Python 处理大数据集可以借助 Python 内置数据结构:列表、元组、字典 、 集合等,但是一般要和 pandas 和 Numpy 等库结合起来使用。
熟练掌握Python,首先就是熟练掌握Python的数据结构:列表、元组、字典 、 集合。
本篇博客主要内容有,基础的数据结构: 列表、元组、字典 、 集合介绍,如何创建自定义函数,和如何操作Python文件对象及如何与本地硬盘交互。
系统:Windows10系统。 环境:Python3。 IDE:Jupyter Notebook.
元组
元组是一个固定长度,不可改变的Python序列对象。创建元组的最简单方式,是用逗号分隔一列值(一般不这么用),当用复杂的表达式定义元组,最好将值放到圆括号内。

使用tuple函数可以将任意序列或迭代器转换为元组:
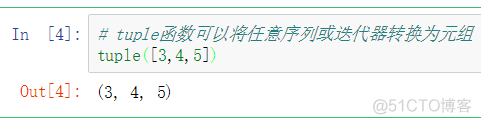
元组使用方法总结如下:
- tuple函数可以将任意序列或迭代器转换为元组;
- 可以用方括号访问元组中的元素。和C、C++、JAVA等语言一样,序列是从0开始的;
- 元组中存储的对象可能是可变对象。一旦创建了元组,元组中的对象就不能修改了,但对于元组中的可变对象,可以在原位进行修改;
- 可以用加号运算符将元组串联起来;
- 元组乘以一个整数,像列表一样,会将几个元组的复制串联起来(对象本身并没有被复制,只是引用了它)。

元组使用示例
tuple方法
因为元组的大小和内容不能修改,它的实例方法都很轻量。其中一个很有用的就是count(也适用于列表),它可以统计某个值得出现频率:
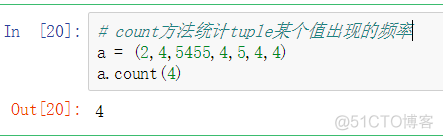
列表
与元组对比,列表的长度可变、内容可以被修改。你可以用方括号定义,或用 list() 函数创建列表。列表是以类的形式实现的。“创建”列表实际上是将一个类实例化。列表中的元素用逗号分隔!
添加删除元素
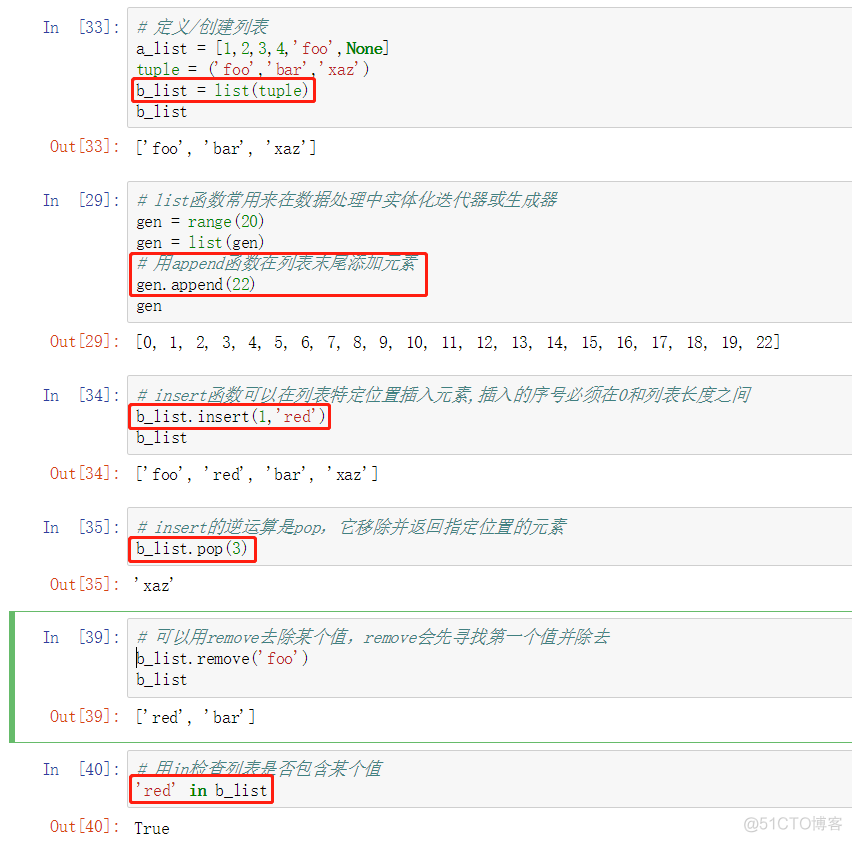
- append() 方法可以 在列表末尾添加元素。
- insert() 方法可以在特定位置插入元素,insert(i, value),i 是索引位置,value 是要插入元素的值。
- pop() 方法用以移除并返回指定位置的元素,是 insert 的逆运算,pop(i):其中 i 是索引位置。特殊的 pop() 操作用于删除 list 末尾的元素。
- remove() 方法去除某个值,remove 回寻找第一个值并除去。
- in 关键字可以检查列表是否包含某个值。
- reverse() 函数用于反向列表中元素。该方法没有返回值,但是会对列表的元素进行原地反向排序。
警告:与 append 相比,insert 耗费的计算量大,因为对后续元素的引用必须在 内部迁移,以便为新元素提供空间。如果要在序列的头部和尾部插入元素,可能需要使用 collections.deque,一个双尾部队列。 inset 方法使用时,插入的序号必须在 0 和列表长度之间。
如果不考虑性能,使用 append 和 remove,可以把 Python 的列表当做完美的“多重 集”数据结构。
在列表中检查是否存在某个值远比字典和集合速度慢,因为 Python 是线性搜索列表中的值,但在字典和集合中,在同样的时间内还可以检查其它项(基于哈希表)。
列表使用示例
串联和组合列表
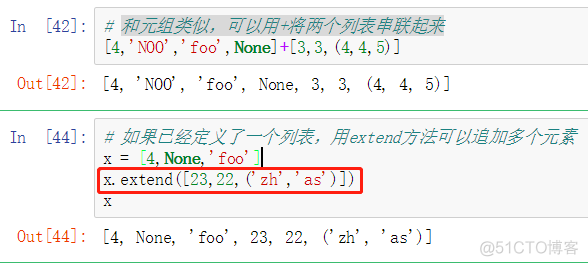
- 和元组类似,可以用 + 将两个列表串联起来;
- 如果已经定义了一个列表,用 extend 方法可以追加多个元素。
- append() 方法向列表的尾部添加一个新的元素,而 extend() 方法只接受一个列表作为参数,并将该参数的每个元素都添加到原有的列表中。
示例代码如下:
串联和组合列表示例
注意:通过加法将列表串联的计算量较大,因为这里要新建一个列表和复制对象。用 extend 方法用于对原来的列表追究元素,尤其是对于一个大列表要增加元素更为可取。示例代码如下:
everything = []for chunk in lists_of_list: everything.extend(chunk)排序
sort 方法可以将一个列表原地排序:
