目录
- 背景
- 功能介绍
- 代码实现
- 基础代码实现
- 大文件优化
- Stream
- 减少文件传输带宽
- 使用浏览器缓存
- 什么是Etag
- 总结
背景
作为前端工程师,我想大家一定对静态文件服务器不会陌生。所谓的静态文件服务器做的工作就是将我们的前端静态文件(.js/.css/.html)传输给浏览器,然后浏览器再将我们的页面渲染出来。我们常用的webpack-dev-server就是本地开发用的静态文件服务器,而一般线上环境我们会使用nginx,因为它更加稳定和高效。既然静态文件服务器无处不在,那么它们又是如何实现的呢?本篇文章将带你手把手实现一个高效的静态文件服务器。
功能介绍
我们的静态服务器包括下面两个功能:
- 当用户请求的内容是
文件夹时,展示当前文件夹的结构信息 - 当用户请求的内容是
文件时,返回文件的内容
我们来看一下实际效果,服务端的静态文件目录是这样的:
static └── index.html
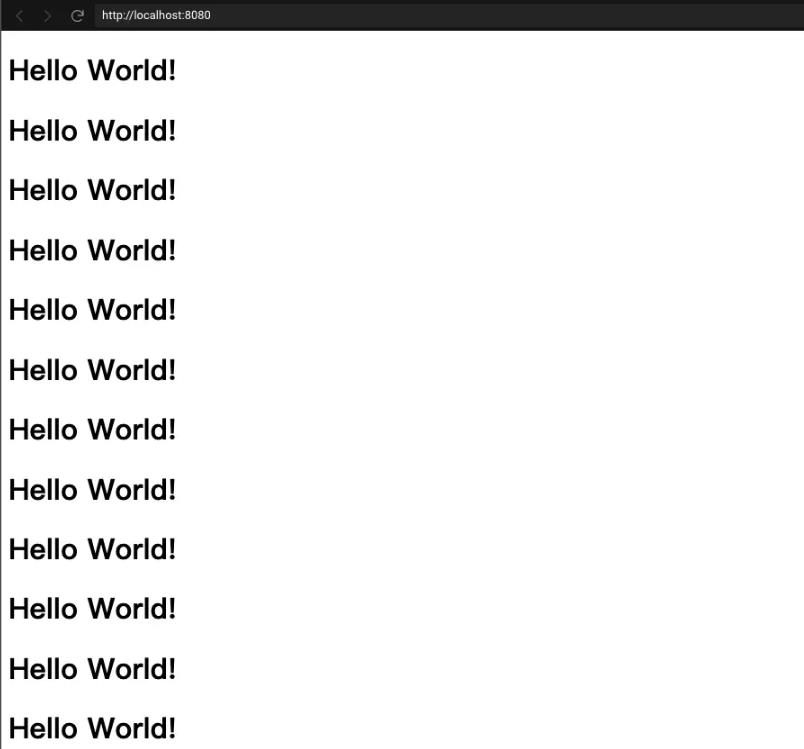
访问localhost:8080可以获取根目录的信息:

在根目录下只有一个index.html文件。我们点击index.html文件可以获取这个文件的具体内容:
代码实现
根据上面的需求描述,我们先用流程图来设计一下我们的逻辑如何实现:
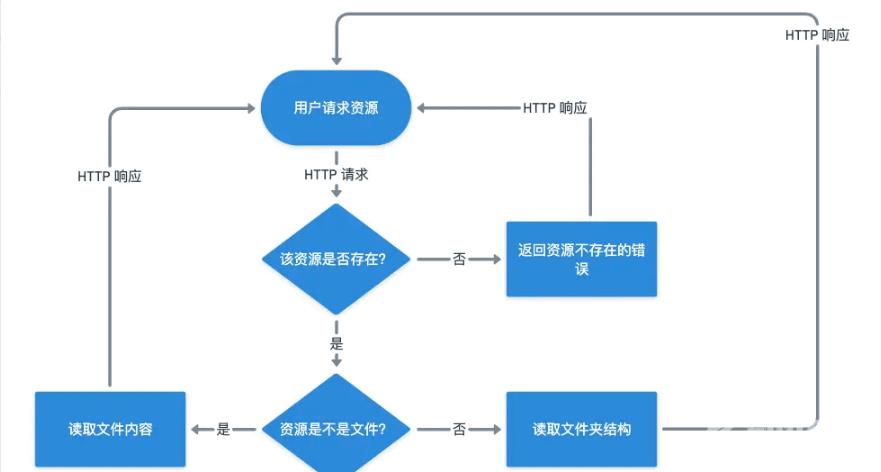
其实静态文件服务器的实现思路还是很简单的:先判断资源存不存在,不存在就直接报错,资源存在的话根据资源的类型返回对应的结果给客户端就可以了。
基础代码实现
看完上面的流程图,我相信大家的思路基本清晰了,接着我们看一下具体的代码实现:
const http = require('http')
const url = require('url')
const fs = require('fs')
const path = require('path')
const process = require('process')
// 获取服务端的工作目录,也就是代码运行的目录
const ROOT_DIR = process.cwd()
const server = http.createServer(async (req, resp) => {
const parsedUrl = url.parse(req.url)
// 删除开头的'/'来获取资源的相对路径,e.g: `/static`变为`static`
