Linux网络虚拟化
1. Linux网络常见概念与操作
1.1 NameSpace 定义
简单理解namespace
namespace是Linux上的网络隔离技术的名称。其实无论是Linux网络中还是其它的网络中,网络隔离的技术是相通的,例如我们二层网络中的VLAN技术一样,在不同的场景下,只是它们的名称不同;
定义
Linux系统,处于不同命名空间的网络栈是完全隔离的,彼此之间无法通信。通过网络的隔离,就能在单个宿主机虚拟多个不同的网络环境。 Docker正式利用了网络的命名空间特性,实现了不同容器之间网络隔离
特点
- 在Linux的网络命名空间中可以有自己独立的路由表以及独立的iptables设置来提供包转发,NAT及IP包过滤等功能。
- 网络设备也必须属于某个NS,但可以修改属性在不同NS之间移动;是否允许移动和设备的特征有关
- namespace是内核提供的一种空间隔离,在一个空间下,每个进程看到的视图是一致的。例如两个进程在同一个网络命名空间中看到的网络信息(网卡、IP、路由等)是一样的。
1.2 NameSpace 资源隔离
- 不同进程之间使用资源隔离
Docker和虚拟机技术一样,从操作系统级别实现了资源的隔离,它本质是宿主机上的进程,所以资源隔离主要就是指进程资源的隔离。实现资源隔离的核心技术就是Linux namespace。
- 隔离意味着可以抽象出多个轻量级的内核(容器进程),这些进程可以充分利用宿主机的资源,宿主机有的资源容器进程都可以享有,但彼此之间是隔离的。
Linux namespace实现了6项资源隔离,主要包括主机名、用户权限、文件系统、网络、进程号、进程间通信。新版本加入了Cgroup和Time。
Cgroups提供了对一组进程及将来子进程的资源限制、控制和统计能力
1.3 NameSpace 实现
- 在新生成的命名空间中只有回环设备(名为“lo”且是停止的状态),其它设备都是不存在的,如果需要,需要手动进程创建
注意:对于NameSpace的实现内核中的实现就不多说了哈哈,还太菜实力不允许;有兴趣的伙伴可以去看看底层的实现逻辑
1.4 NameSpace 操作
基本命令
[root@k8s ~]# ip netns add test1 # 新增一个namespace[root@k8s ~]# ip netns list # 查看namespace,系统默认的不会显示test1ip netns exec ns-name command # 查看namespace中的某些信息ip netns exec ~ bash # 进入空间[root@k8s ~]# ip netns exec test1 sh # 选择进入shsh-4.2#
查看哪些设备可以移动NS,查询为on表示不能移动NS
root@Kubernetes:~# ethtool -k docker0 | grep netnsnetns-local: on [fixed]由于网络命名空间代表的是一个独立的协议栈,所以它们之间是相互隔离的,彼此无法通信,协议栈内部是无法看到对方的。问题来了,能否让处于不同命名空间的网络互相通信,甚至和外部的网络通信呢?是有的,namespace之间通信使用的是Veth设备对。
2. Veth设备对&网络虚拟化技术
2.1 Veth设备对
用途
- 将两个namespace连接起来,让其通信
- 都是成对出现,一端为另一端的peer。模拟网卡直连
注意:容器中的eth0接口实际就是veth设备对,只是Docker的实现里将名称默认修改为了eth0,它可不是本地网卡

Veth设备操作命令
- ip link veth0 type veth peer name veth1 #添加veth网卡对
- ip link show(查看所有网络接口)
分配IP地址
- ip netns exxec nsname ip addr add ~ deve veth1
- ip addr addd ~ dev eht0
启动
- ip netns exec nsname ip link set dev veth1 up
- ip link set dev veth0 up
2.2 Veth设备对测试案例
[root@k8s ~]# ip link add veth0 type veth peer name veth1[root@k8s ~]# ip link show1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:002: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 00:0c:29:06:ef:fb brd ff:ff:ff:ff:ff:ff3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default link/ether 02:42:76:f9:f3:f7 brd ff:ff:ff:ff:ff:ff4: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 72:be:70:2b:9a:59 brd ff:ff:ff:ff:ff:ff5: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 9e:10:51:1d:89:f6 brd ff:ff:ff:ff:ff:ff
Veth1加入名称为Aurora的NS
这时会发现查看出的结果中没有Veth1设备