# sort方法可以将一个列表原地排序a = [334,433,121,44,31,2]a.sort()a语法:
list.sort(*, key=None, reverse=False)
参数:
- key — 指定带有一个参数的函数,用于从每个列表元素中提取比较键 (例如 key=str.lower)。 对应于列表中每一项的键会被计算一次,然后在整个排序过程中使用。 默认值 None 表示直接对列表项排序而不计算一个单独的键值。
- reverse — 排序规则,reverse = True 降序, reverse = False 升序(默认)
返回值:
该方法没有返回值,但是会对列表的对象进行排序。
示例1代码如下:
# 字符串排序def list_sort_string(): list=["delphi","Delphi","python","Python","c++","C++","c","C","golang","Golang"] list.sort() #按字典顺序升序排列 print("升序:",list) list.sort(reverse=True) #按降序排列 print("降序:",list)输出:
升序: [‘C’, ‘C++’, ‘Delphi’, ‘Golang’, ‘Python’, ‘c’, ‘c++’, ‘delphi’, ‘golang’, ‘python’] 降序: [‘python’, ‘golang’, ‘delphi’, ‘c++’, ‘c’, ‘Python’, ‘Golang’, ‘Delphi’, ‘C++’, ‘C’]
示例2代码如下:
# 根据列表中元素长度排序def list_sort_by_length(): list=["delphi","Delphi","python","Python","c++","C++","c","C","golang","Golang"] list.sort(key=lambda ele:len(ele)) #按元素长度顺序升序排列 print("升序:",list) list.sort(key=lambda ele:len(ele),reverse=True) #按降序排列 print("降序:",list)list_sort_by_length()输出
升序: [‘c’, ‘C’, ‘c++’, ‘C++’, ‘delphi’, ‘Delphi’, ‘python’, ‘Python’, ‘golang’, ‘Golang’] 降序: [‘delphi’, ‘Delphi’, ‘python’, ‘Python’, ‘golang’, ‘Golang’, ‘c++’, ‘C++’, ‘c’, ‘C’]
示例3代码如下:
# 使用对象的一些索引作为键对复杂对象进行排序。# 根据列表中元素的多个属性进行排序def two_d_list_sort(): list=[ ["1","c++","demo"], ["7","c","test"], ["9","java",""], ["8","golang","google"], ["4","python","gil"], ["5","swift","apple"] ] list.sort(key=lambda ele:ele[0])# 根据第1个元素排序 print(list) list.sort(key=lambda ele:ele[1]) #先根据第2个元素排序 print(list) list.sort(key=lambda ele:ele[1]+ele[0]) #先根据第2个元素排序,再根据第1个元素排序 print(list)two_d_list_sort()输出:
[[‘1’, ‘c++’, ‘demo’], [‘4’, ‘python’, ‘gil’], [‘5’, ‘swift’, ‘apple’], [‘7’, ‘c’, ‘test’], [‘8’, ‘golang’, ‘google’], [‘9’, ‘java’, ”]] [[‘7’, ‘c’, ‘test’], [‘1’, ‘c++’, ‘demo’], [‘8’, ‘golang’, ‘google’], [‘9’, ‘java’, ”], [‘4’, ‘python’, ‘gil’], [‘5’, ‘swift’, ‘apple’]] [[‘1’, ‘c++’, ‘demo’], [‘7’, ‘c’, ‘test’], [‘8’, ‘golang’, ‘google’], [‘9’, ‘java’, ”], [‘4’, ‘python’, ‘gil’], [‘5’, ‘swift’, ‘apple’]]
