目录
- 前言
- 编译准备
- 源码编译链式调用
- compileToFunctions
- parse
- 解析 template
- 标签匹配相关的正则
- stack
- advance
- while
- 解析开始标签
- 解析结束标签
- 当前 template < 不在第一个字符串
- 处理 stack 栈中剩余未处理的标签
- 生成 AST
- start 钩子函数
- end 钩子函数
- 为什么回退?
- 解析 <p>
- 解析 </p>
- chars 钩子函数
- commit 钩子函数
- 番外(可跳过)
- createASTElement 函数
- 指令解析相关的正则
- parseText 函数
- closeElement 函数
- 整体流程
- 总结
前言
Vue.js 提供了 2 个版本,一个是 Runtime + Compiler 版本,一个是 Runtime only 版本。Runtime + Compiler 版本是包含编译代码的,可以把编译过程放在运行时做,Runtime only 版本不包含编译代码的,需要借助 webpack 的 vue-loader 事先把模板编译成 render 函数。
如果你需要在客户端编译模板 (比如传入一个字符串给 template 选项,或挂载到一个元素上并以其 DOM 内部的 HTML 作为模板),就将需要加上编译器,即完整版:
// 需要编译器
new Vue({
template: '<div>{{ hi }}</div>'
})
// 不需要编译器
new Vue({
render (h) {
return h('div', this.hi)
}
})
当使用 vue-loader 或 vueify 的时候,*.vue 文件内部的模板会在构建时预编译成 JavaScript。你在最终打好的包里实际上是不需要编译器的,所以只用运行时版本即可。因为运行时版本相比完整版体积要小大约 30%,所以应该尽可能使用这个版本。
在 Vue 的整个编译过程中,会做三件事:
- 解析模板
parse,生成 AST - 优化 AST
optimize - 生成代码
generate
对编译过程的了解会让我们对 Vue 的指令、内置组件等有更好的理解。不过由于编译的过程是一个相对复杂的过程,我们只要求理解整体的流程、输入和输出即可,对于细节我们不必抠太细。由于篇幅较长,这里会用三篇文章来讲这三件事。这是第一篇, 模板解析,template -> AST
注:全文源码来源,Vue(2.6.11),Runtime + Compiler 的 Vue.js
编译准备
这里先做一个准备工作,编译之前有一个嵌套的函数调用,看似非常的复杂,但是却有玄机。有什么玄机?接着往下看。
源码编译链式调用
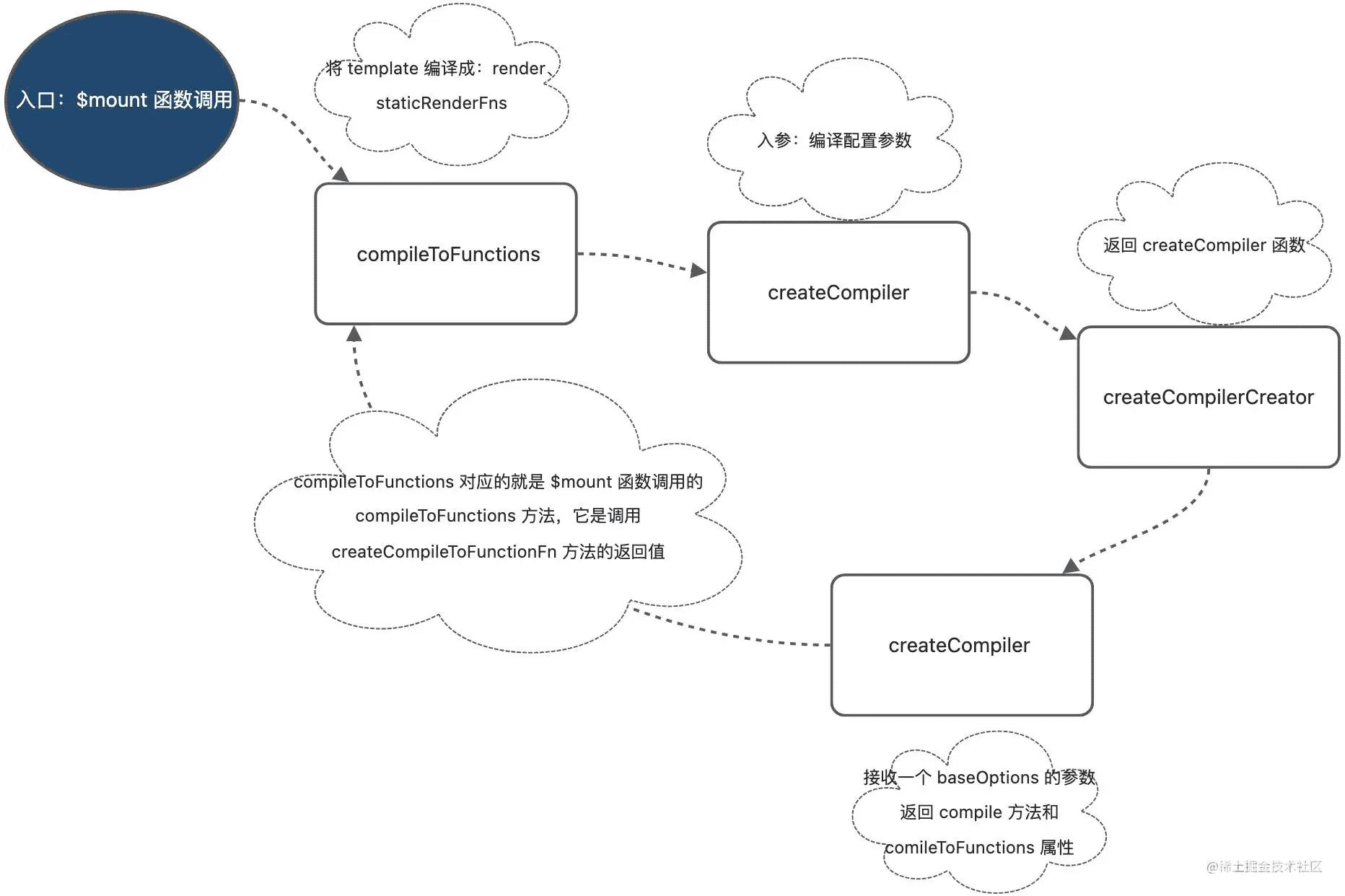
compileToFunctions
在源码走了一遭,发现经过一系列的调用,最后 createCompiler 函数返回的 compileToFunctions函数 对应的就是 $mount 函数调用的 compileToFunctions 方法,它是调用 createCompileToFunctionFn 方法的返回值。
// 伪代码
function createCompilerCreator (baseCompile) {
return function createCompiler (baseOptions) {
function compile (
template,
options
) {
...