const parsedPathname = parsedUrl.pathname.slice(1)
// 获取资源在服务端的绝对路径
const pathname = path.resolve(ROOT_DIR, parsedPathname)
try {
// 读取资源的信息, fs.Stats对象
const stat = await fs.promises.stat(pathname)
if (stat.isFile()) {
// 如果请求的资源是文件就交给sendFile函数处理
sendFile(resp, pathname)
} else {
// 如果请求的资源是文件夹就交给sendDirectory函数处理
sendDirectory(resp, pathname)
}
} catch (error) {
// 访问的资源不存在
if (error.code === 'ENOENT') {
resp.statusCode = 404
resp.end('file/directory does not exist')
} else {
resp.statusCode = 500
resp.end('something wrong with the server')
}
}
})
server.listen(8080, () => {
console.log('server is up and running')
})
在上面的代码中我使用http模块创建了一个server实例,这个实例里面定义了处理所有HTTP请求的handler函数。handler函数实现比较简单,读者根据上面的代码注释就可以看明白了,这里想要说明一下我为什么使用fs.promises.stat来获取资源的元信息(fs.Stats类,包括资源的类型和更改时间等)而不使用可以实现同一个功能的fs.stat和fs.statSync:
fs.promises.stat vs fs.stat:fs.promises.stat是promise-style的,可以使用async和await来实现异步的逻辑,代码很干净。而fs.stat是callback-style的,这种API写异步逻辑最后可能会变成意大利面条,后期维护困难。fs.promises.stat vs fs.statSync:fs.promises.stat读取文件的信息是一个异步操作,不会阻塞主线程的执行。而fs.statSync是同步的,这也就意味着当这个API执行的时候,JS主线程会卡死,其它的资源请求是处理不了的。这里我也建议当大家需要在服务端进行文件系统的读写的时候,一定要优先使用异步API而避免使用同步式的API。
