前言
- 如果不使用线程池,每个任务都需要新开一个线程处理
- 这样开销太大,我们希望有固定数量的线程来执行任务,这样就避免了反复创建并销毁线程所带来的开销问题
为什么要使用线程池
- 反复创建线程开销大
- 过多的线程会占用太多的内存
解决以上两个问题的思路:
- 用少量的线程——避免内存占用过多
- 让这部分线程都保持工作,且可以反复执行任务,避免生命周期的损耗
线程池的好处
- 加快响应速度
- 合理利用CPU和内存
- 统一管理资源
线程池适合应用的场合
- 服务器接受到大量请求时,使用线程池技术是非常适合的,它可以大大减少线程的创建和销毁次数,以提高服务器的工作效率
- 实际上,在开发中,如果需要创建5个以上的线程,那么就可以使用线程池来管理
创建和停止线程池
- 线程池构造函数的参数
- 线程池应该手动创建还是自动创建
- 线程池里的线程数量设定为多少比较合适?
- 停止线程池的正确方法
线程池构造函数的参数
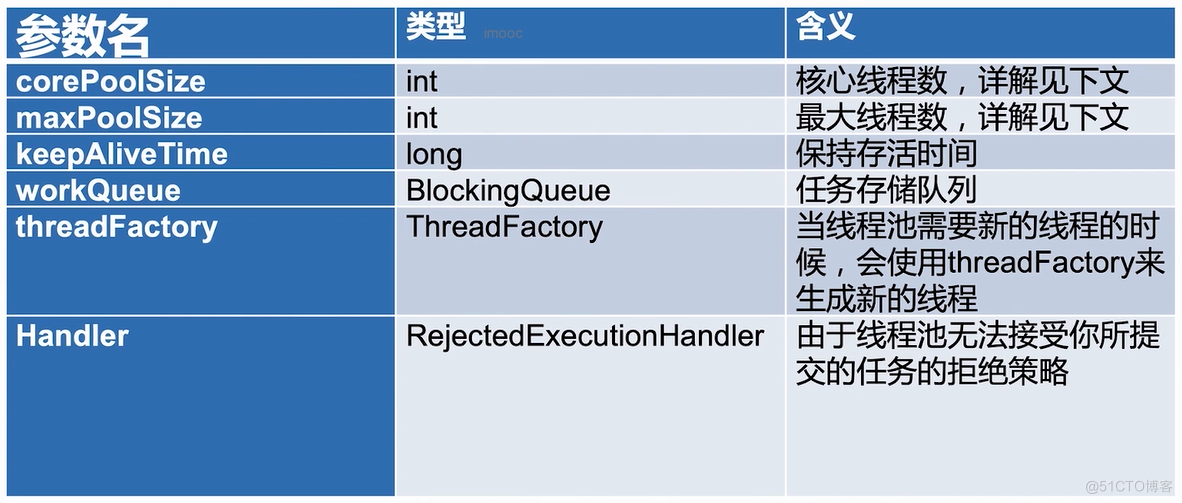


添加线程的规则
- 1、如果线程数小于corePoolSize,即使其他工作线程处于空闲状态,也会创建一个新线程来运行新任务
- 2、如果线程数等于(或大于)corePoolSize但少于maximumPoolSize,则将任务放入队列
- 3、如果队列已满,并且线程数小于maxPoolSize,则创建一个新线程来运行任务
- 4、如果队列已满,并且线程数大于或等于maxPoolSize,则拒绝该任务
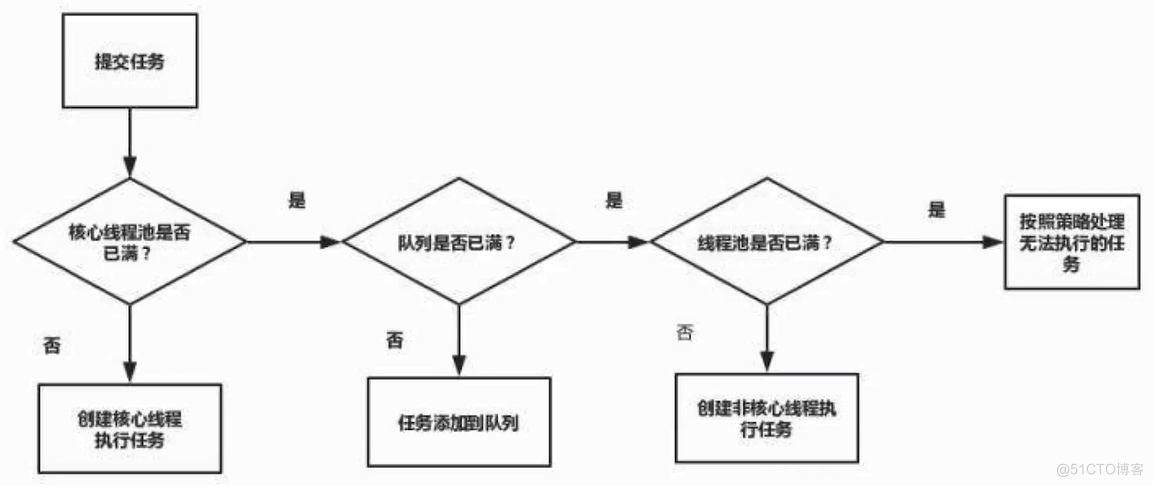

增减线程的特点
- 1、通过设置corePoolSize和maximumPoolSize相同,就可以创建固定大小的线程池
- 2、线程池希望保持较少的线程数,并且只有在负载变得很大时才增加它
- 3、通过设置maximumPoolSize为很高的值,例如Integer.MAX_VALUE,可以允许线程池容纳任意数量的并发任务
- 4、只有在任务队列填满时才创建多于corePoolSize的线程,所以如果你使用的是无界队列(例如LinkedBlockingQueue),那么线程数就不会超过corePoolSize
keepAliveTime
- 如果线程池当前的线程数多于corePoolSize,那么如果多于的线程空闲时间超过keepAliveTime,它们就会被终止
ThreadFactory 用来创建线程
- 新的线程是由ThreadFactory创建的,默认使用Executors.defaultThreadFactory(),创建出来的线程都在同一个线程组,拥有同样的NORM_PRIORITY优先级并且都不是守护线程。如果自己指定ThreadFactory,那么就可以改变线程名、线程组、优先级、是否是守护线程等。
workQueue 任务队列
有3种常见的队列类型:
- 1、直接交接:SynchronousQueue
- 2、无界队列:LinkedBlockingQueue
- 3、有界队列:ArrayBlockingQueue
线程池应该手动创建还是自动创建
- 手动创建更好,因为这样可以让我们更加明确线程池的运行规则,避免资源耗尽的风险。
- 让我们看看自动创建线程池(也就是直接调用JDK封装好的构造函数)可能带来的问题
newFixedThreadPool
- 创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
- 由于传进去LinkedBlockingQueue是没有容量上限的,所以当请求数越来越多,并且无法及时处理完毕的时候,也就是请求堆积的时候,会容易造成占用大量的内存,可能会导致OOM
newSingleThreadExecutor
- 创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
- 由源码可以看出和newFixedThreadPool的原理基本一样,只不过把线程数直接设置成了1,由于传进去的还是LinkedBlockingQueue,所以还是会导致同样的问题,就是当请求堆积的时候,可能会占用大量的内存
CachedThreadPool
- 可缓存线程池
- 特点:无界线程池,具有自动回收多于线程的功能
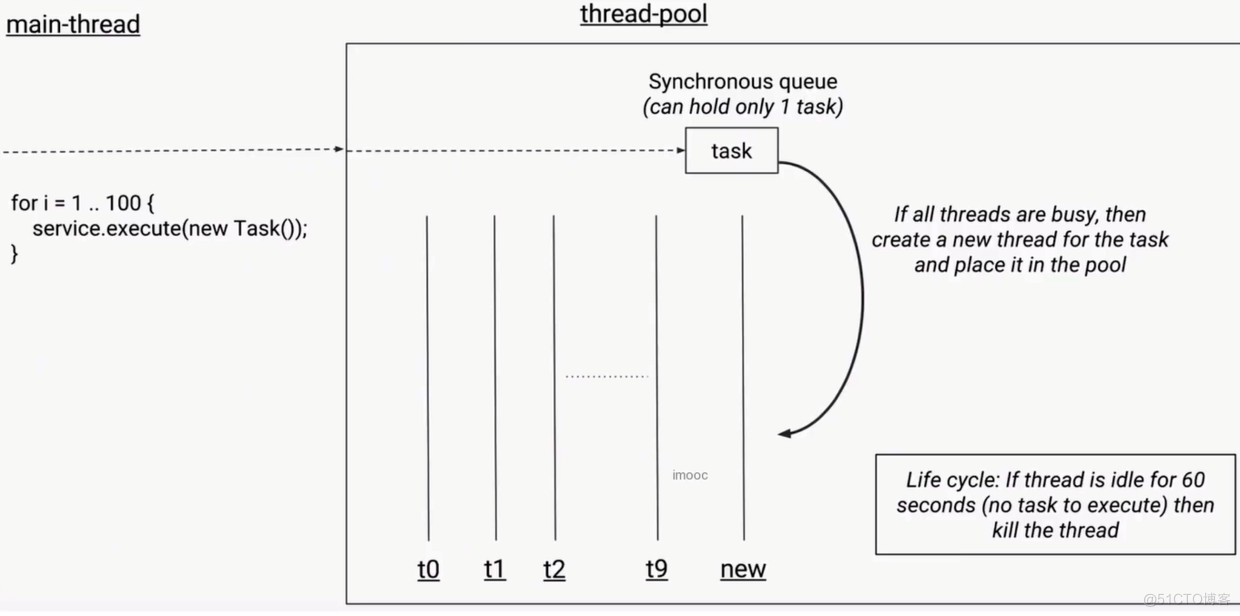