同样的技术也适用于具有命名属性的对象。例如:
class Student: def __init__(self, name, grade, age): self.name = name self.grade = grade self.age = age def __repr__(self): return repr((self.name, self.grade, self.age)) student_tuples = [ ('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10),]sorted(student_tuples, key=lambda student: student[2]) # sort by age## 输出 ### [('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]切片
切片可以用来寻去序列类型的一部分,基本形式是在方括号中使用start:stop。
下面通过代码看几个常用的用法:
seq = [4,4,5,56,1,9,6,22,87,3,7]print(seq[1:5])print(seq[0:5]) # 取前5个元素print(seq[:5]) # 取前5个元素print(seq[5:]) # 取后5个元素print(seq[-2:]) # 从后向前切2个元素print(seq[::3]) # 每3个取一个print(seq[:5:2]) # 前5个元素,每两个取一个输出:
[4, 5, 56, 1] [4, 4, 5, 56, 1] [4, 4, 5, 56, 1] [9, 6, 22, 87, 3, 7] [3, 7] [4, 56, 6, 3] [4, 5, 1]
列表方法总结
,del关键字,for遍历_houyanhua1的专栏-CSDN博客")
序列函数
Python 有一些常用的序列函数必须掌握。
enumerate函数
Python 内建的 enumerate 函数,可以返回 (i,value) 元组序列,常用于迭代序列的程序中:
for i, value in enumerate(collection): # do something with value索引数据时,使用 enumerate 的一个好方法是计算序列(唯一的)dict 映射到位置的值:
# 索引数据时,使用enumerate的一个好方法是计算序列(唯一的)dict映射到位置的值some_list = ['foo','bar','test']mapping = {}for i,v in enumerate(some_list): mapping[i] = vprint(mapping)输出:
{0: ‘foo’, 1: ‘bar’, 2: ‘test’}
sorted函数
sorted 高阶函数可以从任意序列的元素返回一个新的排好序的列表,注意 sort 函数是原地排序; sorted 一共有 iterable, key, reverse 这三个参数。
语法:
sorted(iterable, *, key=None, reverse=False)
参数:
- iterable:表示可以迭代的对象,例如可以是 dict.items()、dict.keys()等;
- key:是一个函数,用来选取参与比较的元素,实现自定义的排序,key 指定的函数将作用于 list 的每一个元素上,并根据 key 函数返回的结果进行排序。;
- reverse:用来指定排序是倒序还是顺序,reverse=true 则是倒序,reverse=false 时则是顺序,默认时 reverse=false。
返回:
返回一个新的已排序列表。
sorted 函数可以从任意序列的元素返回一个新的排好序的列表,对字典和列表排序的例子如下:
# 创建一个字典dict_data = {'Gilee':25, 'wangyan':21, 'Aiqun':32, 'lidaming':19} # 对字典进行排序print(sorted(dict_data)) # ['Aiqun', 'Gilee', 'lidaming', 'wangyan']
sorted 排序实例