接着我们来看一下sendFile和sendDirectory这两个函数的具体实现:
const sendFile = async (resp, pathname) => {
// 使用promise-style的readFile API异步读取文件的数据,然后返回给客户端
const data = await fs.promises.readFile(pathname)
resp.end(data)
}
const sendDirectory = async (resp, pathname) => {
// 使用promise-style的readdir API异步读取文件夹的目录信息,然后返回给客户端
const fileList = await fs.promises.readdir(pathname, { withFileTypes: true })
// 这里保存一下子资源相对于根目录的相对路径,用于后面客户端继续访问子资源
const relativePath = path.relative(ROOT_DIR, pathname)
// 构造返回的html结构体
let content = '<ul>'
fileList.forEach(file => {
content += `
<li>
<a href=${
relativePath
}/${file.name}>${file.name}${file.isDirectory() ? '/' : ''}
</a>
</li>`
})
content += '</ul>'
// 返回当前的目录结构给客户端
resp.end(`<h1>Content of ${relativePath || 'root directory'}:</h1>${content}`)
}
sendDirectory通过fs.promises.readdir来获取其底下的目录信息,然后以列表的形式返回一个html结构给客户端。这里值得一提的是:由于客户端需要按照返回的子资源信息进一步访问子资源,所以我们需要记录子资源相对于根目录的相对路径。sendFile函数的实现相对于sendDirectory会简单一点,它只需要读取文件的内容然后返回给客户端就可以了。