newCachedThreadPool
- 创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
- 这里的弊端在于第二个构造参数maximumPoolSize被设置为了Integer.MAX_VALUE,这可能会创建数量非常多的线程,,甚至导致OOM
ScheduledThreadPool
- 支持定时及周期性任务执行的线程池
newScheduledThreadPool
- 创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
正确创建线程池的方法
- 根据不同的业务场景,自己设置线程池参数,比如我们的内存有多大,想要给线程取什么名字等
线程池里的线程数量设定为多少合适
- CPU密集型(加密、计算hash等):最佳线程数为CPU核心数的1-2倍左右
- 耗时I/O型(读写数据库、文件、网络读写等):最佳线程数一般会大于CPU核心数很多倍,以JVM线程监控显示繁忙情况为依据,保证线程空闲可以衔接上,参考Brain Goetz推荐的计算方法。
- 线程数=CPU核心数*(1+平均等待时间 / 平均工作时间)
常见线程池的特点
-
FixedThreadPool
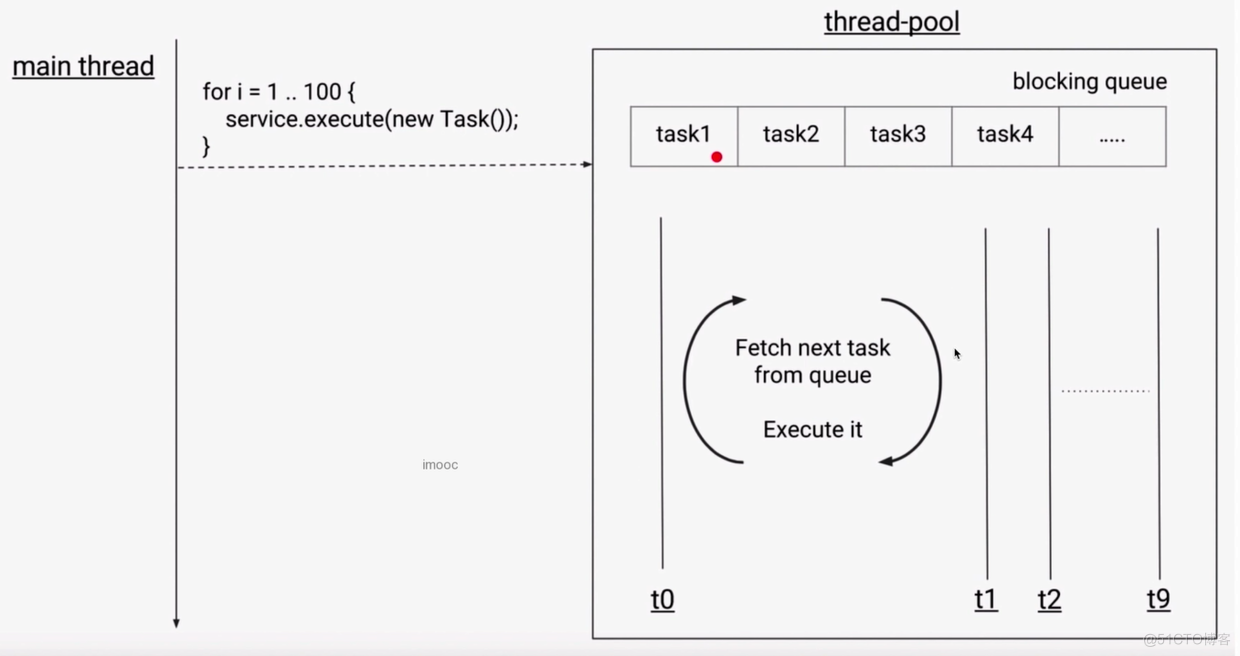
-
CachedThreadPool
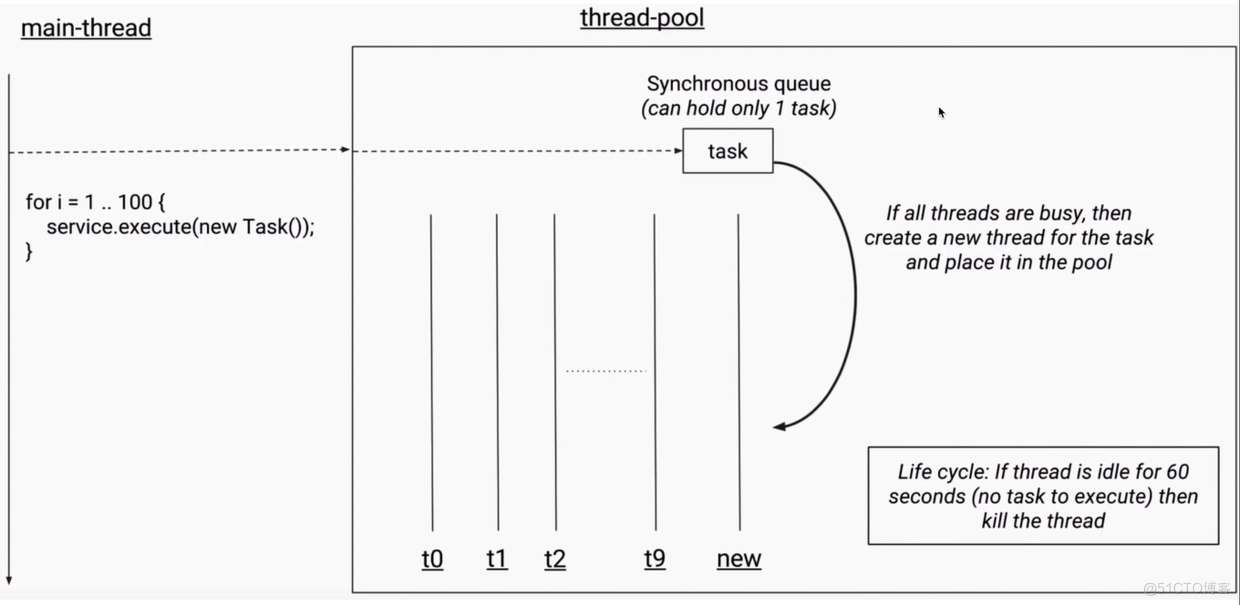
-
ScheduledThreadPool 支持定时及周期性任务执行的线程池
-
SingleThreadExecutor 单线程的线程池:它只会用唯一的工作线程来执行任务 他的原理和FixedThreadPool一样,但是此时的线程数量被设置为了1
以上4种线程池的构造函数的参数
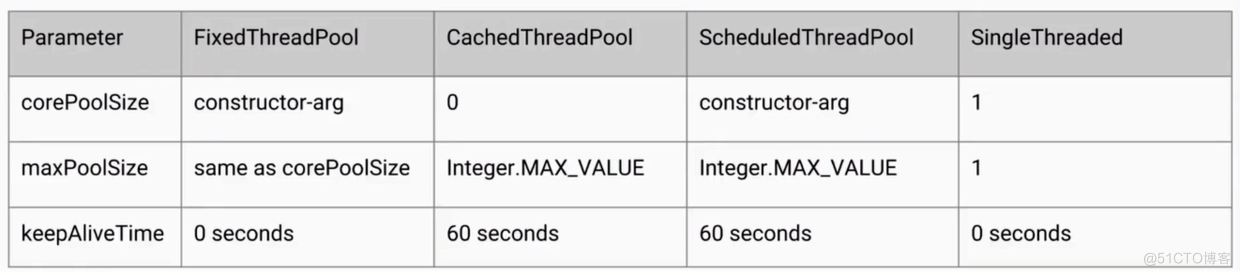
阻塞队列分析
- FixedThreadPool和SingleThreadExecutor的Queue是LinkedBlockingQueue
- CachedThreadPool使用Queue是SynchronousQueue
- ScheduledThreadPool使用的是延迟队列DelayedWorkQueue
WorkStealingPool
工作窃取线程池是JDK1.8加入的
- 假设共有三个线程同时执行, A, B, C
- 当A,B线程池尚未处理任务结束,而C已经处理完毕,则C线程会从A或者B中窃取任务执行,这就叫工作窃取
- 假如A线程中的队列里面分配了5个任务,而B线程的队列中分配了1个任务,当B线程执行完任务后,它会主动的去A线程中窃取其他的任务进行执行
- WorkStealingPool 背后是使用 ForkJoinPool实现的
- 这个线程池和之前的都有很大不同
- 子任务:这个任务可以产生子任务的话适用这种场景,比如二叉树的遍历、处理矩阵等
- 窃取
停止线程池的正确方法
- 1、shutdown()
- 有序关闭,已提交任务继续执行
- 不接受新任务
- 2、shutdownNow()
- 尝试停止所有正在执行的任务
- 停止等待执行的任务,并返回等待执行的任务列表
- 3、isShutdown
- 当调用shutdown()或shutdownNow()方法后返回为true。
- 4、isTerminated
- 当调用shutdown()方法后,并且所有提交的任务完成后返回为true
- 当调用shutdownNow()方法后,成功停止后返回为true
- 5、awaitTermination(long timeout, TimeUnit unit)
- 收到关闭请求后,所有任务执行完成、超时、线程被打断,阻塞直到三种情况任意一种发生
- 参数可以设置超时时间与超时单位
- 线程池关闭返回 true;超过设置时间未关闭,返回 false
任务太多怎么拒绝
拒绝时机
- 1、当Executor关闭时,提交新任务会被拒绝
- 2、当Executor对最大线程和工作队列容量使用的有限编边界趋于饱和时

线程池的拒绝策略
线程池中,有三个重要的参数,决定影响了拒绝策略:corePoolSize - 核心线程数,也即最小的线程数。workQueue - 阻塞队列 。maximumPoolSize - 最大线程数