return compiled
}
return {
compile: compile,
compileToFunctions: createCompileToFunctionFn(compile)
}
}
}
function createCompileToFunctionFn (compile) {
var cache = Object.create(null);
return function compileToFunctions (
template,
options,
vm
) {
...
}
}
方法接受三个参数。
- 编译模板 template
- 编译配置 options
- Vue 的实例
这个方法编译的核心代码就一行。
// compile var compiled = compile(template, options);
而 compile 方法的核心代码也就一行。
const compiled = baseCompile(template, finalOptions)
并且 baseCompile方法是在执行 createCompilerCreator 方法执行的时候传入的。
var createCompiler = createCompilerCreator(function baseCompile (
template,
options
) {
var ast = parse(template.trim(), options);
if (options.optimize !== false) {
optimize(ast, options);
}
var code = generate(ast, options);
return {
ast: ast,
render: code.render,
staticRenderFns: code.staticRenderFns
}
});
baseCompile会做三件事情。

其实看到这里你就会发现,这编译的准备工作,做了很多函数的调用,但是兜兜转转之后,最后回头来还是调用了最开始createCompilerCreator传入的函数。
我理解这样做的原因是 Vue 本身是支持多平台的编译,在不同平台下的编译会有所有不同,但是在同一平台编译是相同的,所以在使用createCompiler(baseOptions)时,baseOptions 会有所有不同。
在 Vue 中利用函数柯里化的思想,将 baseOptions 的配置参数进行了保存。并且在调用链中,不断的进行函数调用并返回函数。
这其实也是利用了函数柯里化的思想把很多基础的函数抽离出来, 通过 createCompilerCreator(baseCompile) 的方式把真正编译的过程和其它逻辑如对编译配置处理、缓存处理等剥离开,这样的设计还是非常巧妙的。
编译准备已经做完,我们接下来看看 Vue 是如何做 parse 的。
parse
parse 要做的事情就是对 template 做解析,生成 AST 抽象语法树。
抽象语法树(Abstract Syntax Tree,AST),或简称语法树(Syntax tree),是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。
例如现在有这样一段代码:
<body>
<div id="app"></div>
<script>
new Vue({
el: '#app',
template: `
<ul>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
</ul>
`
});
</script>
</body>
经过parse,就变成了一个嵌套的树状结构的对象。
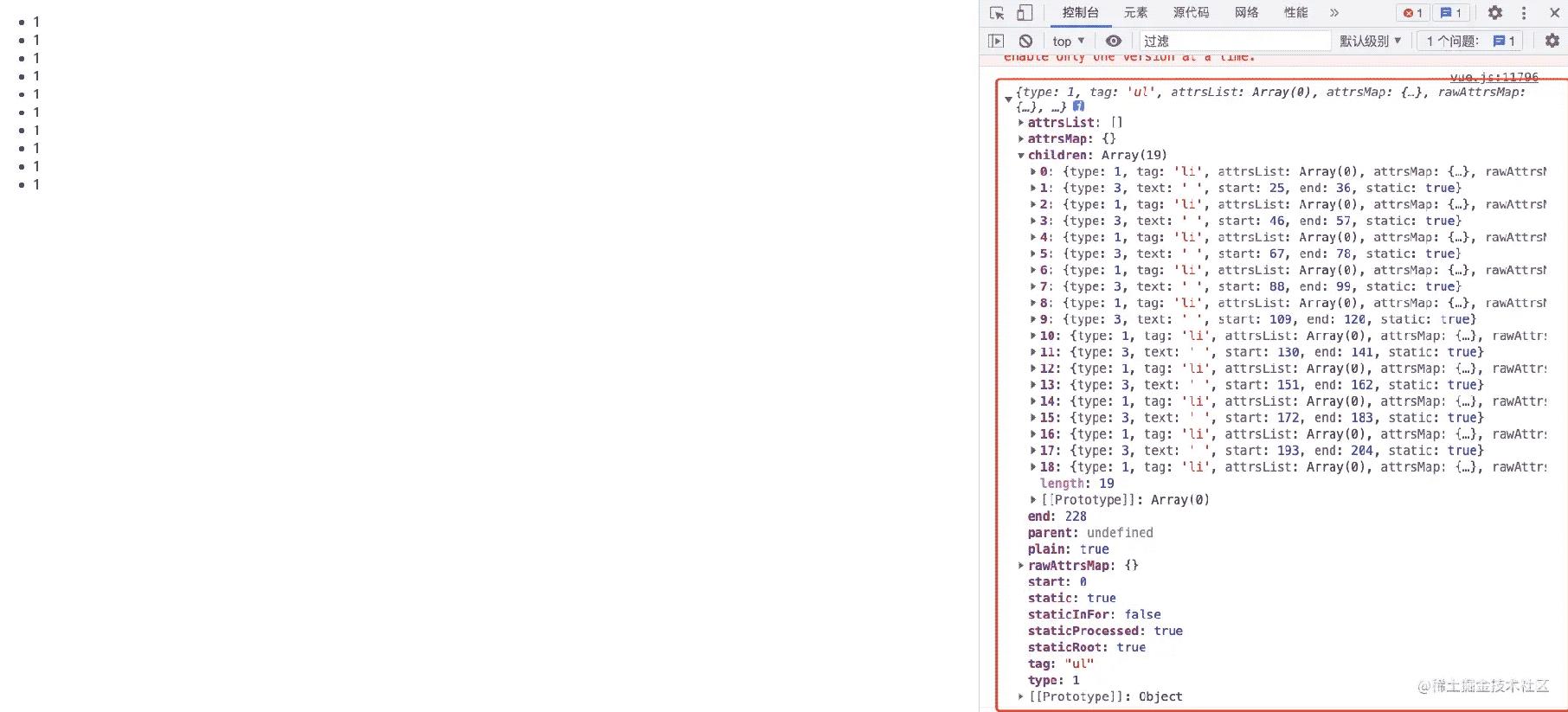
在 AST 中,每一个树节点都是一个 element,并且维护了上下文关系(父子关系)。
解析 template
parse的过程核心就是 parseHTML 函数,这个函数的作用就是解析 template 模板。下面将解析过程中一些重要的点进行一个抽象解读。
function parseHTML (html, options) {
var stack = [];
...
// 遍历模板字符串
while (html) {
...
}
// 清除所有剩余的标签
parseEndTag();
// 将 html 字符串的指针前移
