写法2
myFlow().launchIn(GlobalScope).join()
}
4)注意
- Flow中不提供取消collect的方法。如果要取消flow的执行,可以直接取消flow所在的协程。
- emit方法不是线程安全的,因此不要在flow中调用withContext等方法切换调度器。如果需要切换,可以使用channelFlow。
6.全局上下文
在本文中,启动协程使用的都是GlobalScope,但在实际开发过程中,不应该使用GlobalScope。GlobalScope会开启一个全新的协程作用域,并且不受我们控制。假设Activity页面关闭时,其中的协程还没有运行结束,并且我们还无法取消协程的执行,这时可能会导致内存泄漏。因此,在实际开发中,可以自定义一个全局的协程作用域,或者至少按照以下方法书写代码:
// 实现CoroutineScope接口
class MainActivity : AppCompatActivity(),CoroutineScope by MainScope() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
// 直接启动协程
launch {
Log.d("liduo", "launch")
}
}
override fun onDestroy() {
super.onDestroy()
// 取消顶级父协程
cancel()
}
}
MainScope的代码如下:
public fun MainScope(): CoroutineScope = ContextScope(SupervisorJob() + Dispatchers.Main)
Dispatchers.Main表示在主线程调度,SupervisorJob()表示子协程取消不会影响父协程。
到此这篇关于Kotlin协程概念原理与使用万字梳理的文章就介绍到这了,更多相关Kotlin协程内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!