当提交任务数大于 corePoolSize 的时候,会优先将任务放到 workQueue 阻塞队列中。当阻塞队列饱和后,会扩充线程池中线程数,直到达到 maximumPoolSize 最大线程数配置。此时,再多余的任务,则会触发线程池的拒绝策略了。
总结起来,也就是一句话,当提交的任务数大于(workQueue.size() + maximumPoolSize ),就会触发线程池的拒绝策略。
拒绝策略定义
拒绝策略提供顶级接口 RejectedExecutionHandler ,其中方法 rejectedExecution 即定制具体的拒绝策略的执行逻辑。
jdk默认提供了四种拒绝策略:
-
CallerRunsPolicy:当触发拒绝策略,只要线程池没有关闭的话,则使用调用线程直接运行任务。 一般并发比较小,性能要求不高,不允许失败。但是,由于调用者自己运行任务,如果任务提交速度过快,可能导致程序阻塞,性能效率上必然的损失较大
-
AbortPolicy:丢弃任务,并抛出拒绝执行 RejectedExecutionException 异常信息。线程池默认的拒绝策略。必须处理好抛出的异常,否则会打断当前的执行流程,影响后续的任务执行。
-
DiscardPolicy:直接丢弃,其他啥都没有
-
DiscardOldestPolicy:当触发拒绝策略,只要线程池没有关闭的话,丢弃阻塞队列 workQueue 中最老的一个任务,并将新任务加入
测试拒绝策略
1、AbortPolicy
public class T2 { public static void main(String[] args) throws Exception{ int corePoolSize = 5; int maximumPoolSize = 10; long keepAliveTime = 5; BlockingQueue<Runnable> workQueue = new LinkedBlockingQueue<Runnable>(10); RejectedExecutionHandler handler = new ThreadPoolExecutor.AbortPolicy(); ThreadPoolExecutor executor = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, TimeUnit.SECONDS, workQueue, handler); for(int i=0; i<100; i++) { try { executor.execute(new Thread(() -> log.info(Thread.currentThread().getName() + " is running"))); } catch (Exception e) { log.error(e.getMessage()); } } executor.shutdown(); } }如果 executor.execute()提交任务,由于会抛出 RuntimeException,没有try.catch处理异常信息的话,会中断调用者的处理流程,后续任务得不到执行(跑不完100个)。可自行测试下。
2、CallerRunsPolicy 主体代码同上,更换拒绝策略: RejectedExecutionHandler handler =` `new` `ThreadPoolExecutor.CallerRunsPolicy(); 运行后,在控制台console中能够看到的是,会有一部分的数据打印,显示的是 “main is running”,也即体现调用线程处理。
3、DiscardPolicy 更换拒绝策略 RejectedExecutionHandler handler =` `new` `ThreadPoolExecutor.DiscardPolicy(); 直接丢弃任务,实际运行中,打印出的信息不会有100条。
4、DiscardOldestPolicy 同样的,更换拒绝策略: RejectedExecutionHandler handler =` `new` `ThreadPoolExecutor.DiscardOldestPolicy(); 实际运行,打印出的信息也会少于100条。
四种拒绝策略是相互独立无关的,选择何种策略去执行,还得结合具体的业务场景。实际工作中,一般直接使用 ExecutorService 的时候,都是使用的默认的 defaultHandler ,也即 AbortPolicy 策略。