function advance (n) {
...
}
// 解析开始标签
function parseStartTag () {
...
}
// 处理解析的开始标签的结果
function handleStartTag (match) {
...
}
// 解析结束标签
function parseEndTag (tagName, start, end) {
...
}
}
标签匹配相关的正则
下面也会讲到关于一些指令匹配相关的正则。其实这些正则大家在平时的项目中有涉及也可以用起来,毕竟这些正则是经过千万人测试的。
// 识别合法的xml标签
var ncname = '[a-zA-Z_][\w\-\.]*';
// 复用拼接,这在我们项目中完成可以学起来
var qnameCapture = "((?:" + ncname + "\:)?" + ncname + ")";
// 匹配注释
var comment =/^<!--/;
// 匹配<!DOCTYPE> 声明标签
var doctype = /^<!DOCTYPE [^>]+>/i;
// 匹配条件注释
var conditionalComment =/^<![/;
// 匹配开始标签
var startTagOpen = new RegExp(("^<" + qnameCapture));
// 匹配解说标签
var endTag = new RegExp(("^<\/" + qnameCapture + "[^>]*>"));
// 匹配单标签
var startTagClose = /^\s*(/?)>/;
// 匹配属性,例如 id、class
var attribute = /^\s*([^\s"'<>/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/;
// 匹配动态属性,例如 v-if、v-else
var dynamicArgAttribute = /^\s*((?:v-[\w-]+:|@|:|#)[[^=]+][^\s"'<>/=]*)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/;
