写在前面: 博主是一名大数据的初学者,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白,写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和自己一样处于起步阶段的萌新。由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!个人小站:http://alices.ibilibili.xyz/尽管当前水平可能不及各位大佬,但我还是希望自己能够做得更好,因为一天的生活就是一生的缩影。我希望在最美的年华,做最好的自己!
在正式开始之前,我们先来看看一个倒排索引的例子。  而具体什么是倒排索引?这里引用一下维基百科上的定义:
而具体什么是倒排索引?这里引用一下维基百科上的定义:
倒排索引(英语:Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。有两种不同的反向索引形式:
一条记录的水平反向索引(或者反向档案索引)包含每个引用单词的文档的列表。
一个单词的水平反向索引(或者完全反向索引)又包含每个单词在一个文档中的位置。
后者的形式提供了更多的兼容性(比如短语搜索),但是需要更多的时间和空间来创建。
倒排索引在搜索引擎中比较常见,百度,谷歌等大型互联网搜索引擎提供商均在搜索引擎业务中构建了倒序索引。本篇文章,就用一个简单的demo教大家如何使用Hadoop实现倒序索引。
需求
现在有3个文件,分别为 log_a.txt ,log_b.txt 和 log_c.txt,每个文件的内容如下所示:
log_a.txthello javahello hadoophello javalog_b.txthello hadoophello hadoopjava hadooplog_c.txthello hadoophello java要求经过 Hadoop 的处理后,输出如下信息:
hadoop log_c.txt-->1 log_b.txt-->3 log_a.txt-->1hello log_c.txt-->2 log_b.txt-->2 log_a.txt-->3java log_c.txt-->1 log_b.txt-->1 log_a.txt-->2需求分析
为了实现这种效果,我们可以很自然想到用MapReduce去处理。但是考虑到只用一个MapReduce处理,代码会写的比较冗长,可读性不强,对于新手小白不是很友好。于是本篇文章,作者介绍的就是如何通过两个MapReduce来实现“倒排索引”的功能!
主要思路如下:
倒排索引第一步的Mapper类
context.wirte("hadoop->log_a.txt", "1") context.wirte("hadoop->log_b.txt", "1") context.wirte("hadoop->log_c.txt", "1") ...
倒排索引第一步的Reducer :
hello --> log_a.txt 3 hello --> log_b.txt 2 hello --> log_c.txt 2 ...
倒排索引第二步的mapper:
hello --> log_a.txt 3 hello-->log_b.txt 2 hello-->log_c.txt 2 ...
倒排索引第二步的Reducer:
hello log_c.txt-->2 log_b.txt-->2 log_a.txt-->3
hadoop log_c.txt-->1 log_b.txt-->3 log_a.txt-->1
java log_c.txt-->1 log_b.txt-->1 log_a.txt-->2
好了,现在需求明确了,现在我们可以写代码了。
这是倒排索引第一步的Mapper:InverseIndexStepOneMapper
package io.alice;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.lib.input.FileSplit;import java.io.IOException;/** * @Author: Alice菌 * @Date: 2020/10/4 20:38 * @Description: * 读取文件的格式: * log_a.txt * hello java * hello hadoop * hello java * * 倒排索引第一步的Mapper类, * 输出结果如下: * context.wirte("hadoop->log_a.txt", "1") * context.wirte("hadoop->log_b.txt", "1") * context.wirte("hadoop->log_c.txt", "1") */public class InverseIndexStepOneMapper extends Mapper<LongWritable, Text,Text,LongWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { if (value != null){ // 获取一行的数据 String line = value.toString(); // 按照空格拆分每个单词 String[] words = line.split(" "); if (words.length > 0){ // 获取数据的切片信息,并根据切片信息获取到文件的名称 FileSplit fileSplit = (FileSplit)context.getInputSplit(); String fileName = fileSplit.getPath().getName(); for (String word : words) { context.write(new Text(word + "-->" + fileName),new LongWritable(1)); } } } }}倒排索引第一步的Reducer,InverseIndexStepOneReducer
package io.alice;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/** * @Author: Alice菌 * @Date: 2020/10/4 20:47 * @description: 完成倒排索引第一步的Reducer程序 * 最终输出结果为: * hello-->log_a.txt 3 * hello-->log_b.txt 2 * hello-->log_c.txt 2 * hadoop-->log_a.txt 1 * hadoop-->log_b.txt 3 * hadoop-->log_c.txt 1 * java-->log_a.txt 2 * java-->log_b.txt 1 * java-->log_c.txt 1 */public class InverseIndexStepOneReducer extends Reducer<Text, LongWritable,Text,LongWritable> { @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { if (values != null){ // 初始化一个变量 sum ,保存每个单词在每个文件中出现的次数 long sum = 0; for (LongWritable value : values) { sum += value.get(); } context.write(key,new LongWritable(sum)); } }}这是倒排索引第二步的Mapper:InverseIndexStepTwoMapper