钩子方法
- beforeExecute():线程执行之前调用
- afterExecute():线程执行之后调用
- terminaerd():线程池退出时候调用
- 每个任务执行前后
- 日志、统计
线程池组成部分
- 线程池管理器
- 工作线程
- 任务队列
- 任务接口(Task)
Executor类图
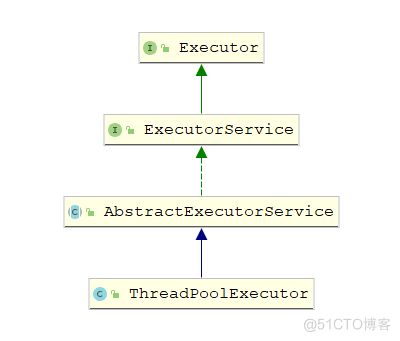
线程池状态
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); private static final int COUNT_BITS = Integer.SIZE - 3; private static final int CAPACITY = (1 << COUNT_BITS) - 1; // runState is stored in the high-order bits private static final int RUNNING = -1 << COUNT_BITS; private static final int SHUTDOWN = 0 << COUNT_BITS; private static final int STOP = 1 << COUNT_BITS; private static final int TIDYING = 2 << COUNT_BITS; private static final int TERMINATED = 3 << COUNT_BITS; // Packing and unpacking ctl private static int runStateOf(int c) { return c & ~CAPACITY; } private static int workerCountOf(int c) { return c & CAPACITY; } private static int ctlOf(int rs, int wc) { return rs | wc; }其中ctl这个AtomicInteger的功能很强大,其高3位用于维护线程池运行状态,低29位维护线程池中线程数量
-
1、RUNNING:-1<<COUNT_BITS,即高3位为1,低29位为0,该状态的线程池会接收新任务,也会处理在阻塞队列中等待处理的任务
-
2、SHUTDOWN:0<<COUNT_BITS,即高3位为0,低29位为0,该状态的线程池不会再接收新任务,但还会处理已经提交到阻塞队列中等待处理的任务
-
3、STOP:1<<COUNT_BITS,即高3位为001,低29位为0,该状态的线程池不会再接收新任务,不会处理在阻塞队列中等待的任务,而且还会中断正在运行的任务
-
4、TIDYING:2<<COUNT_BITS,即高3位为010,低29位为0,所有任务都被终止了,workerCount为0,为此状态时还将调用terminated()方法
-
5、TERMINATED:3<<COUNT_BITS,即高3位为100,低29位为0,terminated()方法调用完成后变成此状态
这些状态均由int型表示,大小关系为 RUNNING<SHUTDOWN<STOP<TIDYING<TERMINATED,这个顺序基本上也是遵循线程池从 运行 到 终止这个过程。
runStateOf(int c) 方法:c & 高3位为1,低29位为0的~CAPACITY,用于获取高3位保存的线程池状态
workerCountOf(int c)方法:c & 高3位为0,低29位为1的CAPACITY,用于获取低29位的线程数量
ctlOf(int rs, int wc)方法:参数rs表示runState,参数wc表示workerCount,即根据runState和workerCount打包合并成ctl
任务提交内部原理
1、execute() -- 提交任务
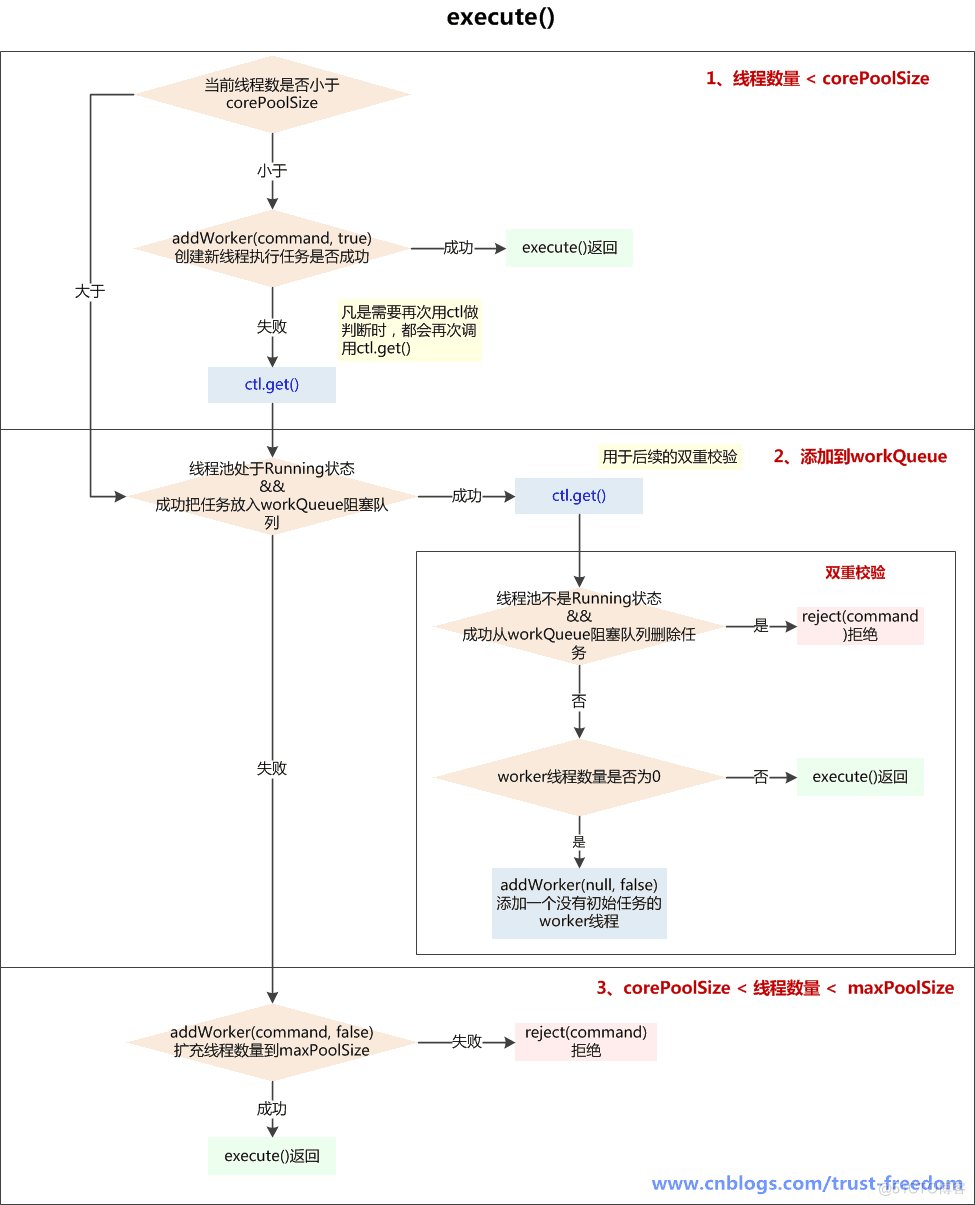
参数: command 提交执行的任务,不能为空 执行流程:
- 1、如果线程池当前线程数量少于corePoolSize,则addWorker(command, true)创建新worker线程,如创建成功返回,如没创建成功,则执行后续步骤;