[root@k8s ~]# ip link set veth1 netns Aurora[root@k8s ~]# ip link show1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:002: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 00:0c:29:06:ef:fb brd ff:ff:ff:ff:ff:ff3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default link/ether 02:42:76:f9:f3:f7 brd ff:ff:ff:ff:ff:ff5: veth0@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 9e:10:51:1d:89:f6 brd ff:ff:ff:ff:ff:ff link-netnsid 0
查看Aurora命名的NS空间设备信息
[root@k8s ~]# ip netns exec Aurora ip link show1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:004: veth1@if5: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 72:be:70:2b:9a:59 brd ff:ff:ff:ff:ff:ff link-netnsid 0
分配IP地址
[root@k8s ~]# ip netns exec Aurora ip addr add 10.1.1.1/24 dev veth1[root@k8s ~]# ip addr add 10.1.1.2/24 dev veth0启动veth1
[root@k8s ~]# ip netns exec Aurora ip link set dev veth1 up[root@k8s ~]# ip netns exec Aurora ip link show1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:004: veth1@if5: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state LOWERLAYERDOWN mode DEFAULT group default qlen 1000 link/ether 72:be:70:2b:9a:59 brd ff:ff:ff:ff:ff:ff link-netnsid 0
启动veth0
[root@k8s ~]# ip link set dev veth0 up [root@k8s ~]# ip link show1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:002: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 00:0c:29:06:ef:fb brd ff:ff:ff:ff:ff:ff3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default link/ether 02:42:76:f9:f3:f7 brd ff:ff:ff:ff:ff:ff5: veth0@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether 9e:10:51:1d:89:f6 brd ff:ff:ff:ff:ff:ff link-netnsid 0测试连通性
[root@k8s ~]# ip netns exec Aurora ping 10.1.1.2PING 10.1.1.2 (10.1.1.2) 56(84) bytes of data.64 bytes from 10.1.1.2: icmp_seq=1 ttl=64 time=0.124 ms64 bytes from 10.1.1.2: icmp_seq=2 ttl=64 time=0.064 ms^C--- 10.1.1.2 ping statistics ---2 packets transmitted, 2 received, 0% packet loss, time 1006msrtt min/avg/max/mdev = 0.064/0.094/0.124/0.030 ms[root@k8s ~]# ping 10.1.1.1PING 10.1.1.1 (10.1.1.1) 56(84) bytes of data.64 bytes from 10.1.1.1: icmp_seq=1 ttl=64 time=0.096 ms64 bytes from 10.1.1.1: icmp_seq=2 ttl=64 time=0.041 ms^C--- 10.1.1.1 ping statistics ---2 packets transmitted, 2 received, 0% packet loss, time 1013msrtt min/avg/max/mdev = 0.041/0.068/0.096/0.028 ms[root@k8s ~]#
注意:ping百度和本地物理网卡结果如下图

- 如果两个veth口在同一个NS中,直接ping对端veth地址可以通信,但其实两个veth口抓包是没有信息的,是走回环lo口。
- 如果指定veth接口为源去ping,两个veth口只能主导request的包,lo口抓到reply包,但是ping进程没有收到,所以不通。
- 如果指定veth口的地址为源去ping对端的veth地址,可以通
结论:两个veth需要放在不同的NS当中,不然实际是没有意义的;放在不同的NS内,ping外网和本地接口是不通的。
2.3 Veth设备对-->Docker0
看下图思考一个问题,上述创建veth对可以保证不同NS之间可以互相通信,但是在在容器网络中如果出现非常多的NS的情况下,若创建很多的NS绑定Veth对会导致整个环境的混乱,那如何高效的去进行互通呢?
