一、Pulsar Connector 连接器
虽然可以使用 Pulsar 消费者和生产者 API 编写代码(例如,从数据库同步数据时,先查询数据,再使用Pulsar 的 API 将数据发布至 Pulsar),但这种方法耗时费力。因此,Pulsar 提出了Connector (也称为Pulsar IO),用于解决 Pulsar 与周边系统的集成问题,帮助用户高效完成工作。

这张图非常直观地描述了 Pulsar IO 的组成。 Pulsar IO 分为输入(Input)和输出(Output)两个模块。
- 输入:代表数据从哪里来,通过 Source 实现数据输入。数据的来源可以是数据库(例如MySQL、Oracle、MongoDB)、文件、日志或自定义系统等。
- 输出:代表数据往哪里去,通过 Sink 实现数据输出。数据的输出可以是数据仓库、数据库等。
而目前Pulsar支持非常多的Connector. 有兴趣的可以参考以下几个网站: http://pulsar.apache.org/docs/zh-CN/io-connectors/#source-connector http://pulsar.apache.org/docs/zh-CN/io-connectors/#sink-connector 目前我们主要介绍 Pulsar flink Connector 和 Pulsar Flume Connector 其他的连接器的使用方式, 基本是类似的
当前 Apache Pulsar 支持很多 Connector,以下是相关简介:
source
-
Alibaba Canal CDC Source(https://github.com/alibaba/canal):从 Canal 同步 MySQL 数据到 Pulsar
-
Apache Kafka Source(https://kafka.apache.org/):从 Kafka 同步数据到 Pulsar ,或者从 Pulsar 同步数据到 Kafka
-
Debezium Source(https://debezium.io/):从 Debezium 同步数据到 Pulsar,当前支持 MySQL 和 PostgreSQL
-
Elastic Beat Source(https://github.com/streamnative/pulsar-beat-ouput):从 Elastic Beat 搜集日志数据同步到 Pulsar
-
Flume Source(https://github.com/streamnative/pulsar-flume-ng-sink):从 Flume 搜集日志数据并同步到 Pulsar
-
RabbitMQ Source(https://www.rabbitmq.com/):从 RabbitMQ 同步数据到 Pulsar
-
TCP/UDP with Netty Source(https://netty.io/):从 Netty 同步数据到 Pulsar
-
File Source(https://github.com/apache/pulsar/blob/master/pulsar-io/file):从文件同步数据到 Pulsar
Sink
-
Aerospike Sink(https://www.aerospike.com/):从 Pulsar 同步数据到 Aerospike
-
Apache Cassandra Sink(https://cassandra.apache.org/):从 Pulsar 同步数据到 Cassandra
-
Apache HDFS v2 Sink(https://hadoop.apache.org/):从 Pulsar 同步数据到 HDFS
-
Apache HDFS v3 Sink(https://hadoop.apache.org/):从 Pulsar 同步数据到 HDFS
-
Apache Kafka Sink(https://kafka.apache.org/):从 Pulsar 同步数据到 Kafka
-
AWS Kinesis Sink(https://aws.amazon.com/cn/kinesis/):从 Pulsar 同步数据到 Kinesis
-
Elastic Search Sink(https://www.elastic.co/):从 Pulsar 同步数据到 Elastic Search
-
HBase Sink(https://hbase.apache.org/):从 Pulsar 同步数据到 HBase
-
InfluxDB Sink(https://www.influxdata.com/):从 Pulsar 同步数据到 InfluxDB
-
JDBC Sink(https://github.com/apache/pulsar/tree/master/pulsar-io/jdbc):从 Pulsar 同步数据,并通过 JDBC 输出,当前支持输出到 MySQL 和 SQLite
-
MongoDB Sink(https://www.mongodb.com/):从 Pulsar 同步数据到 MongoDB
-
RabbitMQ Sink(https://www.rabbitmq.com/):从 Pulsar 同步数据到 RabbitMQ
-
Redis Sink(https://redis.io/):从 Pulsar 同步数据到 Redis
-
Solr Sink(http://lucene.apache.org/solr/):从 Pulsar 同步数据到 Solr
-
Twitter Firehose Sink(https://developer.twitter.com/en/docs):从 Pulsar 同步数据到 Twitter FireHose
二、Apache Flink 简介
Apache Flink 是⼀个在⽆界和有界数据流上进⾏状态计算的框架和分布式处理引擎,这几年内比较火。Flink 可以在所有常⻅的集群环境中运⾏,并以 in-memory 的速度和任意的规模进⾏计算。