package io.alice;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/** * @Author: Alice菌 * @Date: 2020/10/4 21:03 * @Description: 完成倒排索引第二步的mapper程序 * * * hello-->log_a.txt 3 * hello-->log_b.txt 2 * hello-->log_c.txt 2 * hadoop-->log_a.txt 1 * hadoop-->log_b.txt 3 * hadoop-->log_c.txt 1 * java-->log_a.txt 2 * java-->log_b.txt 1 * java-->log_c.txt 1 * * 输出的信息为: * context.write("hadoop", "log_a.txt->1") * context.write("hadoop", "log_b.txt->3") * context.write("hadoop", "log_c.txt->1") * * context.write("hello", "log_a.txt->3") * context.write("hello", "log_b.txt->2") * context.write("hello", "log_c.txt->2") * * context.write("java", "log_a.txt->2") * context.write("java", "log_b.txt->1") * context.write("java", "log_c.txt->1") */public class InverseIndexStepTwoMapper extends Mapper<LongWritable, Text,Text,Text> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { if (value != null){ String line = value.toString(); // 将第一步的Reduce输出结果按照 \t 拆分 String[] fields = line.split("\t"); // 将拆分后的结果数组的第一个元素再按照 --> 分隔 String[] wordAndFileName = fields[0].split("-->"); // 获取到单词 String word = wordAndFileName[0]; // 获取到文件名 String fileName = wordAndFileName[1]; // 获取到单词数量 long count = Long.parseLong(fields[1]); context.write(new Text(word),new Text(fileName + "-->" + count)); } }}倒排索引第二步的Reducer,InverseIndexStepTwoReducer
package io.alice;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/** * @Author: Alice菌 * @Date: 2020/10/4 21:21 * @Description: 完成倒排索引第二步的Reducer程序 * 得到的输入信息格式为: * <"hello", {"log_a.txt->3", "log_b.txt->2", "log_c.txt->2"}> * * 最终输出结果如下: * * hello log_c.txt-->2 log_b.txt-->2 log_a.txt-->3 * hadoop log_c.txt-->1 log_b.txt-->3 log_a.txt-->1 * java log_c.txt-->1 log_b.txt-->1 log_a.txt-->2 */public class InverseIndexStepTwoReducer extends Reducer<Text,Text,Text,Text> { @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { if (values != null){ String result = ""; for (Text value : values) { result = result.concat(value.toString()).concat(" "); } context.write(key,new Text(result)); } }}倒排索引的执行类:InverseIndexRunner
这里需要格外的注意,因为我们平时接触到的MapReduce程度大多都是由一个Job完成的,本次案例在执行类中如何实现多个Job依次执行,大家可以借鉴学习!
package io.alice;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.conf.Configured;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.Tool;import org.apache.hadoop.util.ToolRunner;import java.io.IOException;/**io.alice.InverseIndexRunner * @Author: Alice菌 * @Date: 2020/10/4 21:39 * @Description: 倒排索引的执行类 */public class InverseIndexRunner extends Configured implements Tool { public static void main(String[] args) throws Exception { ToolRunner.run(new Configuration(),new InverseIndexRunner(),args); } public int run(String[] args) throws Exception { if (!runStepOneMapReduce(args)) { return 1; } return runStepTwoMapReduce(args) ? 0:1; } private static boolean runStepOneMapReduce(String[] args) throws Exception { Job job = getJob(); job.setJarByClass(InverseIndexRunner.class); job.setMapperClass(InverseIndexStepOneMapper.class); job.setReducerClass(InverseIndexStepOneReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); return job.waitForCompletion(true); } private static boolean runStepTwoMapReduce(String []args) throws Exception { Job job = getJob(); job.setJarByClass(InverseIndexRunner.class); job.setMapperClass(InverseIndexStepTwoMapper.class); job.setReducerClass(InverseIndexStepTwoReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job,new Path(args[1] + "/part-r-00000")); FileOutputFormat.setOutputPath(job,new Path(args[2])); return job.waitForCompletion(true); } private static Job getJob() throws IOException { Configuration conf = new Configuration(); return Job.getInstance(conf); }}测试执行
我们将项目打成jar包上传至linux
 然后将数据源所需要的文件上传至HDFS
然后将数据源所需要的文件上传至HDFS 然后执行命令:
然后执行命令:
hadoop jar /home/hadoop/alice_data-1.0-SNAPSHOT.jar io.alice.InverseIndexRunner /data/input /data/oneoutput /data/twooutput
程序就开始 奔跑 起来~
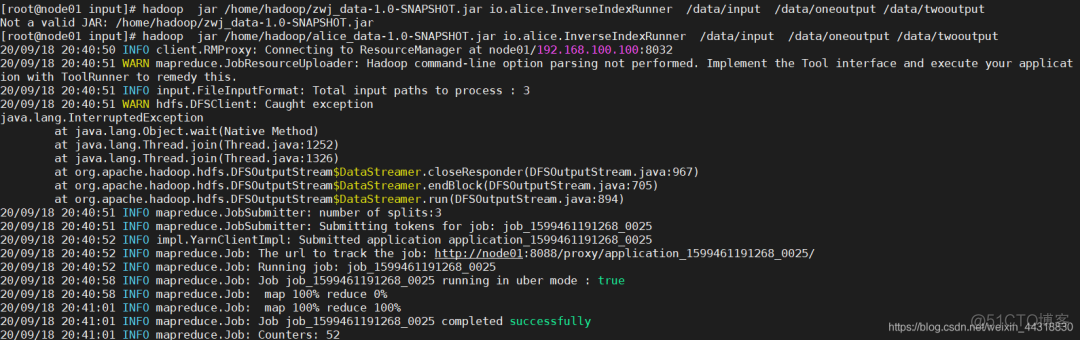
待到程序运行完毕,我们可以查看程序正确运行后的结果

看到最后的效果跟我们题目需求所想要的完全一致时,就说明我们的思路是没错滴~

小结
我们每向他人学习到一项新的技能,一定要主动去思考别人解决问题的出发点,只有学会思考,才能举一反三,融会贯通!
本篇文章就到这里,更多精彩文章及福利,敬请关注博主原创公众号【猿人菌】!
扫码关注

关注即可获取高质量思维导图,互联网一线大厂面经,大数据珍藏精品书籍...期待您的关注!