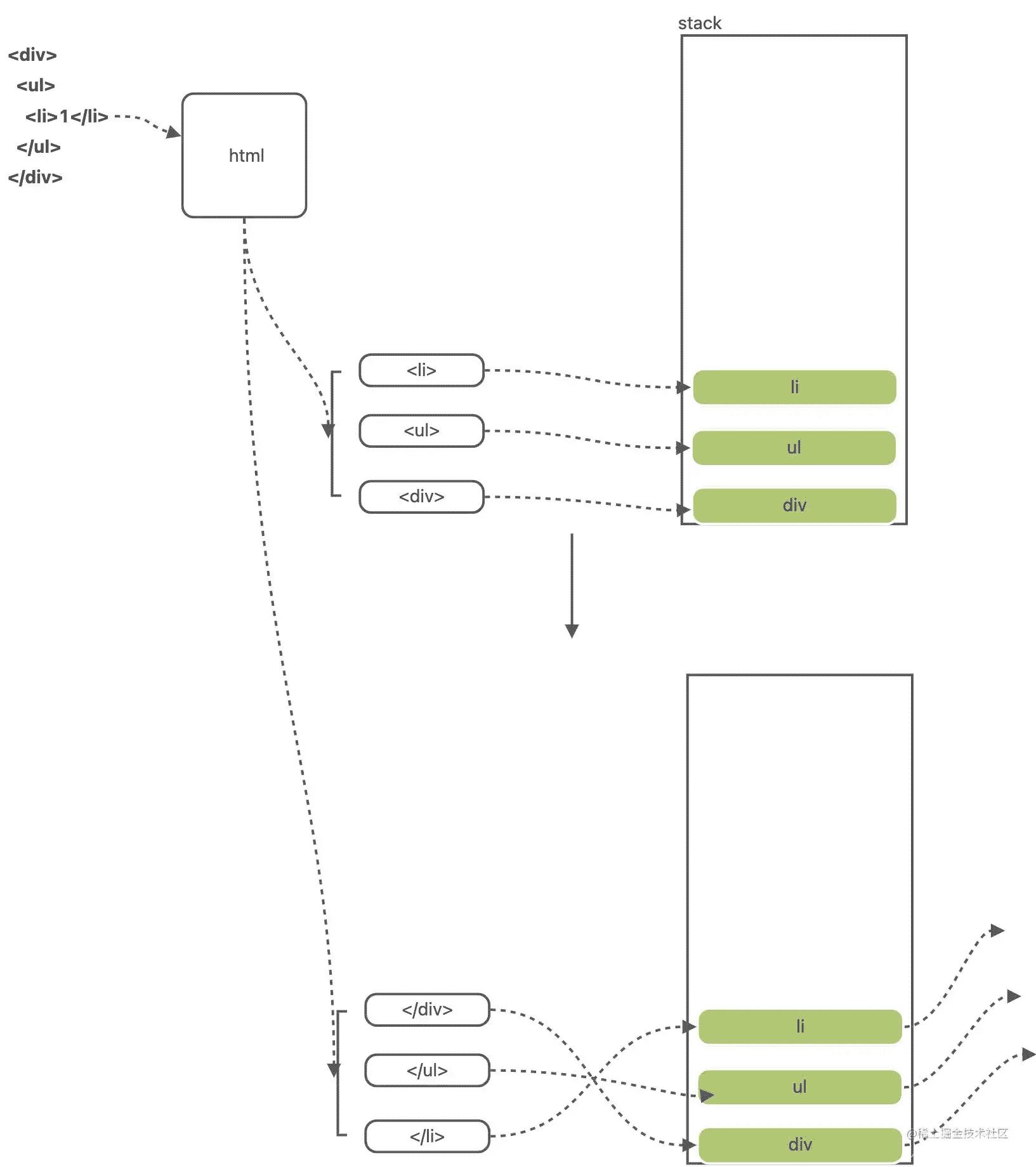
stack
变量 stack ,它定义一个栈,作用是存储开始标签。例如我有一个这样的简单模板:
<div>
<ul>
<li>1</li>
</ul>
</div>
当在 while 循环时,如果遇到一个非单标签,就会将开始标签 push 到数组中,遇到闭合标签就开始元素出栈,这样可以检测我们写的 template 是否符合嵌套、开闭规范,这也是检测 html 字符串中是否缺少闭合标签的原理。
advance
advance 函数贯穿这个 template 的解析流程。当我们在解析 template 字符串的时候,需要对字符串逐一扫描,直到结束。advance 函数的作用就是移动指针。例如匹配 <字符,指针移动 1,匹配到<!--字符指针移动 4。在整个解析过程中,贯穿着指针的移动,因为要想解析完成就必须把模板全部编译完。
function advance (n) {
index += n;
html = html.substring(n);
}
while
template 的 while 循环是解析中最重要的一环,也是这一小节的重点。
循环的终止条件是 html 字符串为空,即 html 字符串全部编译完毕。
循环时,第一个判断是判断内容是否在存纯文本标签中。判断的作用是: 确保我们没有像脚本/样式这样的纯文本内容元素。
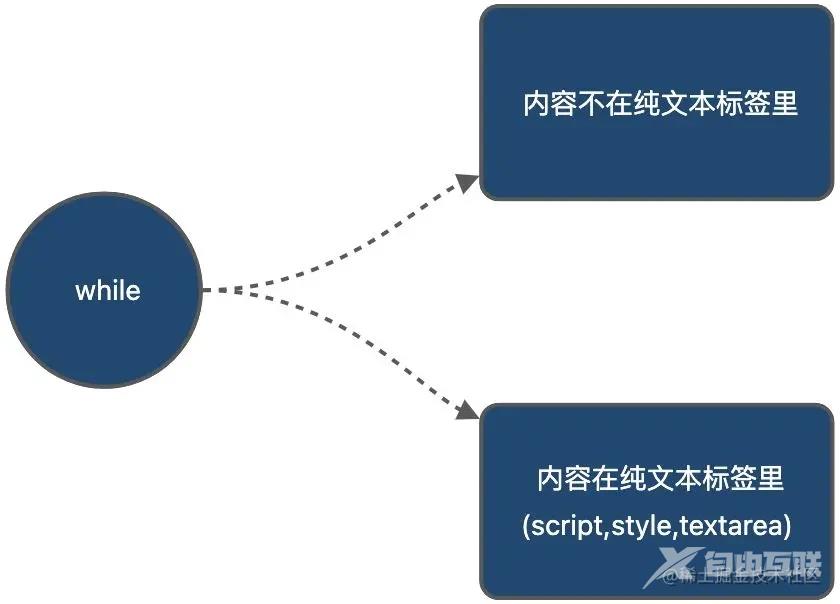
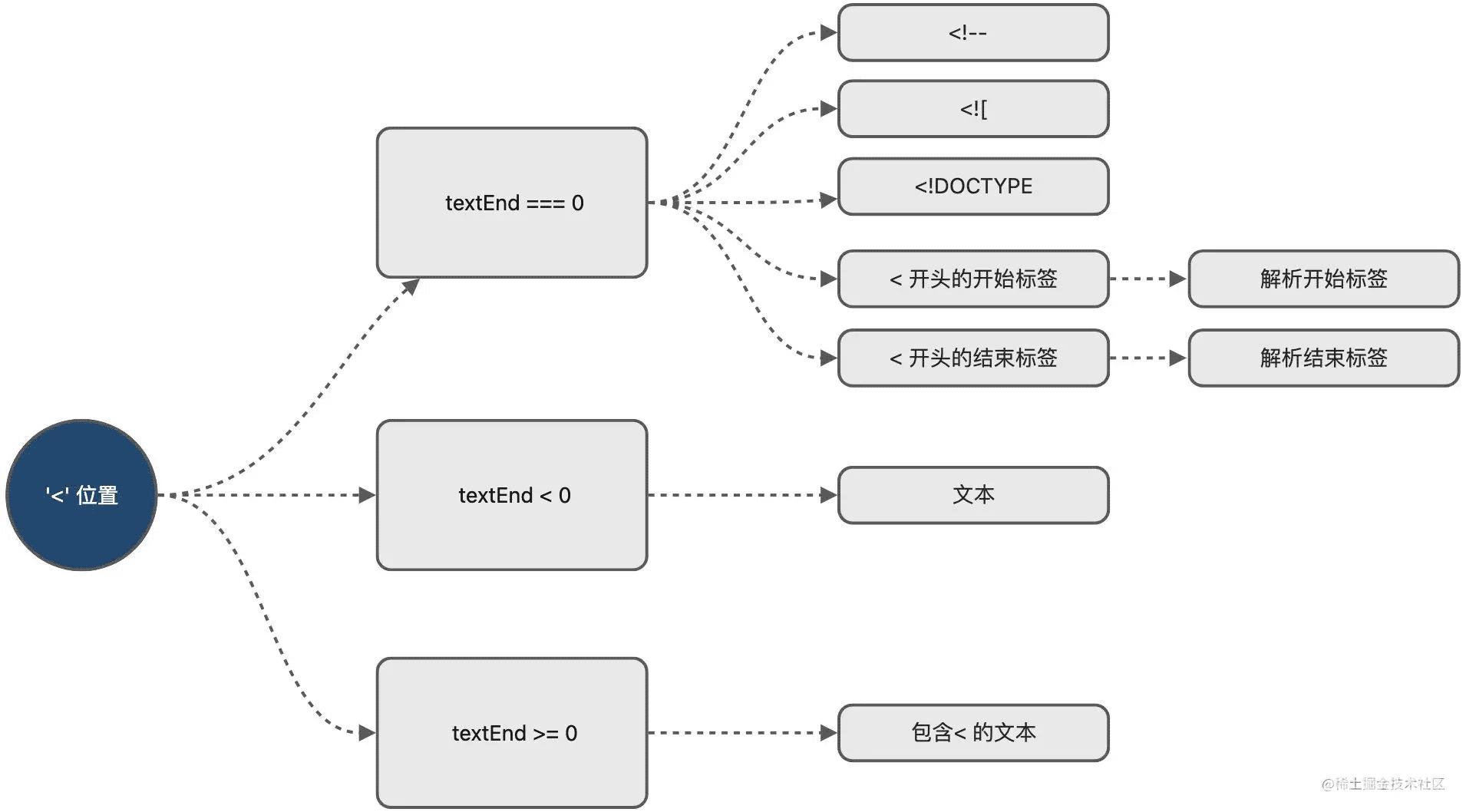
当内容不在纯文本标签,判断 template 字符串的第一个<字符位置,来进行不同的操作。
var textEnd = html.indexOf('<');
当前 template 第一个字符是 <
在这种场景下, template 会出现以下几种情况,重点是解析开始标签和结束标签。
<!--开头的注释:会找到注释的结尾,将注释截取出来,移动指针,并将注释当做当前父节点的一个子元素存储到 children 中。<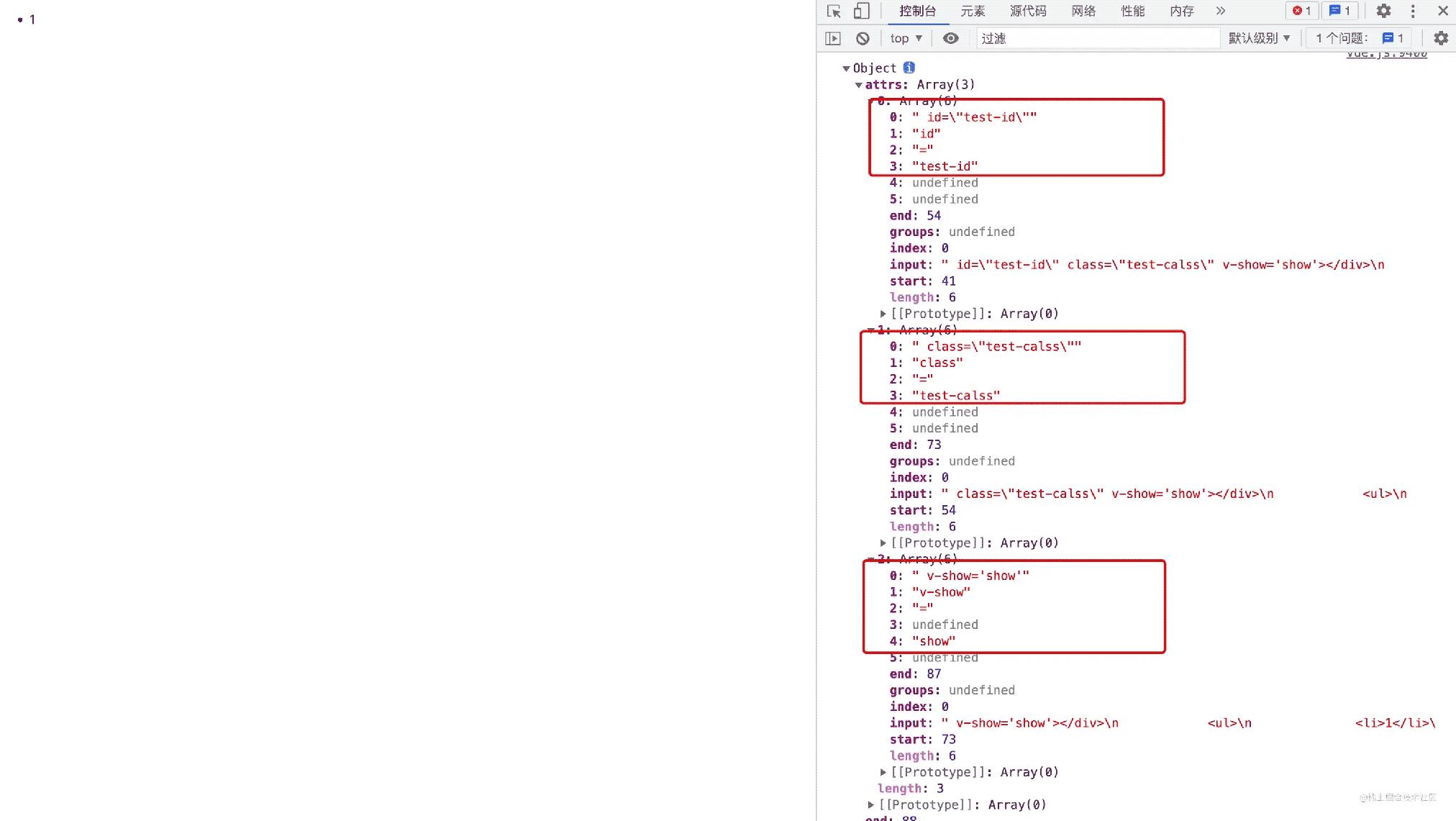