addWorker(command, true)失败的原因可能是:
- A、线程池已经shutdown,shutdown的线程池不再接收新任务
- B、workerCountOf(c) < corePoolSize 判断后,由于并发,别的线程先创建了worker线程,导致workerCount>=corePoolSize
- 2、如果线程池还在running状态,将task加入workQueue阻塞队列中,如果加入成功,进行double-check,如果加入失败(可能是队列已满),则执行后续步骤;
double-check主要目的是判断刚加入workQueue阻塞队列的task是否能被执行
- A、如果线程池已经不是running状态了,应该拒绝添加新任务,从workQueue中删除任务
- B、如果线程池是运行状态,或者从workQueue中删除任务失败(刚好有一个线程执行完毕,并消耗了这个任务),确保还有线程执行任务(只要有一个就够了)
- 3、如果线程池不是running状态 或者 无法入队列,尝试开启新线程,扩容至maxPoolSize,如果addWork(command, false)失败了,拒绝当前command
2、addWorker() -- 添加worker线程
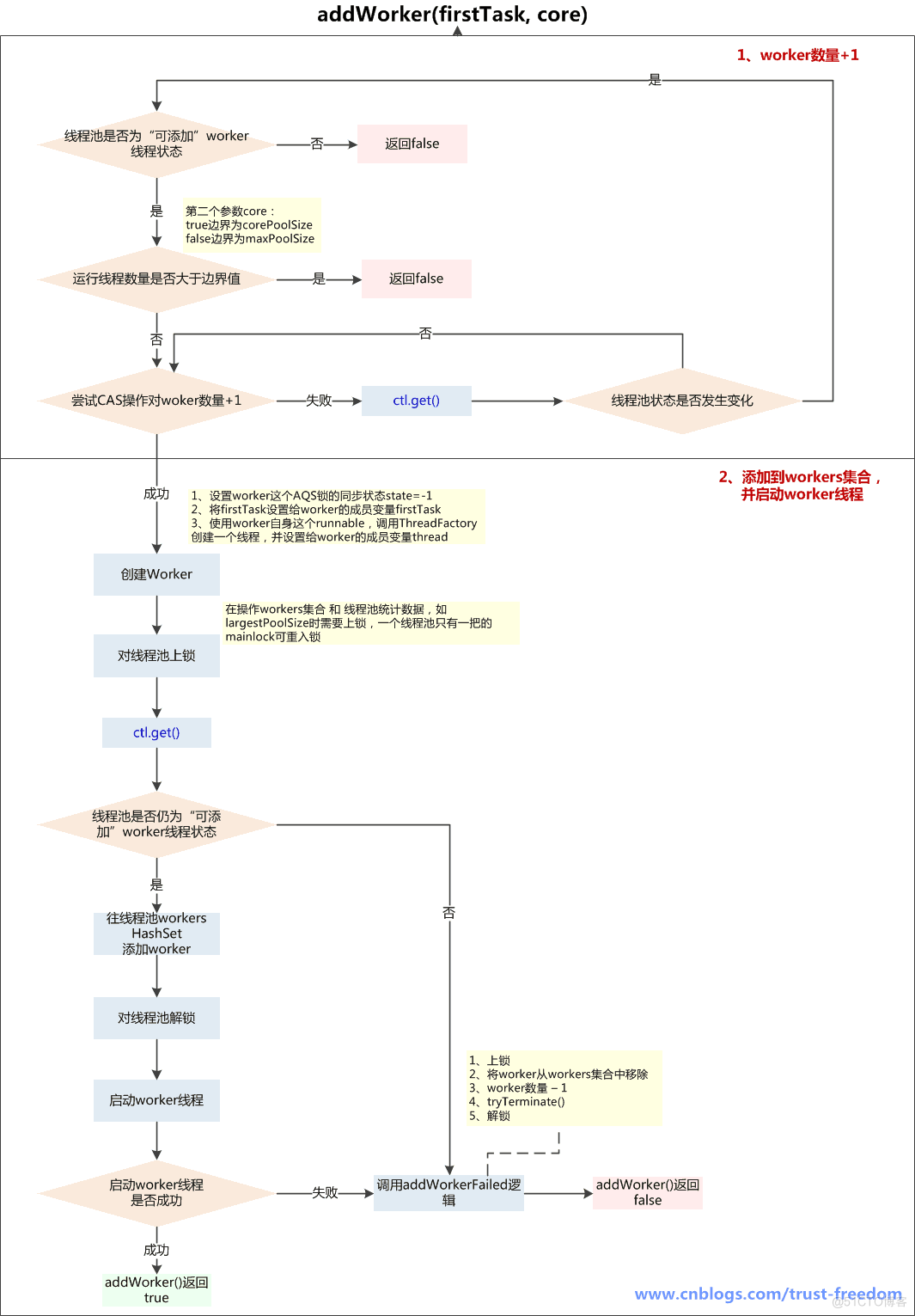
addWorker(Runnable firstTask, boolean core) 参数: firstTask: worker线程的初始任务,可以为空 core: true:将corePoolSize作为上限,false:将maximumPoolSize作为上限 addWorker方法有4种传参的方式:
- 1、addWorker(command, true)
- 2、addWorker(command, false)
- 3、addWorker(null, false)
- 4、addWorker(null, true)
在execute方法中就使用了前3种,结合这个核心方法进行以下分析
- 第一个:线程数小于corePoolSize时,放一个需要处理的task进Workers Set。如果Workers Set长度超过corePoolSize,就返回false
- 第二个:当队列被放满时,就尝试将这个新来的task直接放入Workers Set,而此时Workers Set的长度限制是maximumPoolSize。如果线程池也满了的话就返回false
- 第三个:放入一个空的task进workers Set,长度限制是maximumPoolSize。这样一个task为空的worker在线程执行的时候会去任务队列里拿任务,这样就相当于创建了一个新的线程,只是没有马上分配任务
- 第四个:这个方法就是放一个null的task进Workers Set,而且是在小于corePoolSize时,如果此时Set中的数量已经达到corePoolSize那就返回false,什么也不干。实际使用中是在prestartAllCoreThreads()方法,这个方法用来为线程池预先启动corePoolSize个worker等待从workQueue中获取任务执行 执行流程:
- 1、判断线程池当前是否为可以添加worker线程的状态,可以则继续下一步,不可以return false:
- A、线程池状态>shutdown,可能为stop、tidying、terminated,不能添加worker线程
- B、线程池状态==shutdown,firstTask不为空,不能添加worker线程,因为shutdown状态的线程池不接收新任务
- C、线程池状态==shutdown,firstTask==null,workQueue为空,不能添加worker线程,因为firstTask为空是为了添加一个没有任务的线程再从workQueue获取task,而workQueue为空,说明添加无任务线程已经没有意义
- 2、线程池当前线程数量是否超过上限(corePoolSize 或 maximumPoolSize),超过了return false,没超过则对workerCount+1,继续下一步
- 3、在线程池的ReentrantLock保证下,向Workers Set中添加新创建的worker实例,添加完成后解锁,并启动worker线程,如果这一切都成功了,return true,如果添加worker入Set失败或启动失败,调用addWorkerFailed()逻辑