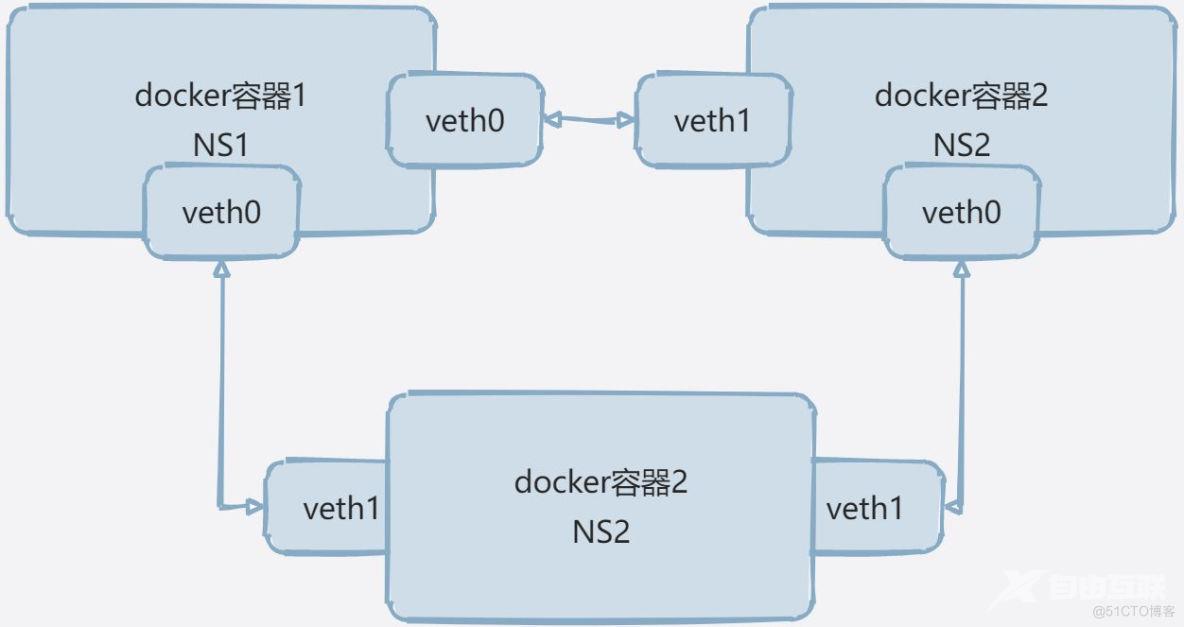
2.4 Linux 网桥
Linux网桥(bridge)技术就是上述问题的解决方案
定义:网桥是一个二层的虚拟网络设备,把若干个网络接口连接 起来,使得网络接口之间的报文能够互相转发。网桥能解析收发的报文,读取目标MAC地址的信息,和自己记录的MAC表集合,来决策报文的转发目标网络接口。网桥会学习源MAC地址,未知的MAC报文进行广播。
Linux内核支持网口的桥接
网桥与单纯的交换机是不同的,交换机只是一个单纯的二层设备,对于接收到的报文要么转发,要么丢弃;但运行着Linux内核的机器本身就是一台主机,有可能是网络报文的目的地,也就是网桥收到的报文除了转发和丢弃,还可能被选到协议栈的上层(网络层),从而被主机自身的协议栈进行处理,所有既可以把网桥看做一个二层设备,也可以把它看做一个三层设备
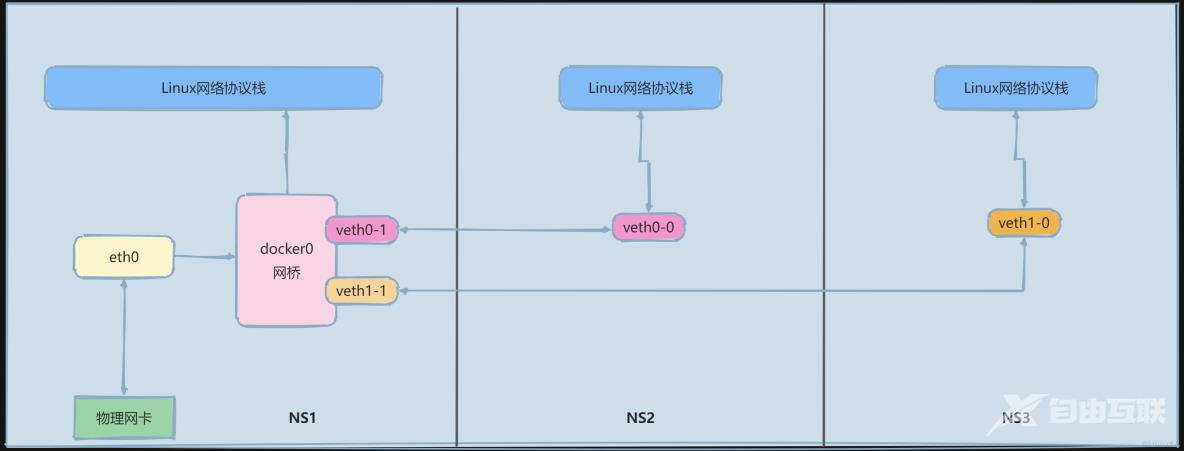
2.5 Docker0网桥原理
Docker服务启动后会自动创建一个docker的网桥:bridge模式是这样。它在内核层连通了其它的物理或虚拟网卡,这就将所有容器和本地主机都放到同一个网络中。通过ifconfig命令查看到的docker0貌似和eth0地位相当,像是一张网卡。然而并不是,docker就是一个Linux网桥。

Docker0是在docker启动后自动创建的一个网桥,创建后会分配一个地址给这个网桥,如果启动的容器不指定网络和模式,会自动加到docker0这个bridge上面,接下来这个网桥会做如下事情:
- 自动分配veth对
- 自动分配和其同一网段的地址
- 网关为docker0的地址
因此容器之间它们默认就是互通的;