⑤,上一步获取了标签的属性和动态属性,但是即使这样并不能说明这是一个完整的标签,只有当匹配到开始标记的结束标记时,才能证明这是一个完整的标签,所以才会有这一步的判断。varstartTagClose= /^\s*(/?)>/;并且标记 unarySlash属性。

⑥,假设正常匹配了,有匹配结果,也返回了 match (结构如上),就会走到handleStartTag 这个函数的作用就是用来处理开始标签的解析结果,所以它接收 parseStartTag 函数的返回值作为参数。
handleStartTag 的核心逻辑很简单,先判断开始标签是否是一元标签,类似 <img />、<br/> 这样,接着对 match.attrs 遍历并做了一些处理,最后判断如果非一元标签,则往 stack 里 push 一个对象,并且把 tagName 赋值给 lastTag。
function parseStartTag () {
// ①
var start = html.match(startTagOpen);
if (start) {
// ②
var match = {
tagName: start[1],
attrs: [],
start: index
};
// ③
advance(start[0].length);
var end, attr;
// ④
while (!(end = html.match(startTagClose)) && (attr = html.match(dynamicArgAttribute) || html.match(attribute))) {
...
}
// ⑤
if (end) {
match.unarySlash = end[1];
advance(end[0].length);
match.end = index;
return match
}
}
}
// Start tag:
var startTagMatch = parseStartTag();
if (startTagMatch) {
handleStartTag(startTagMatch);
...
}
// ⑥
function handleStartTag (match) {
...