上面的代码写完后,我们其实已经实现了上面说的需求了,可是这个服务端是生产不可用的,因为它有很多潜在的问题没有解决,接着就让我们看一下如何解决这些问题来优化我们的服务端代码。
大文件优化
我们先来看看在现在的实现下,客户端请求一个大文件会发生什么。首先我们在static文件夹下准备一个大文件test.txt,这个文件里面有1000万行Hello World!,文件的大小为124M:

然后我们启动服务器,查看服务器启动完成后Node的内存占用情况:
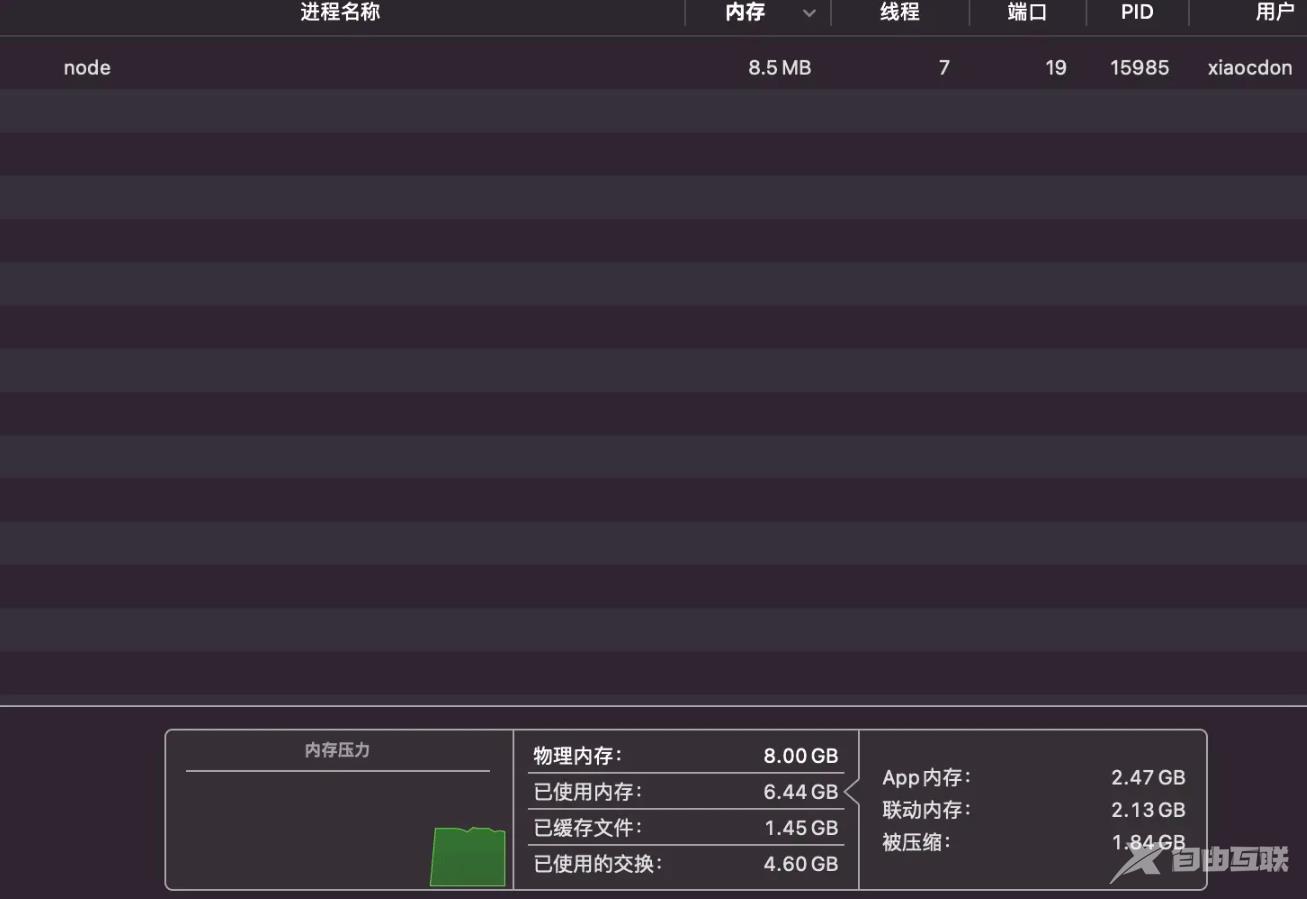
可以看到Node服务只占用了8.5M的内存,我们在浏览器访问一下test.txt:
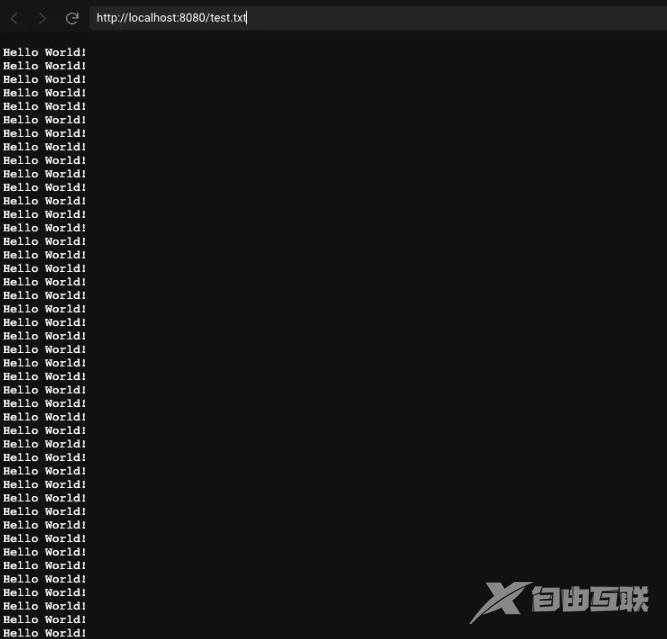
浏览器在疯狂输出Hello World!,这个时候再看一眼Node的内存占用情况:
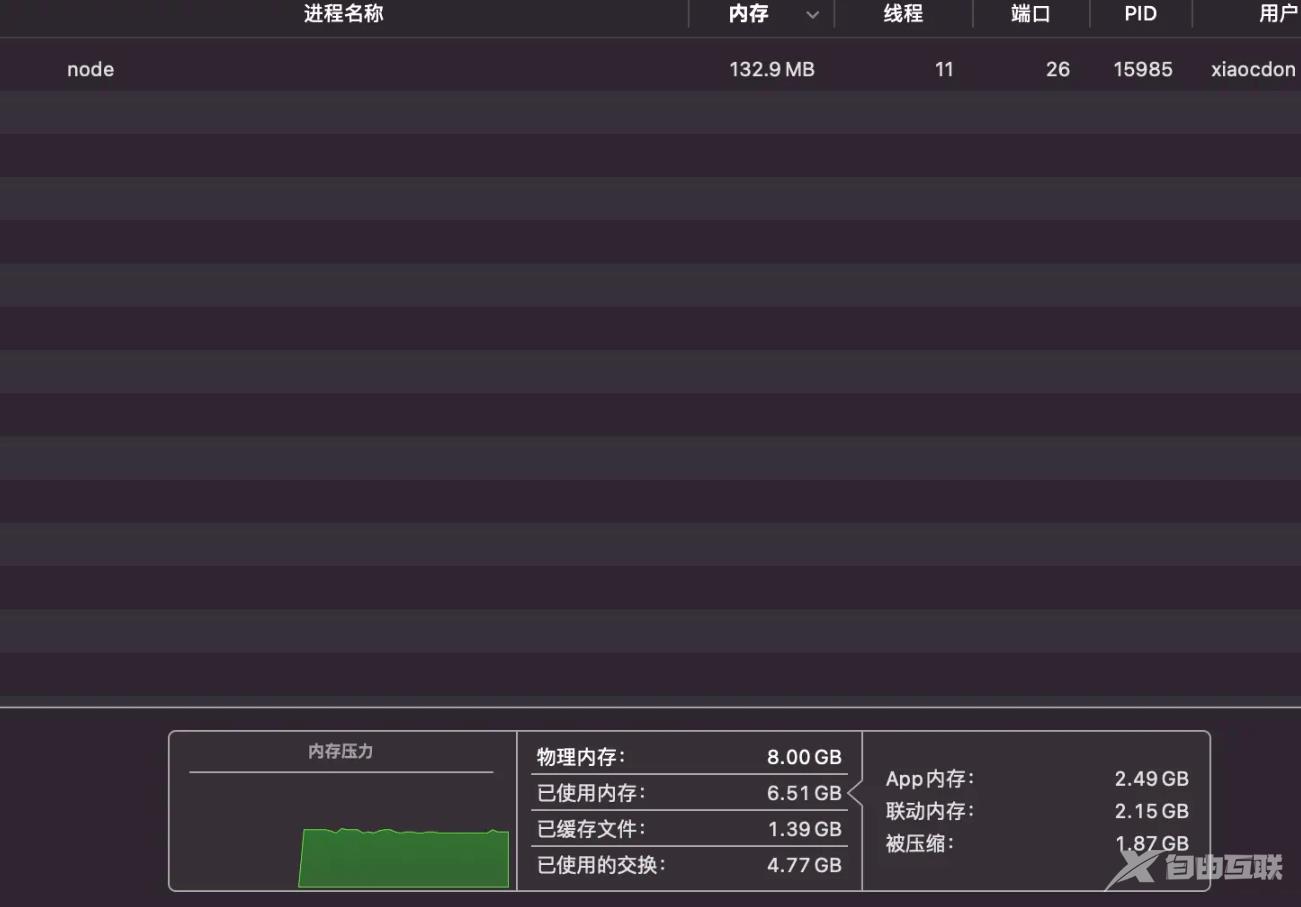
内存使用一下子由8.5M激增到了132.9M,而增加的资源差不多就是文件的大小124M,这到底是为什么呢?我们再来看一下sendFile文件的实现:
const sendFile = async (resp, pathname) => {
// readFile会读取文件的数据然后存在data变量里面
const data = await fs.promises.readFile(pathname)
resp.end(data)
}
上面的代码中,其实我们会一次性读取文件的内容然后保存在data变量里面,也就是说我们会将124M的文本信息保存在内存里面!你试想一下,如果有多个用户同时访问大资源,我们的程序肯定会因为内存爆炸而OOM(Out of Memory)的。那么这个问题如何解决呢?其实node提供的stream模块可以很好地解决我们的问题。
Stream
我们先来看一下stream的官方介绍:
A stream is an abstract interface for working with
streaming datain Node.js. There are many stream objects provided by Node.js. For instance, a request to an HTTP server andprocess.stdoutare both stream instances.Streams can be readable, writable, or both. All streams are instances ofEventEmitter