3、内部类Worker
/** * Class Worker mainly maintains interrupt control state for * threads running tasks, along with other minor bookkeeping. * This class opportunistically extends AbstractQueuedSynchronizer * to simplify acquiring and releasing a lock surrounding each * task execution. This protects against interrupts that are * intended to wake up a worker thread waiting for a task from * instead interrupting a task being run. We implement a simple * non-reentrant mutual exclusion lock rather than use * ReentrantLock because we do not want worker tasks to be able to * reacquire the lock when they invoke pool control methods like * setCorePoolSize. Additionally, to suppress interrupts until * the thread actually starts running tasks, we initialize lock * state to a negative value, and clear it upon start (in * runWorker). * * Worker类大体上管理着运行线程的中断状态 和 一些指标 * Worker类投机取巧的继承了AbstractQueuedSynchronizer来简化在执行任务时的获取、释放锁 * 这样防止了中断在运行中的任务,只会唤醒(中断)在等待从workQueue中获取任务的线程 * 解释: * 为什么不直接执行execute(command)提交的command,而要在外面包一层Worker呢?? * 主要是为了控制中断 * 用什么控制?? * 用AQS锁,当运行时上锁,就不能中断,TreadPoolExecutor的shutdown()方法中断前都要获取worker锁 * 只有在等待从workQueue中获取任务getTask()时才能中断 * worker实现了一个简单的不可重入的互斥锁,而不是用ReentrantLock可重入锁 * 因为我们不想让在调用比如setCorePoolSize()这种线程池控制方法时可以再次获取锁(重入) * 解释: * setCorePoolSize()时可能会interruptIdleWorkers(),在对一个线程interrupt时会要w.tryLock() * 如果可重入,就可能会在对线程池操作的方法中中断线程,类似方法还有: * setMaximumPoolSize() * setKeppAliveTime() * allowCoreThreadTimeOut() * shutdown() * 此外,为了让线程真正开始后才可以中断,初始化lock状态为负值(-1),在开始runWorker()时将state置为0,而state>=0才可以中断 * * * Worker继承了AQS,实现了Runnable,说明其既是一个可运行的任务,也是一把锁(不可重入) */ private final class Worker extends AbstractQueuedSynchronizer implements Runnable { /** * This class will never be serialized, but we provide a * serialVersionUID to suppress a javac warning. */ private static final long