sorted 函数不仅可以对 list、tuple 结构,还可以对字典 dict 按 key 排序和按value 排序。详情参考此文章。
注意:这里返回的是列表,列表元素为二元组对象。
1,对字典按照键(key)进行排序 :
# 初始化字典dict_data = {6:9,10:5,3:11,8:2,7:6}# 对字典按键(key)进行排序(默认由小到大)test_data_0 = sorted(dict_data.keys())# 输出结果print(test_data_0) #[3, 6, 7, 8, 10]test_data_1 = sorted(dict_data.items(),key=lambda x:x[0], reverse=False)# 输出结果print(test_data_1) #[(3, 11), (6, 9), (7, 6), (8, 2), (10, 5)]
2,对字典按照值(value)进行排序:
# 创建一个字典dict_data = {'a': 15, 'ab': 6, 'bc': 16, 'da': 95} #对字典按值(value)进行排序(默认由小到大)test_data_1 = sorted(dict_data.items(),key=lambda x:x[1])# 输出结果1print(test_data_1) # [('ab', 6), ('a', 15), ('bc', 16), ('da', 95)]# 对字典按值(value)进行倒序排序(由大到小)test_data_2 = sorted(dict_data.items(),key=lambda x:x[1],reverse=True) # 输出结果2print(test_data_2) # [('da', 95), ('bc', 16), ('a', 15), ('ab', 6)]这里的 dict_data.items() 实际上是将 dict_data 转换为可迭代对象,迭代对象的元素为(‘a’,15)、(‘ab’,21)、(‘bc’,32)、(‘da’,19),items()方法将字典的元素转化为了元组。
而这里 key 参数对应的 lambda 表达式的意思则是选取元组中的第二个元素作为比较参数(如果写作 key=lambda item:item[0] 的话则是选取第一个元素作为比较对象,也就是key值作为比较对象。lambda x:y 中 x 表示输出参数,y 表示lambda 函数的返回值),所以采用这种方法可以对字典的 value 进行排序。注意排序后的返回值是一个 list,而原字典中的名值对被转换为了 list 中的元组。
sort 与 sorted 区别:
- list.sort() 和 sorted() 都有一个 key 形参来指定在进行比较之前要在每个列表元素上进行调用的函数。
- sorted 函数可以接受和 sort 函数相同的参数。
- sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
- list 的 sort 方法返回的是对已经存在的列表进行操作(原地排序),而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行操作。
zip函数
- zip函数可以将多个列表、元组或其他序列组合成一个元组列表;
- zip 可以处理任意多的序列,元素的个数取决于最多的序列;
- zip 的常见用法之一是同时迭代多个序列,可能结合 enumerate 使用。
这个函数功能有些类似 np.stack 函数。(numpy.stack(arrays, axis=0),即将一维数组的数据按照指定的维度进行堆叠)
下面是zip函数使用的两个简单示例:
seq1 = ['foo','bar','cxz']seq2 = ['one','two','three']zipped = zip(seq1,seq2)list(zipped)输出:
[(‘foo’, ‘one’), (‘bar’, ‘two’), (‘cxz’, ‘three’)]