简单来说,stream就是给我们流式处理数据用的,那么什么是流式处理呢?用最简单的话来说就是:不是一下子处理完数据而是一点一点地处理它们。使用stream, 我们要处理的数据就会一点一点地加载到内存的某一个固定大小的区域(buffer)以给其它消费者消费。由于保存数据的buffer大小一般是固定的,当旧的数据处理完才会加载新的数据,因此它可以避免内存的崩溃。话不多说,我们马上使用stream来重构一下上面的sendFile函数:
const sendFile = async (resp, pathname) => {
// 为需要读取的文件创建一个可读流readableStream
const fileStream = fs.createReadStream(pathname)
fileStream.pipe(resp)
}
上面的代码中,我们为需要读取的文件创建了一个可读流(ReadableStream),然后将这个流和resp对象连接(pipe)在一起,这样文件的数据就会源源不断发送给客户端了。看到这里你可能会问,为什么resp对象可以和fileStream连接在一起呢?原因就是这个resp对象底层是一个可写流(WritableStream),而可读流的pipe函数接收的就是可写流。优化完后我们再来请求一下test.txt大文件,同样浏览器一顿疯狂输出,不过这个时候Node服务的内存用量是这样的:
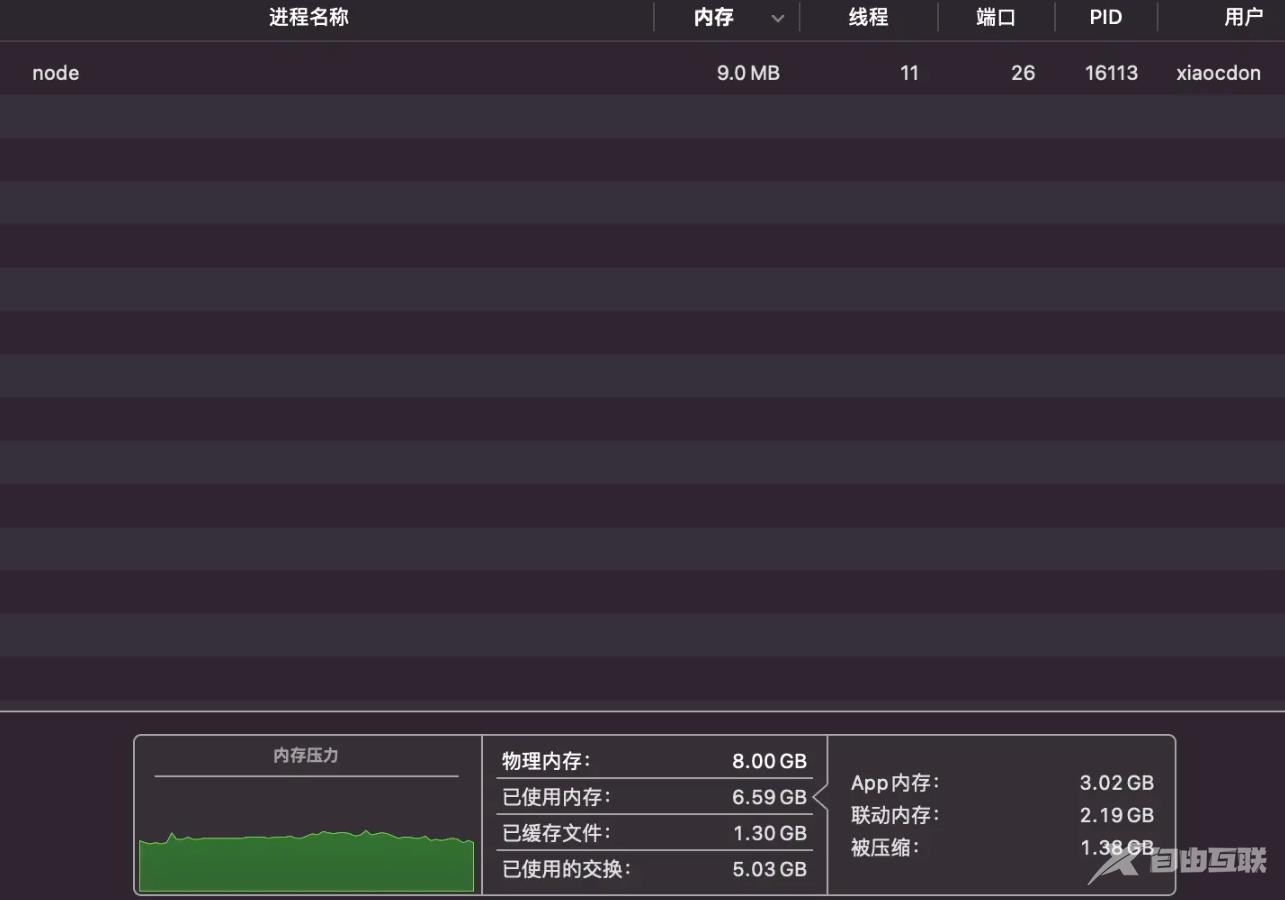
Node的内存基本稳定在9.0M,比服务刚启动时只多了0.5M!从这个可以看出我们通过stream来优化确实达到了很好的效果。由于文章篇幅的限制,这里没有详细介绍stream的API如何使用,需要了解的同学可以自行查看官方文档。
减少文件传输带宽
使用stream的确可以减少服务端的内存占用问题,可是它没有减少服务端和客户端传输的数据大小。换句话来说,假如我们的文件大小是2M我们就实打实传输这2M的数据给客户端。如果客户端是手机或者其它移动设备的话,这么大的带宽消耗肯定是不可取的。这个时候我们需要对被传输的数据进行压缩然后再在客户端进行解压,这样传输的数据量才能大幅度减少。服务端数据压缩的算法有很多,这里我使用了一个比较常用的gzip算法,我们来看一下如何更改sendFile以支持数据压缩:
// 引入zlib包
const zlib = require('zlib')
const sendFile = async (resp, pathname) => {
// 通过header告诉客户端:服务端使用的是gzip压缩算法
resp.setHeader('Content-Encoding', 'gzip')
// 创建一个可读流
const fileStream = fs.createReadStream(pathname)
// 文件流首先通过zip处理再发送给resp对象
fileStream.pipe(zlib.createGzip()).pipe(resp)
}
在上面的代码中,我使用Node原生的zlib模块创建了一个转换流(Transform Stream),这种流是既可读又可写的(Readable and Writable Stream),所以它像是一个转换器将输入的数据进行加工然后输出到下游的可写流。我们请求index.html文件来看一下优化后的效果:

上图中,第一行的请求是没有经过gzip压缩的请求大小,大概是2.6kB,而经过gzip压缩后传输数据一下子变成373B,优化效果十分显著!
使用浏览器缓存
数据压缩虽然解决了服务端客户端传输数据的带宽问题,可是没有解决重复数据传输的问题。我们知道一般来说服务器的静态文件是很少会改变的,在服务端资源没有发生改变的前提下,同一个客户端多次访问同一个资源,服务端会传输一样的数据,而这种情况下更有效的方式是:服务器告诉客户端资源没有变化,你直接使用缓存就可以了。浏览器缓存的方式有很多种,有协商缓存和强缓存。关于这两种缓存的区别我想网络上已经有很多文章说得很清晰了,我在这里也不再多说,本篇文章主要想说一下强缓存的Etag机制如何实现。
什么是Etag
其实Etag(Entity-Tag)可以理解为文件内容的指纹,如果文件内容发生了改变那么这个指纹是大概率是会变的。这里注意的是我用了大概率而不是绝对,这是因为HTTP1.1协议里面并没有规定etag具体生成算法是什么,这完全是由开发者自己决定的。通常对于文件来说,etag是由文件的长度 + 更改时间生成的,这种做法其实是会存在浏览器读取不到最新文件内容的情况的,不过这不是本文的重点,有兴趣的同学可以参考网上的其它资料。
接着让我们图解一下基于etag的协商缓存过程:
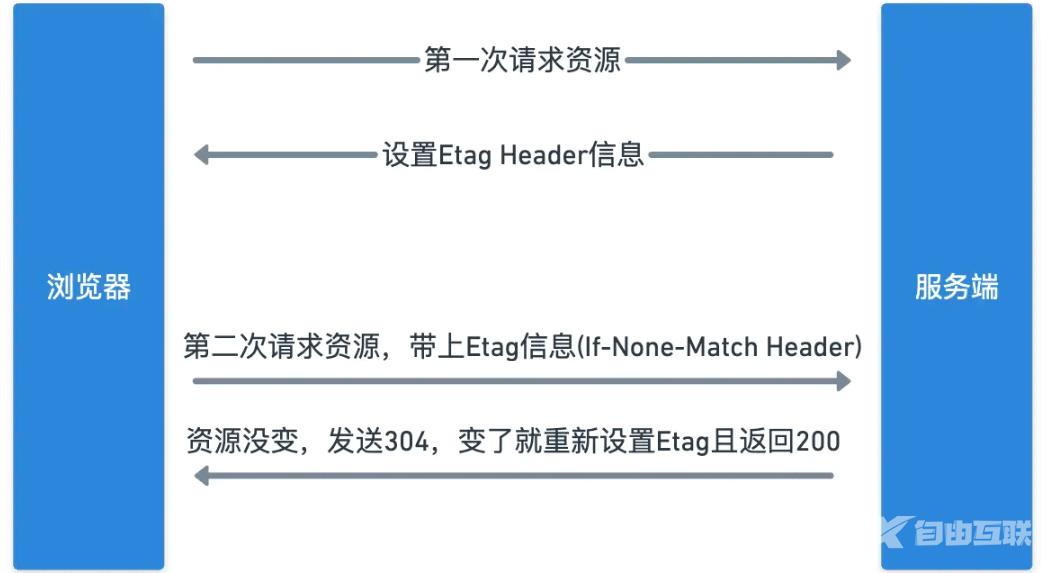
具体的过程如下:
- 浏览器第一次请求服务端的资源时,服务端会在Response里面设置当前资源的
etag信息,例如Etag: 5d-1834e3b6ea2 - 浏览器第二次请求服务端资源时,会在请求头部的
If-None-Match字段带上最新的etag信息5d-1834e3b6ea2。服务端收到请求解析出If-None-Match字段并将其和最新的服务端etag进行对比,如果是一样的就会返回304给浏览器表示资源无更新,如果资源发生了更改则将最新的etag设置到头部并且将最新的资源返回给浏览器。
接着我们来看一下sendFile函数如何支持etag:
// 这个函数会根据文件的fs.Stats信息计算出etag
const calculateEtag = (stat) => {
// 文件的大小
const fileLength = stat.size
// 文件的最后更改时间
const fileLastModifiedTime = stat.mtime.getTime()
// 数字都用16进制表示
return `${fileLength.toString(16)}-${fileLastModifiedTime.toString(16)}`
}
const sendFile = async (req, resp, stat, pathname) => {
// 文件的最新etag
const latestEtag = calculateEtag(stat)
// 客户端的etag
const clientEtag = req.headers['if-none-match']
// 客户端可以使用缓存
if (latestEtag == clientEtag) {
resp.statusCode = 304
resp.end()
return
}
resp.statusCode = 200
resp.setHeader('etag', latestEtag)
resp.setHeader('Content-Encoding', 'gzip')
const fileStream = fs.createReadStream(pathname)
fileStream.pipe(zlib.createGzip()).pipe(resp)
}
