前言
Hystrix请求合并用于应对服务器的高并发场景,通过合并请求,减少线程的创建和使用,降低服务器请求压力,提高在高并发场景下服务的吞吐量和并发能力
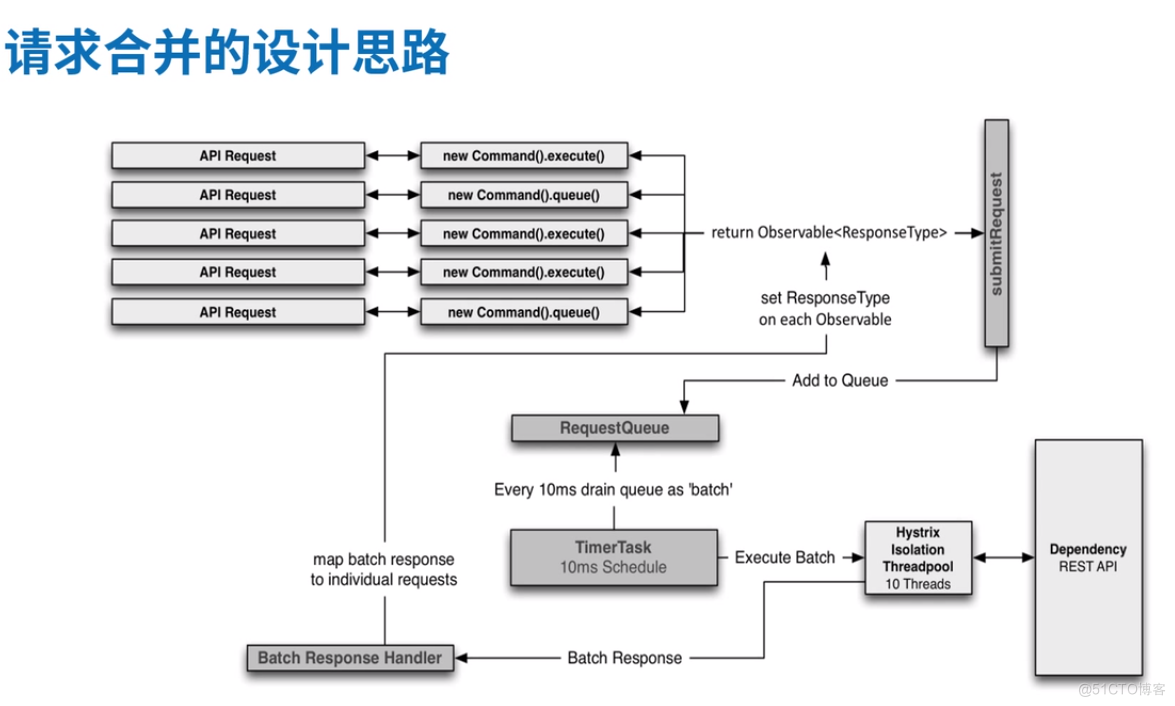
在正常的分布式请求中,客户端发送请求,服务器在接受请求后,向服务提供者发送请求获取数据,这种模式在高并发的场景下就会导致线程池有大量的线程处于等待状态,从而导致响应缓慢,同时线程池的资源也是有限的,每一个请求都分配一个资源,也是无谓的消耗了很多服务器资源,在这种场景下我们可以通过使用hystrix的请求合并来降低对提供者过多的访问,减少线程池资源的消耗,从而提高系统的吞吐量和响应速度,如下图,采用请求合并后的服务模式
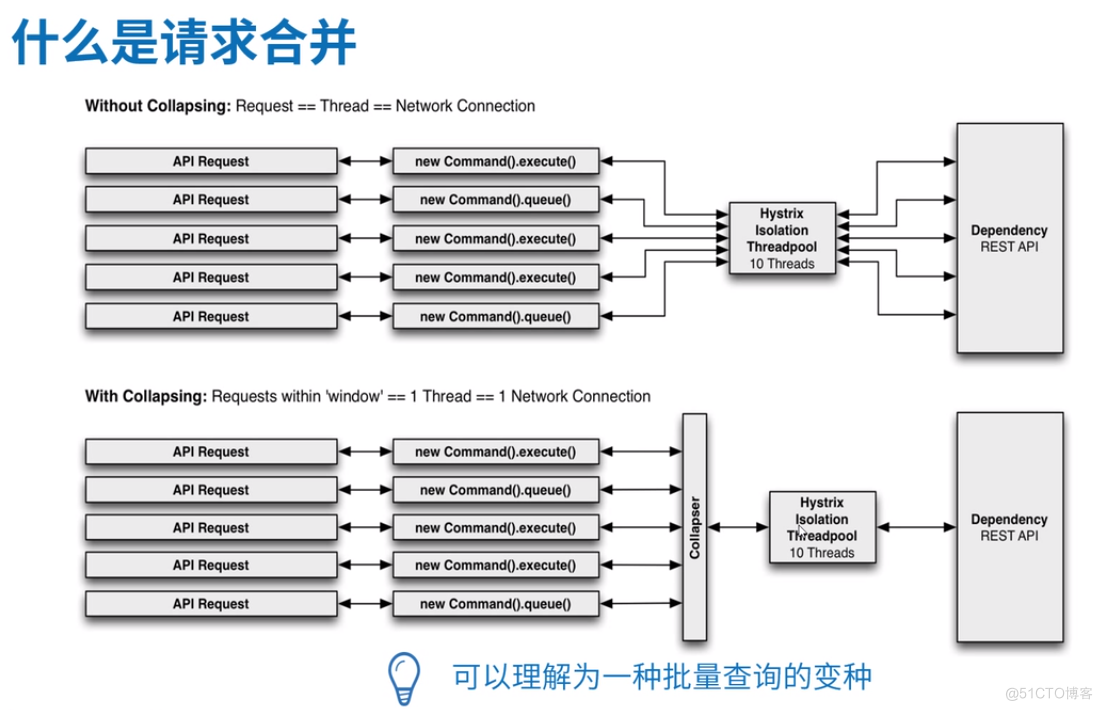
Hystrix请求合并可以通过构建类和添加注解的方式实现,这里我们先说通过构建合并类的方式实现请求合并
请求合并的实现类 请求合并的实现包含了两个主要实现类,一个是合并请求类,一个是批量处理类,合并请求类的作用是收集一定时间内的请求,将他们传递的参数汇总,然后调用批量处理类,通过向服务调用者发送请求获取批量处理的结果数据,最后在对应的request方法体中依次封装获取的结果,并返回回去
构建合并类的方式实现请求合并
首先服务消费方的具体实现
@Service public class OrderServiceImpl implements OrderService { @Reference(version = "1.0.0", application = "${dubbo.application.id}", check = false, timeout = 3000, retries = 0//默认值2不包含第一次,retries=0 禁用超时重试,一般读请求,允许重试三次,写请求下游接口没做幂等就不要重试 ) private StoreService storeService; @Override public Order findById(String id) { Order order = new Order(); String goodsId = storeService.findById(id); order.setGoodsId(goodsId); return order; } @Override public List<Order> batchQuery(List<String> ids) { List<Order> orders = new ArrayList<>(); List<String> list = storeService.batchQuery(ids); for (String storeId : list) { Order order = new Order(); order.setGoodsId(storeId); orders.add(order); } return orders; } }请求合并类的具体实现
/** * 创建OrderCollapseCommand继承自HystrixCollapser来实现请求合并 */ public class OrderCollapseCommand extends HystrixCollapser<List<Order>, Order, String> { private OrderService orderService; private String id; /** * 构造方法中,我们设置了请求时间窗为100ms,即请求时间间隔在100ms之内的请求会被合并为一个请求 * @param orderService 调用的服务 * @param id 单次需要传递的业务id */ public OrderCollapseCommand(OrderService orderService, String id) { super(Setter.withCollapserKey(HystrixCollapserKey.Factory.asKey("bookCollapseCommand")).andCollapserPropertiesDefaults(HystrixCollapserProperties.Setter().withTimerDelayInMilliseconds(100))); this.orderService = orderService; this.id = id; } @Override public String getRequestArgument() { return id; } /** * createCommand方法主要用来合并请求,在这里获取到各个单个请求的id,将这些单个的id放到一个集合中, * 然后再创建出一个OrderBatchCommand对象,用该对象去发起一个批量请求 * @param collection * @return */ @Override protected HystrixCommand<List<Order>> createCommand(Collection<CollapsedRequest<Order, String>> collection) { List<String> ids = new ArrayList<>(collection.size()); ids.addAll(collection.stream().map(CollapsedRequest::getArgument).collect(Collectors.toList())); OrderBatchCommand orderBatchCommand = new OrderBatchCommand(ids, orderService); return orderBatchCommand; } /** * mapResponseToRequests方法主要用来为每个请求设置请求结果。 * 该方法的第一个参数batchResponse表示批处理请求的结果,第二个参数collapsedRequests则代表了每一个被合并的请求, * 然后我们通过遍历batchResponse来为collapsedRequests设置请求结果 * @param orders 这里是批处理后返回的结果集 * @param collection 所有被合并的请求 */ @Override protected void mapResponseToRequests(List<Order> orders, Collection<CollapsedRequest<Order, String>> collection) { int count = 0; for (CollapsedRequest<Order, String> collapsedRequest : collection) { //从批响应集合中按顺序取出结果 Order order = orders.get(count++); //将结果放回原Request的响应体内 collapsedRequest.setResponse(order); } } }通过创建构造方法来设置合并器的收集时间,也就是合并器一次收集客户端请求的时间是多久,然后通过收集请求器获取在这段时间内收集的所有请求参数,在传递给批量执行程序去批量执行,mapResponseToRequests方法获取返回的结果,并根据对应的request请求将结果返回到对应的request请求中
批量处理类
继承自HystrixCommand,用来处理合并之后的请求,在run方法中调用orderService中的batchQuery方法
/** * @Description: 批量处理类,继承自HystrixCommand,用来处理合并之后的请求,在run方法中调用orderService中的batchQuery方法 */ public class OrderBatchCommand extends HystrixCommand<List<Order>> { private List<String> ids; private OrderService orderService; protected OrderBatchCommand(List<String> ids,OrderService orderService) { super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("CollapsingGroup")) .andCommandKey(HystrixCommandKey.Factory.asKey("CollapsingKey"))); this.ids = ids; this.orderService = orderService; } /** * 调用批量处理的方法 * @return * @throws Exception */ @Override protected List<Order> run() throws Exception { return orderService.batchQuery(ids); } }API调用实现请求合并
@RestController @Slf4j public class HelloController { @Autowired private OrderService orderService; @GetMapping("/find/{id}") public Order findOrder(@PathVariable("id") String id) throws ExecutionException, InterruptedException { HystrixRequestContext context = HystrixRequestContext.initializeContext(); OrderCollapseCommand orderCollapseCommand = new OrderCollapseCommand(orderService, id); Future<Order> future = orderCollapseCommand.queue(); return future.get(); } }关于这个API调用我说如下两点:
- 1、首先要初始化HystrixRequestContext
- 2、创建OrderCollapseCommand类的实例来发起请求
通过注解实现请求合并
OK,上面这种请求合并方式写起来稍微有一点麻烦,我们可以使用注解来更优雅的实现这一功能。
首先在OrderService中添加两个方法,如下:
@Service public class OrderServiceImpl implements OrderService { @Reference(version = "1.0.0", application = "${dubbo.application.id}", check = false, timeout = 3000, retries = 0//默认值2不包含第一次,retries=0 禁用超时重试,一般读请求,允许重试三次,写请求下游接口没做幂等就不要重试 ) private StoreService storeService; @HystrixCollapser(batchMethod = "findByIdBatch", collapserProperties = { @HystrixProperty(name ="timerDelayInMilliseconds",value = "100"),//单个请求的延迟时间 @HystrixProperty(name ="maxRequestsInBatch",value = "50"),//允许最大的合并请求数量 @HystrixProperty(name ="requestCache.enabled",value = "false")//是否允许开启请求的本地缓存 }) @Override public Future<Order> findById(String id) { return null; } @HystrixCommand public List<Order> findByIdBatch(List<String> ids) { List<Order> orders = new ArrayList<>(); List<String> list = storeService.findByIdBatch(StringUtils.join(ids,",")); for (String storeId : list) { Order order = new Order(); order.setGoodsId(storeId); orders.add(order); } return orders; } }在findById方法上添加@HystrixCollapser注解实现请求合并,用findByIdBatch属性指明请求合并后的处理方法,collapserProperties属性指定其他属性。
API调用实现请求合并
@RestController @Slf4j public class HelloController { @Autowired private OrderService orderService; @GetMapping("/get/{id}") public Order getOrder(@PathVariable("id") String id) throws ExecutionException, InterruptedException { HystrixRequestContext context = HystrixRequestContext.initializeContext(); Future<Order> future = orderService.findById(id); return future.get(); } }请求合并的优点小伙伴们已经看到了,多个请求被合并为一个请求进行一次性处理,可以有效节省网络带宽和线程池资源,但是,有优点必然也有缺点。
弊端:
启用合并请求的的成本是执行实际逻辑之前增加的延迟 如果平均只需要5ms的执行时间,放在一个10ms做一次批处理的合并场景下,最坏的情况下执行时间可能变为15ms,所以不适合低延迟的RPC场景,也不适合低并发场景。
场景:
而如果一个特定的查询同时被大量使用,并且可以将几十甚至数百个批处理在一起,那么如果能接受处理时间变长一点点,以达到减少网络连接数,那这还是值得的(典型如数据库、http接口),另外高并发也是请求合并的一个非常重要的场景。
参考:
https://segmentfault.com/a/1190000011468804
https://www.jianshu.com/p/8f5d1fd6d601