一、Trie 字典树 在计算机科学中,trie,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在
一、Trie 字典树
在计算机科学中,trie,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。[wikipedia]
Trie的典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。[百度百科]
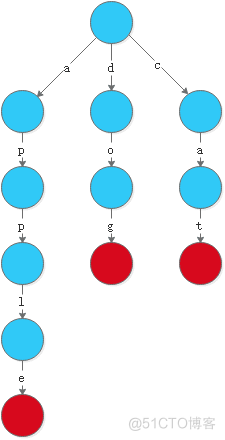
红色节点表示一个单词的结尾。
二、节点的设计
第一版
每个节点包含该节点的值,是否为单词的结尾,该节点的子节点。设计如下:
class Node{ private boolean isWord; private char val; private char[26] next; }问题所在:
- 多余的val,实际上指向该节点的引用中就包含了该节点的值是多少 ,所以val是多余的;
- 使用数组不合理,实际需求中不可能只有26个字母,也许有大小写,也许有其他符号,所以需要使用其他数据结构。
第二版
class Node{ public boolean isWord; public Map<Character,Node> next; }舍去了val,将指向下一节点的引用放在map里。此时暂时只考虑英文字符不考虑其他语言(中文等等)。
三、Trie的实现
3.1 Trie的基础实现
public class Trie { private class Node{ //true表示一个单词结尾,false表示非单词结尾 private boolean isWord; //k表示单词的组成字符, Node表示组成单词的剩余字符 private Map<Character, Node> next; public Node(){ this(false); } public Node(boolean isWord){ this.isWord = isWord; this.next = new TreeMap<>(); } } //Trie数据结构的根节点 private Node root; //Trie存储个多少个单词 private int size; //初始化Trie, root节点不存储数据 public Trie(){ this.root = new Node(); this.size = 0; } /** * 获得Trie中存储的单词数量 * @return */ public int getSize(){ return size; } }3.2 添加元素
- 往Trie 字典树中添加节点,步骤如图所示:
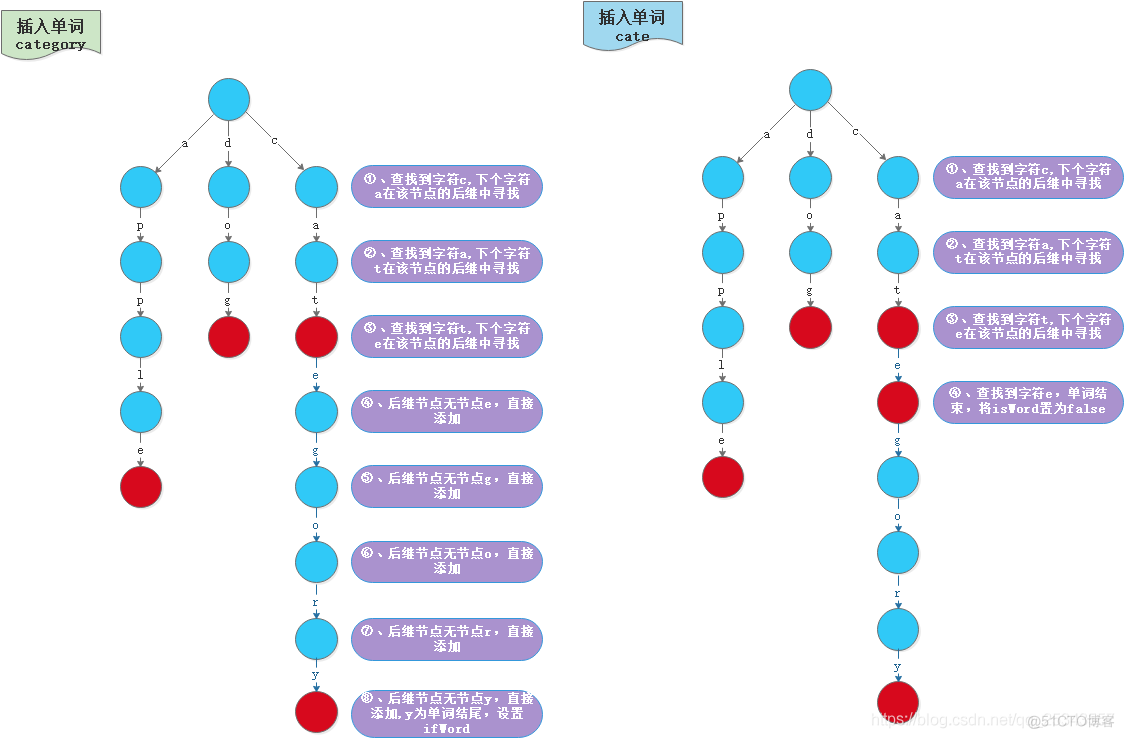
3.3 查找单词
- 查询Trie中是否包含该单词。
3.4 判断前缀
- 查询是否在Trie中有单词以prefix为前缀。
- 与查询单词方法大同小异。
3.5 删除单词
删除节点的情况共有如下四种情况:
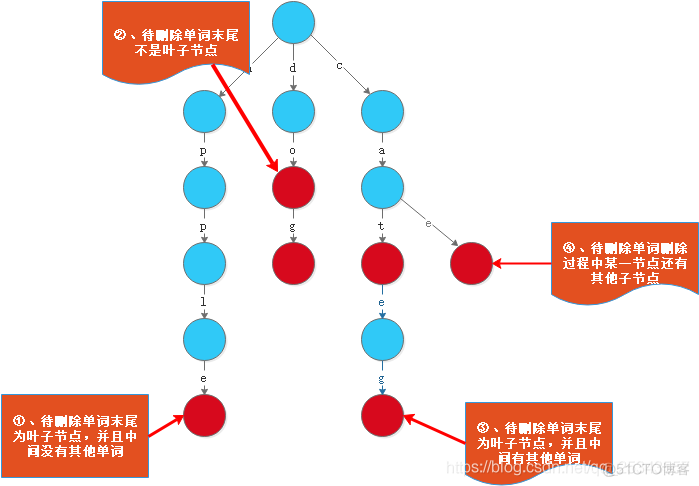
- 情况一:逐一将节点去除即可;
- 情况二:直接将isWord置为false即可;
- 情况三:逐一删除节点,如果待删除节点是另外一个单词结尾则停止删除;
- 情况四:逐一删除节点,但是如果待删除节点还有其他孩子节点则停止删除。
3.6 Trie完整实现代码
import java.util.Map; import java.util.Stack; import java.util.TreeMap; /** * @Author: huangyibo * @Date: 2022/2/25 23:03 * @Description: Trie */ public class Trie { private class Node{ //true表示一个单词结尾,false表示非单词结尾 private boolean isWord; //k表示单词的组成字符, Node表示组成单词的剩余字符 private Map<Character, Node> next; public Node(){ this(false); } public Node(boolean isWord){ this.isWord = isWord; this.next = new TreeMap<>(); } } //Trie数据结构的根节点 private Node root; //Trie存储个多少个单词 private int size; //初始化Trie, root节点不存储数据 public Trie(){ this.root = new Node(); this.size = 0; } /** * 获得Trie中存储的单词数量 * @return */ public int getSize(){ return size; } /** * 向Trie中添加一个新的单词word * @param word */ public void add(String word){ //从根节点开始添加单词 Node cur = root; for (int i = 0; i < word.length(); i++) { //提取单词中的字母 char ch = word.charAt(i); //如果root.next指向的TreeMap中不包含ch if(cur.next.get(ch) == null){ //直接创建一个新的节点映射 cur.next.put(ch, new Node()); } //存在ch节点,移动cur,继续查找下一字符的映射节点,重复循环 cur = cur.next.get(ch); } //如果不存在该单词,存在的话size不能加1 if(!cur.isWord){ //循环完成之后,表示单词添加成功 cur.isWord = true; size++; } } /** * 查询单词word是否在Trie中 * @param word * @return */ public boolean contains(String word){ //从根节点开始 Node cur = root; for (int i = 0; i < word.length(); i++) { //提取单词中的字母 char ch = word.charAt(i); //如果root.next指向的TreeMap中不包含ch if(cur.next.get(ch) == null){ //直接返回false return false; } //存在ch节点,移动cur,继续查找下一字符的映射节点,重复循环 cur = cur.next.get(ch); } //直接返回cur.isWord // 如果不存在该单词,该值为false, 存在则返回true return cur.isWord; } /** * 查询是否在Trie中有单词以prefix为前缀 * @param prefix * @return */ public boolean isPrefix(String prefix){ //从根节点开始 Node cur = root; for (int i = 0; i < prefix.length(); i++) { //提取单词中的字母 char ch = prefix.charAt(i); //如果root.next指向的TreeMap中不包含ch if(cur.next.get(ch) == null){ //直接返回false return false; } //存在ch节点,移动cur,继续查找下一字符的映射节点,重复循环 cur = cur.next.get(ch); } //循环走完,则表示Trie中有单词以prefix为前缀 return true; } /** * 删除Trie中word单词 * @param word */ public void delete(String word){ //删除前查找是否存在这个单词,存在才能删除 if(!contains(word)){ //不存在该单词,直接返回 return; } Stack<Node> preNodes = new Stack<>(); //存在word单词 Node cur = root; for (int i = 0; i < word.length(); i++) { char ch = word.charAt(i); //添加前驱节点 preNodes.push(cur); cur = cur.next.get(ch); } //到了单词末尾,节点是叶子节点 if(cur.next.size() == 0){ for (int i = word.length() - 1; i >= 0; i--) { char ch = word.charAt(i); //获得前驱节点 Node pre = preNodes.pop(); //判断是否为其他单词的结尾,是则停止删除节点 //判断待删除节点是否还有其他孩子,有则停止删除节点 if((i != word.length() - 1 && pre.next.get(ch).isWord) || pre.next.get(ch).next.size() != 0){ break; } pre.next.remove(ch);//删除节点 } }else { //不是单词末尾,节点不是叶子节点 cur.isWord = false; } size--; } }四、Trie应用
leetcode 211. 添加与搜索单词 - 数据结构设计
import java.util.Map; import java.util.TreeMap; /** * @Author: huangyibo * @Date: 2022/2/26 0:51 * @Description: leetcode 211. 添加与搜索单词 - 数据结构设计 * 请你设计一个数据结构,支持 添加新单词 和 查找字符串是否与任何先前添加的字符串匹配 * 实现词典类 WordDictionary : * * WordDictionary() 初始化词典对象 * void addWord(word) 将 word 添加到数据结构中,之后可以对它进行匹配 * bool search(word) 如果数据结构中存在字符串与 word 匹配,则返回 true ;否则,返回 false 。word 中可能包含一些 '.' ,每个 . 都可以表示任何一个字母。 */ public class WordDictionary { private class Node{ public boolean isword; public Map<Character,Node> next; public Node(){ this(false); } public Node(boolean isword){ this.isword = isword; next = new TreeMap<>(); } } private Node root; /** Initialize your data structure here. */ public WordDictionary() { root = new Node(); } /** Adds a word into the data structure. */ public void addWord(String word) { Node cur = root; for (int i = 0; i < word.length(); i++) { char ch = word.charAt(i); if(cur.next.get(ch) == null){ cur.next.put(ch,new Node()); } cur = cur.next.get(ch); } if(!cur.isword){ cur.isword = true; } } /** * Returns if the word is in the data structure. * A word could contain the dot character '.' to represent any one letter. */ public boolean search(String word) { return match(root,word,0); } private boolean match(Node node,String word,int index){ if(index == word.length()){ return node.isword; } char ch = word.charAt(index); if(ch != '.'){ if(node.next.get(ch) == null){ return false; } return match(node.next.get(ch),word,index + 1); }else { for (Character nextChar : node.next.keySet()) { if(match(node.next.get(nextChar),word,index + 1)){ return true; } } return false; } } }leetcode 677. 键值映射
import java.util.Map; import java.util.TreeMap; /** * @Author: huangyibo * @Date: 2022/2/26 1:04 * @Description: leetcode 677. 键值映射 * * 设计一个 map ,满足以下几点: * 字符串表示键,整数表示值 * 返回具有前缀等于给定字符串的键的值的总和 * * 实现一个 MapSum 类: * MapSum() 初始化 MapSum 对象 * void insert(String key, int val) 插入 key-val 键值对, * 字符串表示键 key ,整数表示值 val 。 * 如果键 key 已经存在,那么原来的键值对 key-value 将被替代成新的键值对。 * int sum(string prefix) 返回所有以该前缀 prefix 开头的键 key 的值的总和。 * */ public class MapSum { private class Node{ public int value; public Map<Character,Node> next; public Node(){ this(0); } public Node(int value){ this.value = value; next = new TreeMap<>(); } } private Node root; /** Initialize your data structure here. */ public MapSum() { root = new Node(); } public void insert(String key, int val) { Node cur = root; for (int i = 0; i < key.length(); i++) { char ch = key.charAt(i); if(cur.next.get(ch) == null){ cur.next.put(ch,new Node()); } cur = cur.next.get(ch); } cur.value = val; } public int sum(String prefix) { Node cur = root; for (int i = 0; i < prefix.length(); i++) { char ch = prefix.charAt(i); if(cur.next.get(ch) == null){ return 0; } cur = cur.next.get(ch); } return sum(cur); } private int sum(Node node){ int res = node.value; for (Character ch : node.next.keySet()) { res += sum(node.next.get(ch)); } return res; } }参考: https://blog.csdn.net/qq_25343557/article/details/88797312