在上面的代码中我新增了一个计算etag的函数calculateEtag,这个函数会根据文件的大小和最后更改时间算出文件最新的etag信息。接着我还修改了sendFile的函数签名,接收了req(HTTP请求体)和stat(文件的信息,fs.Stats类)两个新参数。sendFile会先判断客户端的etag和服务端的etag是不是一样的,如果相同就返回304给客户端否则返回文件的最新内容并且在header设置最新的etag信息。同样我们再次访问index.html文件来验证优化效果:

上图可以看到第一次请求资源时浏览器没有缓存,服务端返回了文件的最新内容和200状态码,这个请求的实际带宽是396B,第二次请求时,由于浏览器有缓存并且服务端资源没有更新,所以服务端返回304状态码而没有返回实际的文件内容,这个时候的文件实际带宽是113B!可以看出优化效果是很明显的,我们稍微更改一下index.html的内容来验证一下客户端会不会拉到最新的数据:

从上图可以看出当index.html更新后,旧的etag失效,浏览器可以获取最新的数据。我们最后再来看一下这三个请求的详细信息,下面是第一次请求时,服务端给浏览器返回etag信息:
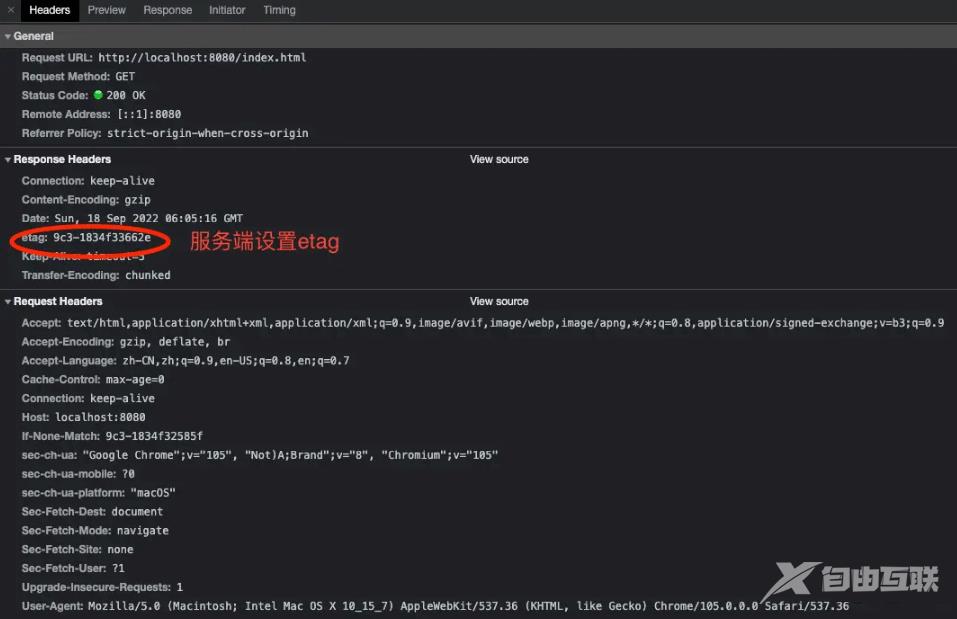
接着是第二次请求时,客户端请求服务端资源时带上etag信息:
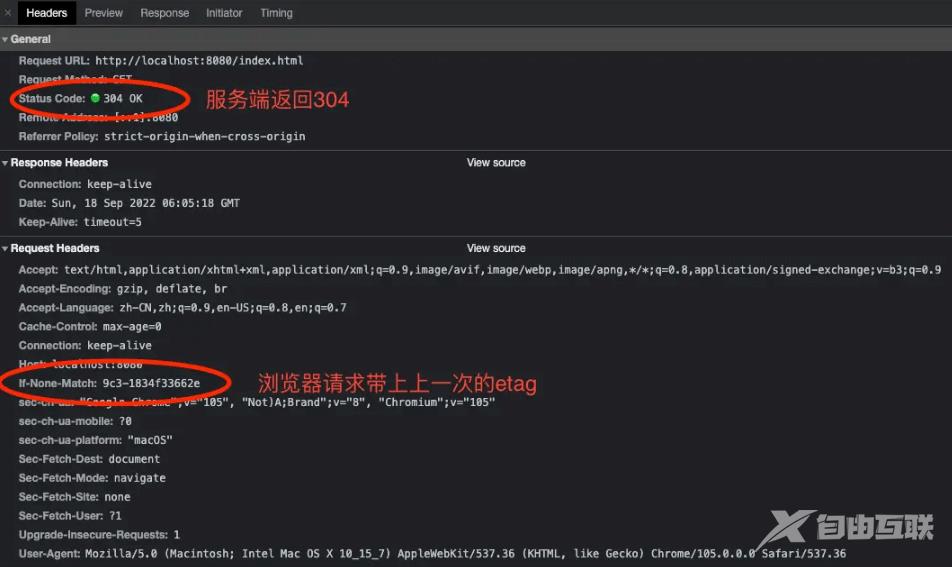
第三次请求,etag失效,拿到新的数据:
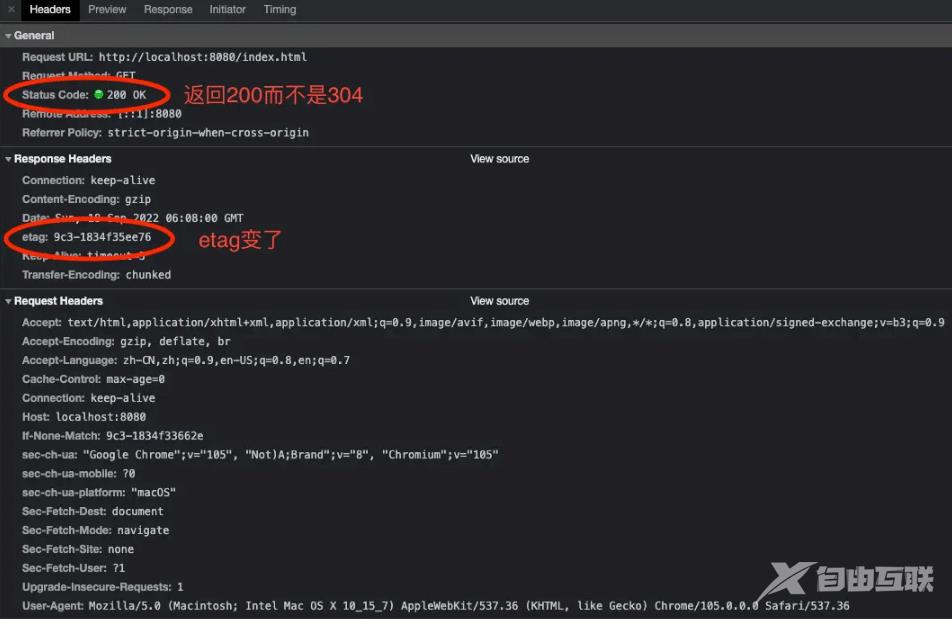
值得一提的是,这里我们只通过etag实现了浏览器的缓存,这是不完备的,实际的静态服务器可能会加上基于Expires/Cache-Control的强缓存和基于Last-Modified/Last-Modified-Since的协商缓存来优化。
总结
本篇文章我先实现了一个最简单能用的静态文件服务器,然后通过解决三个实际使用时会遇到的问题优化了我们的代码,最后完成了一个简单高效的静态文件服务器。
如上文所说,由于篇幅的限制,我们的实现上还是漏了很多东西的,例如MIME类型的设置,支持更多的压缩算法如deflate以及支持更多的缓存方式如Last-Modified/Last-Modified-Since等。这些内容其实在掌握了上面的方法后很容易就可以实现了,所以就留给大家在需要真正用到的时候自己实现了。
到此这篇关于如何使用Node写静态文件服务器的文章就介绍到这了,更多相关Node静态文件服务器内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!