Flink 的框架大致可以分为三块内容,从左到右依次为:数据输入、Flink 数据处理、数据输出。Pulsar Flink connector 对 Flink 中间的数据处理部分做了相当完备的支持。
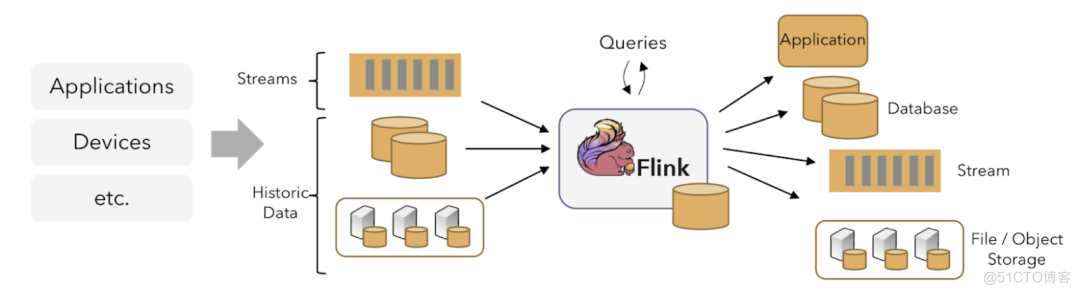
Pulsar 和 Flink 都是当下比较出色的计算框架,Apache Flink 是当下最流⾏的数据计算引擎,Apache Pulsar 是消息订阅系统中的翘楚。
Pulsar 跟 Flink 有一些相同的特性,比如它们的批处理都是有界的数据流。目前 Pulsar 跟 Flink 的集成方式有多种。
-
使⽤流式连接器(Streaming Connectors)⽀持流式⼯作负载;
-
使⽤批式源连接器(Batch Source Connectors)⽀持批式⼯作负载;
-
Pulsar 还提供了对 Schema 的原⽣⽀持,可以与 Flink 集成并提供对数据的结构化访问,例如,使⽤ Flink SQL 在 Pulsar 中查询数据。
从架构的⻆度来看,我们可以想象两个框架之间的融合,使⽤ Apache Pulsar 作为统⼀的数据层视图,使⽤ Apache Flink 作为统⼀的计算、数据处理框架和 API。
三、Pulsar Flink Connector
目前 Pulsar Flink connector 支持 Flink 1.9 及以上版本,同时支持 Flink Stream、Batch、Table、Catalog 等功能,以及 Pulsar Topic 动态发现和 Pulsar Schema 的功能支持。
Pulsar Flink Connector是Apache Pulsar和Apache Flink(数据处理引擎)的集成,它允许Flink从Pulsar读取数据,并向Pulsar写入数据,并提供精确一次的源语义和至少一次的汇聚语义。

Pulsar Flink connector 在使用上比较简单,由一个 Source 和一个 Sink 组成。Source 的功能是将一个或多个主题下的消息传入到 Flink source 中,Sink 的功能就是从 Flink Sink 中获取数据并放入到某些主题下。
3.1 使用pulsar Flink Connector
Pulsar Connector 在使用上是比较简单的,由一个 Source 和一个 Sink 组成,source 的功能就是将一个或多个主题下的消息传入到 Flink 的Source中,Sink的功能就是从 Flink 的 Sink 中获取数据并放入到某些主题下,在使用方式上,如下所示,与 Kafa Connector 很相似,使用时需要设置一些参数。
3.1.1 首先在pom中加入相关的依赖环境:(注意: 还需要添加pulsar客户端包)
<dependencies> <dependency> <groupId>org.apache.pulsar</groupId> <artifactId>pulsar-client</artifactId> <version>2.10.0</version> </dependency> <dependency> <groupId>org.apache.pulsar</groupId> <artifactId>pulsar-client-all</artifactId> <version>2.10.0</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-common</artifactId> <version>1.15.0</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.24</version> </dependency> <!--flink 和 pulsar 集成相关的包--> <!--flink相关的包--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.15.0</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java</artifactId> <version>1.15.0</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients</artifactId> <version>1.15.0</version> </dependency> <!--pulsar 于 flink的整合包--> <dependency> <groupId>io.streamnative.connectors</groupId> <artifactId>pulsar-flink-connector_2.11</artifactId> <version>2.4.28.7</version> </dependency> </dependencies>3.1.2 source端
