目录 c++的字节序与符号位 c++多字节值与字节序 多字节值与字节序 对于跨平台应用,字节序的两种处理方式 字节序的判断 整数字节序的转换 浮点数的字节序转换 c++的字节序与符号位
目录
- c++的字节序与符号位
- c++多字节值与字节序
- 多字节值与字节序
- 对于跨平台应用,字节序的两种处理方式
- 字节序的判断
- 整数字节序的转换
- 浮点数的字节序转换
c++的字节序与符号位
看这样一道题:
#include <stdio.h>
int main(void)
{
int w, h;
int i = 0xa1b2c3d4;
char *p = (char *)&i;
for (int j = 0; j < 4; j++)
{
char c = p[j];
printf("%02x\n", c);
}
return 0;
}
输出结果是什么?
ffffffd4
ffffffc3
ffffffb2
ffffffa1
char只有一个字节,打印出来却是4个字节,与想象的不一样啊,
如果改动一下就对了,
#include <stdio.h>
int main(void)
{
int w, h;
int i = 0xa1b2c3d4;
unsigned char *p = (unsigned char *)&i;
for (int j = 0; j < 4; j++)
{
unsigned char c = p[j];
printf("%02x\n", c);
}
return 0;
}
d4
c3
b2
a1
这是因为:
1)在x86平台是littelEndian字节序,所以会倒序,先遍历到低位;
2)char 类型等于是有符号,在打印时候,会将高位按照符号位补全1,所以会打印多余的FF,这里与printf的实现有关
c++多字节值与字节序
多字节值与字节序
大于8位(一字节)的值称为多字节量,在内存中存储多字节量有两种方式:
小端:处理器储存多字节值的最低有效字节于较低的内存位置,则该微处理器就是小端处理器;
大端:微处理器储存多字节值的最高有效字节于较低的内存位置,则该处理器为大端处理器。
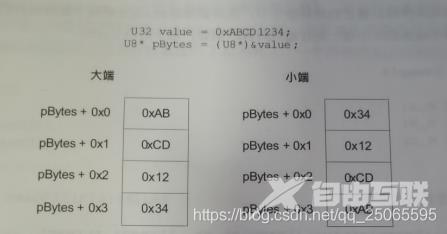
对于跨平台应用,字节序的两种处理方式
- 所有数据以文字的方式写入文件;多字节数值以一串十进制数字,每个数字一个的写入,这会浪费磁盘空间。
- 工具先转换字节序,然后再把转换后的数据写进二进制文件。
字节序的判断
/*
*返回1小端
*返回0是大端
*/
int check_sys()
{
int i = 1;
return ((char)&i);
}
整数字节序的转换
typedef unsigned short U16;
typedef unsigned int U32;
U16 swapU16(U16 value)
{
return ((value & 0xFF00) >> 8 ) | ( (value & 0x00FF) << 8 );
}
U32 swapU32(U32 value)
{
return ( (value & 0x000000FF) << 24 )
| ( (value & 0x0000FF00) << 8 )
| ( (value & 0x00FF0000) >> 8 )
| ( (value & 0xFF000000) >> 24 );
}
浮点数的字节序转换
虽然浮点数有详细的内部结构,其中某些位作为尾数,有些位作为指数,并还有一个符号位,虽然其结构复杂,但仍然可以把浮点数当作整数转成字节序:
typedef unsigned short U16;
typedef unsigned int U32;
typedef float F32;
union U32F32
{
U32 m_asU32;
F32 m_asF32;
};
U32 swapU32(U32 value)
{
return ( (value & 0x000000FF) << 24 )
| ( (value & 0x0000FF00) << 8 )
| ( (value & 0x00FF0000) >> 8 )
| ( (value & 0xFF000000) >> 24 );
}
F32 swapF32(F32 value)
{
U32F32 u;
u.m_asF32 = value;
u.m_asU32 = swapU32(u.m_asU32);
return u.m_asF32;
}
以上为个人经验,希望能给大家一个参考,也希望大家多多支持自由互联。