serialVersionUID = 6138294804551838833L; /** Thread this worker is running in. Null if factory fails. */ final Thread thread;//利用ThreadFactory和 Worker这个Runnable创建的线程对象 /** Initial task to run. Possibly null. */ Runnable firstTask; /** Per-thread task counter */ volatile long completedTasks; /** * Creates with given first task and thread from ThreadFactory. * @param firstTask the first task (null if none) */ Worker(Runnable firstTask) { //设置AQS的同步状态private volatile int state,是一个计数器,大于0代表锁已经被获取 setState(-1); // inhibit interrupts until runWorker // 在调用runWorker()前,禁止interrupt中断,在interruptIfStarted()方法中会判断 getState()>=0 this.firstTask = firstTask; this.thread = getThreadFactory().newThread(this); //根据当前worker创建一个线程对象 //当前worker本身就是一个runnable任务,也就是不会用参数的firstTask创建线程,而是调用当前worker.run()时调用firstTask.run() } /** Delegates main run loop to outer runWorker */ public void run() { runWorker(this);//runWorker()是ThreadPoolExecutor的方法 } // Lock methods // // The value 0 represents the unlocked state. 0代表“没被锁定”状态 // The value 1 represents the locked state. 1代表“锁定”状态 protected boolean isHeldExclusively() { return getState() != 0; } /** * 尝试获取锁 * 重写AQS的tryAcquire(),AQS本来就是让子类来实现的 */ protected boolean tryAcquire(int unused) { //尝试一次将state从0设置为1,即“锁定”状态,但由于每次都是state 0->1,而不是+1,那么说明不可重入 //且state==-1时也不会获取到锁 if (compareAndSetState(0, 1)) { setExclusiveOwnerThread(Thread.currentThread());//设置exclusiveOwnerThread=当前线程 return true; } return false; } /** * 尝试释放锁 * 不是state-1,而是置为0 */ protected boolean tryRelease(int unused) { setExclusiveOwnerThread(null); setState(0); return true; } public void lock() { acquire(1); } public boolean tryLock() { return tryAcquire(1); } public void unlock() { release(1); } public boolean isLocked() { return isHeldExclusively(); } /** * 中断(如果运行) * shutdownNow时会循环对worker线程执行 * 且不需要获取worker锁,即使在worker运行时也可以中断 */ void interruptIfStarted() { Thread t; //如果state>=0、t!=null、且t没有被中断 //new Worker()时state==-1,说明不能中断 if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) { try { t.interrupt(); } catch (SecurityException ignore) { } } } }Worker类 Worker类本身既实现了Runnable,又继承了AbstractQueuedSynchronizer(以下简称AQS),所以其既是一个可执行的任务,又可以达到锁的效果 new Worker()