}
解析结束标签
有解析开始标签就会解析结束标签。所以接下来我们来看看如何解析结束标签。
①,正则匹配结束标签(具体的正则看前面)。
②,匹配到结束标签,进行解析处理,获取到结束标签的标签名称、开始位置和结束位置,开始进行解析操作。
③,查找同一类型的最近打开的标记,并记录位置。
④,如果存在同一类型的标记,就将 stack 中匹配的标记弹出。
⑤,如果没有同一类型的标记,分别处理 </br>、</p> 标签。这是为了和浏览器保持同样的行为。举个例子:在代码中,分别写了</br>、</p>的结束标签,但注意我们并没有写起始标签,但是浏览器是能够正常解析他们的,其中 </br> 标签被正常解析为 <br> 标签,而</p>标签被正常解析为 <p></p> 。除了 br 与 p 其他任何标签如果你只写了结束标签那么浏览器都将会忽略。所以为了与浏览器的行为相同,parseEndTag 函数也需要专门处理 br 与 p 的结束标签,即:</br> 和</p>。
<div> </br> </p> </div>

// ①
var endTagMatch = html.match(endTag);
if (endTagMatch) {
var curIndex = index;
advance(endTagMatch[0].length);
// ②
// 获取到结束标签的标签名称、开始位置和结束位置
parseEndTag(endTagMatch[1], curIndex, index);
continue
}
function parseEndTag (tagName, start, end) {
...
// ③
if (tagName) {
lowerCasedTagName = tagName.toLowerCase();
for (pos = stack.length - 1; pos >= 0; pos--) {
if (stack[pos].lowerCasedTag === lowerCasedTagName) {
break
}
}
} else {
pos = 0;
}
// ④
if (pos >= 0) {
...
stack.length = pos;
lastTag = pos && stack[pos - 1].tag;
// ⑤
} else if (lowerCasedTagName === 'br') {
if (options.start) {
options.start(tagName, [], true, start, end);
}
} else if (lowerCasedTagName === 'p') {
if (options.start) {
options.start(tagName, [], false, start, end);
}
if (options.end) {
options.end(tagName, start, end);
}
}
}
到这里结束标签页解析完成,但是在 Vue 中对开始标签和结束标签的解析远不止这样,因为为了浏览器行为保持一下在解析的过程中还会对一些特殊标签特殊处理,典型的就是 p、br标签,我会在后面出一篇文章来详细讲讲 Vue 是如何处理它们的。
当前 template 不存在 <
当解析到的 template 中不存在 < 时,这认为是一个文本。操作很简单就是移动指针。
并且这里在源码中发现初始化变量的时候,都是这样写的 var text =(void0), rest =(void0), next =(void0);而不是直接 var xx = undefined。原因是这样操作更加的安全,我在之前的一篇文章中专门解析过,有兴趣的可以再去看看。
JavaScript void 运算符
if (textEnd < 0) {
text = html;
}
if (text) {
advance(text.length);
}
当前 template < 不在第一个字符串
这里的判断处理就是为了处理我们在一些纯文本中也会写 <标记的场景。例如:
<div>1<2</div>
现在有这样一段模块,<div>被解析之后,还剩 1<2,这时解析到存在 <标记但是位置不在第一个。就循环找出包含<的这一段文本,并将这一段当成一个纯文本处理。
if (textEnd >= 0) {
rest = html.slice(textEnd);
while (
!endTag.test(rest) &&
!startTagOpen.test(rest) &&
!comment.test(rest) &&
!conditionalComment.test(rest)
) {
next = rest.indexOf('<', 1);
if (next < 0) { break }
textEnd += next;
rest = html.slice(textEnd);
}
text = html.substring(0, textEnd);
}
处理 stack 栈中剩余未处理的标签
当 while 循环解析了一遍 template 之后,会再调用一次 parseEndTag,这样做的目的是为了处理 stack 栈中剩余未处理的标签。当调用时,没有传递任何参数,也意味着 tagName, start, end 都是空的,这时 pos 为 0 ,所以 i >= pos 始终成立,这个时候 stack 栈中如果有剩余未处理的标签,则会逐个警告缺少闭合标签,并调用 options.end 将其闭合。
// Clean up any remaining tags
parseEndTag();
function parseEndTag (tagName, start, end) {
if (tagName) {
...
} else {
pos = 0;
}
if (pos >= 0) {
for (var i = stack.length - 1; i >= pos; i--) {
if (i > pos || !tagName && options.warn) {
options.warn(
("tag <" + (stack[i].tag) + "> has no matching end tag."),
{ start: stack[i].start, end: stack[i].end }
);
}
}
...