# 同时迭代多个序列,结合enumerate使用:for i,(a,b) in enumerate(zip(seq1,seq2)): print('{0}:{1},{2}'.format(i,a,b))0:foo,one 1:bar,two 2:cxz,three
字典
字典可能是 Python 最为重要的数据结构。它更为常见的名字是哈希映射或关联数组。它是键值对的大小可变集合,键和键值都是 Python 对象。创建字典的方法之一是使用尖括号,用冒号分割键和键值。
- 可以像访问列表或元组中的元素一样,访问、插入或设定字典中的元素;
- 可以用检查列表和元组是否包含某个值的方法,检查字典中是否包含某个键;
- 可以用 del 关键字或 pop 方法(返回值的同时删除键)删除值;
- keys 和 values 是字典的键和值的迭代器方法。虽然键值对没有顺序,这两个方法,可以用相同的顺序输出键和值。
- update 方法可以将一个字典与另一个融合;
下面是 keys 和 values 方法使用的一个示例:
# 分别用keys和values方法输出字典的键和值d1 = {'a':'some value','b':[12,43,21,87],'c':12}for k in d1.keys(): print(k)list(d1.values())输出:
a b c [‘some value’, [12, 43, 21, 87], 12]
dict() 函数创建字典
dict() 函数可用于创建字典。语法如下:
class dict(**kwarg)class dict(mapping, **kwarg)class dict(iterable, **kwarg)参数说明:
- **kwargs — 关键字
- mapping — 元素的容器。
- iterable — 可迭代对象
实例代码如下:
>>>dict() # 创建空字典{}>>> dict(a='a', b='b', t='t') # 传入关键字{'a': 'a', 'b': 'b', 't': 't'}>>> dict(zip(['one', 'two', 'three'], [1, 2, 3])) # 映射函数方式来构造字典{'three': 3, 'two': 2, 'one': 1} >>> dict([('one', 1), ('two', 2), ('three', 3)]) # 可迭代对象方式来构造字典{'three': 3, 'two': 2, 'one': 1}>>>判断key是否存在
有两种方法:
- if key in dict():通过 in 判断 key 是否存在
- dict.get(key, value):是通过 dict 提供的 get 方法,如果 key 不存在,可以返回 None,或者自己指定的 value。
字典的get()方法语法:
dict.get(key, default=None)
参数:
- key — 字典中要查找的键。
- default — 如果指定键的值不存在时,返回该默认值值。
返回值:
返回指定键的值,如果值不在字典中返回默认值None。
实例代码如下:
dict = {'Name': 'Zara', 'Age': 27} # 判断key 是否存在于dictif 'Harley' in dict: print('key exist in dict()')else: print('key not exist in dict()') # key not exist in dict()print(dict.get('Harley', 0)) # 0
字典 items() 方法
字典 items() 方法以列表返回可遍历的(键, 值) 元组数组。
实例代码如下:
dict = {'Name': 'Runoob', 'Age': 7}print ("Value : %s" % dict.items())输出如下:
Value : dict_items([(‘Age’, 7), (‘Name’, ‘Runoob’)])
默认情况下, dict 迭代的是 key。如果要迭代 value,可以用 for value in d.values(),如果要同时迭代 key 和 value,可以用 for k, v in d.items()。代码示例如下:
d = { 'Adam': 95, 'Lisa': 85, 'Bart': 59, 'Paul': 74 }sum = 0for key, value in d.items(): sum = sum + value print(key, ':' ,value)print('平均分为:' ,sum /len(d))
输出如下:
Adam : 95
Lisa : 85
Bart : 59
Paul : 74
平均分为: 78.25
用序列创建字典
我们可以将两个序列配对组合成字典,写法如下:
# 将两个序列配对组合成字典mapping = {}for key,value in zip(key_list,value_list): mapping[key] = vaule因为字典本质上是2元元组的集合,dict可以接受2元元组的列表:
mapping = dict(zip(range(5), reversed(range(5))))mapping{0: 4, 1: 3, 2: 2, 3: 1, 4: 0}
有效的键类型
字典的值可以是任意 Python 对象,而键通常是不可变的标量类型(整数、浮点型、字符串)或元组(元组中的对象必须是不可变的)。这被称为“可哈希性”。可以用hash函数检测一个对象是否是可哈希的(可被用作字典的键):
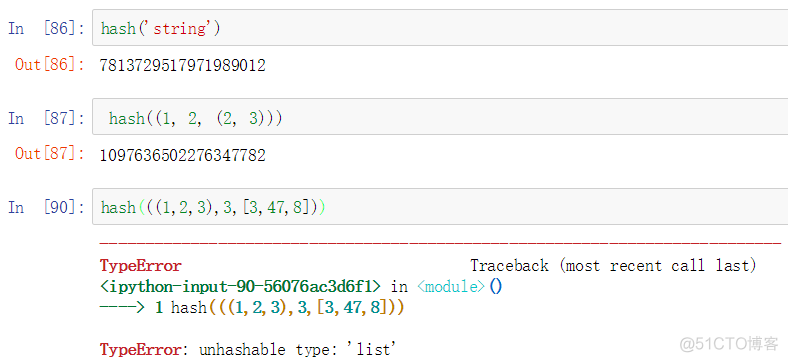
要用列表当做键,一种方法是将列表转化为元组,只要内部元素可以被哈希,它也就可以被哈希:
# 将列表转换为元组dicts = {}dicts[tuple([1,2,3])] = 5dicts输出:
{(1,2,3):5}
字典的 clear() 方法
Python 字典 clear() 函数用于删除字典内所有元素。语法:dict.clear(),dict 是字典对象。示例代码如下:
dict = {'Name': 'Harley', 'Age': 24}print ("字典长度 : %d" % len(dict))dict.clear()print ("字典删除后长度 : %d" % len(dict))####输出结果##### 字典长度 : 2# 字典删除后长度 : 0####输出结果####程序运行输出结果如下:
字典长度 : 2 字典删除后长度 : 0
集合
集合是无序的不可重复的元素的集合。你可以把它当做字典,但是只有键没有值。可以用两种方式创建集合:通过 set 函数或使用尖括号 set 语句:
s = set([1, 1, 2, 2, 3, 3])s # {1, 2, 3}
集合支持合并、交集、差分和对称差等数学集合运算。 集合常用方法如下图:
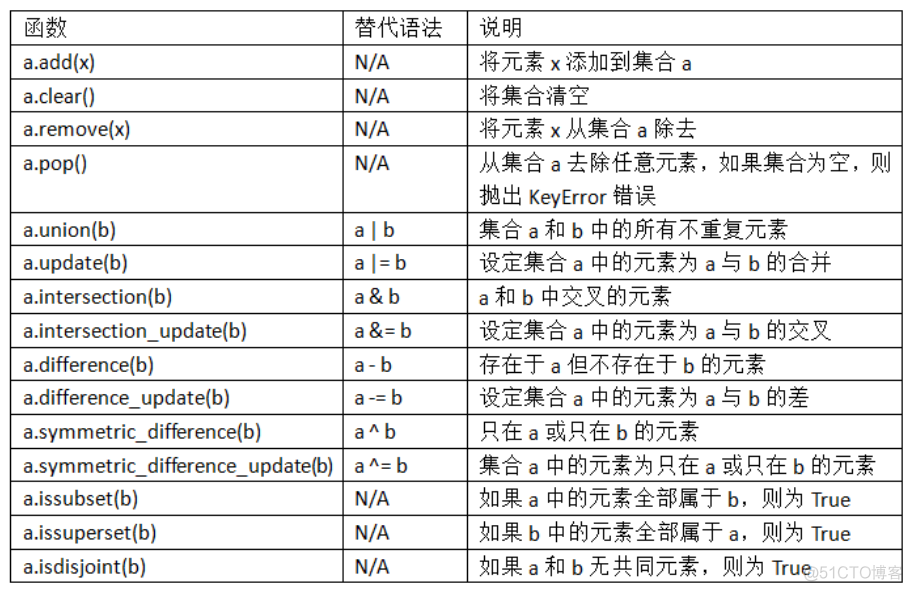
集合set常用方法
列表、集合和字典推导式
列表推导式(列表生成式)是 Python 最受喜爱的特性之一。它允许用户方便的从一个集合过滤元素,形成列表,在传递参数的过程中还可以修改元素。形式如下:
[expr for val in collection if condition]示例:给定一个字符串列表,我们可以过滤出长度在2及以下的字符串,并将其转换成大写,代码如下:
strings = ["delphi","Delphi","python","Python","c++","C++","c","C","golang","Golang"] [x.upper() for x in strings if len(x)>3]输出:
[‘DELPHI’, ‘DELPHI’, ‘PYTHON’, ‘PYTHON’, ‘GOLANG’, ‘GOLANG’]
用相似的方法,还可以推导集合和字典。字典的推导式如下所示:
dict_comp = {key-expr : value-expr for value in collection if condition}注意:list 是用数组实现的,dict 使用 hash 表实现的。
Python 可变对象与不可变对象
- int,str,float,tuple 都属于不可变对象 其中 tuple 有些特殊 ;
- dict,set,list 属于可变对象。
参考资料
- 利用Python进行数据分析第二版
- Python3 List sort()方法 | 菜鸟教程
- Python对字典分别按键(key)和值(value)进行排序