- 1、将AQS的state置为-1,在runWoker()前不允许中断
- 2、待执行的任务会以参数传入,并赋予firstTask
- 3、用Worker这个Runnable创建Thread
之所以Worker自己实现Runnable,并创建Thread,在firstTask外包一层,是因为要通过Worker控制中断,而firstTask这个工作任务只是负责执行业务 Worker控制中断主要有以下几方面:
- 1、初始AQS状态为-1,此时不允许中断interrupt(),只有在worker线程启动了,执行了runWoker(),将state置为0,才能中断
不允许中断体现在:
- A、shutdown()线程池时,会对每个worker tryLock()上锁,而Worker类这个AQS的tryAcquire()方法是固定将state从0->1,故初始状态state==-1时tryLock()失败,没发interrupt()
- B、shutdownNow()线程池时,不用tryLock()上锁,但调用worker.interruptIfStarted()终止worker,interruptIfStarted()也有state>0才能interrupt的逻辑
- 2、为了防止某种情况下,在运行中的worker被中断,runWorker()每次运行任务时都会lock()上锁,而shutdown()这类可能会终止worker的操作需要先获取worker的锁,这样就防止了中断正在运行的线程
Worker实现的AQS为不可重入锁,为了是在获得worker锁的情况下再进入其它一些需要加锁的方法
Worker和Task的区别: Worker是线程池中的线程,而Task虽然是runnable,但是并没有真正执行,只是被Worker调用了run方法,后面会看到这部分的实现。
4、runWorker() -- 执行任务
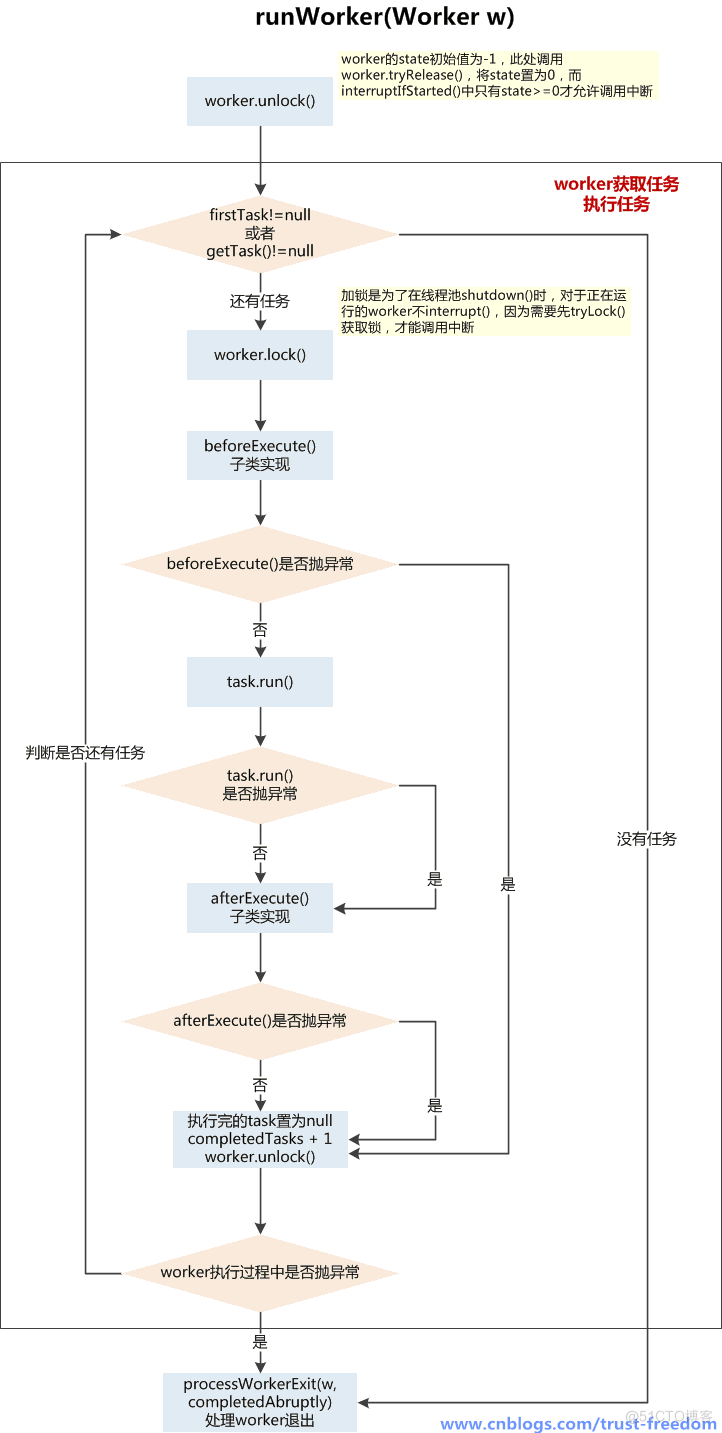
runWorker(Worker w) 执行流程:
- 1、Worker线程启动后,通过Worker类的run()方法调用runWorker(this)
- 2、执行任务之前,首先worker.unlock(),将AQS的state置为0,允许中断当前worker线程
- 3、开始执行firstTask,调用task.run(),在执行任务前会上锁wroker.lock(),在执行完任务后会解锁,为了防止在任务运行时被线程池一些中断操作中断
- 4、在任务执行前后,可以根据业务场景自定义beforeExecute() 和 afterExecute()方法
- 5、无论在beforeExecute()、task.run()、afterExecute()发生异常上抛,都会导致worker线程终止,进入processWorkerExit()处理worker退出的流程
- 6、如正常执行完当前task后,会通过getTask()从阻塞队列中获取新任务,当队列中没有任务,且获取任务超时,那么当前worker也会进入退出流程
使用线程池的注意点
- 避免任务堆积
- 避免线程数过度增加
- 排查线程泄露
参考: https://www.cnblogs.com/zhujiabin/p/5404771.html
https://www.cnblogs.com/ConstXiong/p/11686330.html
https://www.cnblogs.com/gxlaqj/p/11719681.html
https://www.jb51.net/article/170826.htm
https://www.cnblogs.com/trust-freedom/p/6681948.html