import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.pulsar.FlinkPulsarSource; import java.util.Properties; /** * @Author: huangyibo * @Date: 2022/5/29 23:56 * @Description: pulsar 整合 flink 让flink从pulsar中读取消息 */ public class FlinkFromPulsarSource { public static void main(String[] args) throws Exception { //1. 创建Flink的流式计算的核心环境类对象 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2. 添加source源, 用于读取数据 pulsar String serviceUrl = "pulsar://192.168.23.111:6650,192.168.23.112:6650,192.168.23.113:6650"; String adminUrl = "http://192.168.23.111:8080,192.168.23.112:8080,192.168.23.113:8080"; Properties properties = new Properties(); properties.put("topic","persistent://my-tenant/my-ns/my-partitioned-topic"); FlinkPulsarSource<String> pulsarSource = new FlinkPulsarSource<String>(serviceUrl, adminUrl, new SimpleStringSchema(), properties); pulsarSource.setStartFromLatest(); DataStreamSource<String> streamSource = env.addSource(pulsarSource); //3. 添加一下转换处理操作, 对数据进行统计分析 //4. 添加一下sink的组件, 将计算的结果进行输出操作 streamSource.print(); //5. 启动flink程序 env.execute("FlinkFromPulsar"); } }3.1.3 sink端
import com.yibo.pulsar.pojo.User; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.pulsar.FlinkPulsarSink; import org.apache.flink.streaming.connectors.pulsar.FlinkPulsarSource; import org.apache.flink.streaming.connectors.pulsar.TopicKeyExtractor; import org.apache.flink.streaming.connectors.pulsar.internal.AvroDeser; import java.util.Optional; import java.util.Properties; /** * @Author: huangyibo * @Date: 2022/5/31 20:47 * @Description: 基于Flink实现读取一个POJO类型的数据, 将数据写入到Pulsar */ public class FlinkFromPulsarSink { public static void main(String[] args) throws Exception { //1. 创建Flink的流式计算的核心环境类对象 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2. 添加sink源, 用于写入数据到 pulsar String serviceUrl = "pulsar://192.168.23.111:6650,192.168.23.112:6650,192.168.23.113:6650"; String adminUrl = "http://192.168.23.111:8080,192.168.23.112:8080,192.168.23.113:8080"; Properties properties = new Properties(); properties.put("topic","persistent://my-tenant/my-ns/my-partitioned-topic1"); FlinkPulsarSource<User> pulsarSource = new FlinkPulsarSource<>(serviceUrl, adminUrl, AvroDeser.of(User.class), properties); pulsarSource.setStartFromLatest(); DataStreamSource<User> streamSource = env.addSource(pulsarSource); //3. 添加一下转换处理操作, 对数据进行统计分析 streamSource.print(); //4. 添加sink的组件, 将处理后的数据写入到pulsar中 FlinkPulsarSink<User> pulsarSink = new FlinkPulsarSink<User>(serviceUrl, adminUrl, Optional.of("persistent://my-tenant/my-ns/my-partitioned-topic2"),//mandatory target topic properties, TopicKeyExtractor.NULL, //replace this to extract key or topic for each record User.class); streamSource.addSink(pulsarSink); //5. 启动flink程序 env.execute("Flink Connector Pulsar"); } }参考: https://blog.csdn.net/weixin_44904816/article/details/106846608
https://blog.csdn.net/qq_37865420/article/details/115374646
https://blog.csdn.net/zhaijia03/article/details/109766637