}
}
到这里解析 template 的重点过程都基本结束了,整个过程就是遍历 template 字符串,然后通过正则一点一点的匹配解析字符串,直到整个字符串被解析完成。
生成 AST
当然解析完 template 目的是生成 AST,经过上面的一些列操作,只是解析完 template 字符串,并没有生成一颗 AST 抽象语法树。正常的来说抽象语法树应该是如下这样的,节点与节点之间通过 parent 和 children 建立联系,每个节点的 type 属性用来标识该节点的类别,比如 type 为 1 代表该节点为元素节点,type 为 3 代表该节点为文本节点。
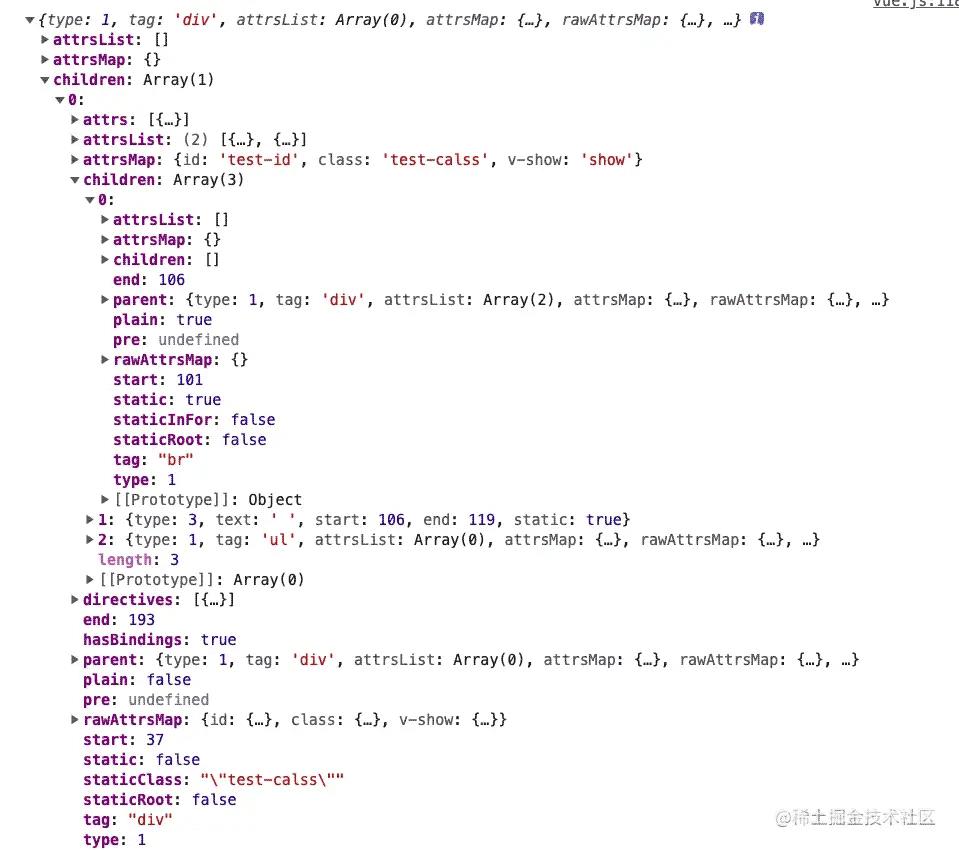
生成 AST 的主要步骤是在解析的过程中,会调用对应的钩子函数。解析到开始标签,就调用开始的钩子函数,解析到结束标签就调用结束的钩子函数,解析到文本就会调用文本的钩子,解析到注释就调用注释的钩子函数。这些钩子函数就会将所有的节点串联起来,并生成 AST 树的结构。
start 钩子函数
这个钩子函数会在解析到开始标签的时候被调用。为了更加清楚解析过程,我们引入如下一个模板,如下:
<div><span></span><p></p></div>
解析 <div>
①,解析到<div>会调用 start 钩子函数。
②,创建一个基础元素对象。
{
type: 1,
tag:"div",
parent: null,
children: [],
attrsList: []
}
function createASTElement (
tag,
attrs,
parent
) {
return {
type: 1,
tag: tag,
attrsList: attrs,
attrsMap: makeAttrsMap(attrs),
rawAttrsMap: {},
parent: parent,
children: []
}
}
③,接着判断 root 是否存在,如果不存在则直接将 element 赋值给 root 。root 是一个记录值,也就是最后解析返回的整个 AST。
④,如果当前标签不是一元标签时,会将当前的 element赋值给 currentParent目的是为建立父子元素的关系。
⑤,将元素入栈,入栈的目的是为了做回退操作,这里先不讲为什么需要做回退,后面在讲。此时 stack = [{ tag : "div"... }]。
// parseHTML函数 解析到开始标签
function handleStartTag (match) {
if (options.start) {
// ①
options.start(tagName, attrs, unary, match.start, match.end);
}
}
// start 钩子函数
start: {
// ②
var element = createASTElement(tag, attrs, currentParent);
// element:
// {
// type: 1,
// tag:"div",
// parent: null,
// children: [],
// attrsList: []
// }
// ③
if (!root) {
root = element;
}
// ④
if (!unary) {
currentParent = element;
// currentParent:
// {
// type: 1,
// tag:"div",
// parent: null,
// children: [],
// attrsList: []
// }
// ⑤
stack.push(element);
}
}
解析 <span>
接着解析到 <span>。此时 root 已经存在,currentParent 也存在,所以会将 span 元素的描述对象添加到 currentParent 的 children 数组中作为子节点,并将自己的 parent 元素进行标记。所以最终生成的描述对象为:
{
type: 1,
tag:"div",
parent: {/*div 元素的描述*/},
attrsList: []
children: [{
type: 1,
tag:"span",
parent: div,
attrsList: [],
children:[]
}],
}
此时 stack = [{ tag : "div"... }, {tag : "span"...}]。
end 钩子函数
当解析到结束标签就会调用结束标签的钩子函数,还是这段模板代码,解析完<div><span>后遇到了</span>。
<div><span></span><p></p></div>
解析
①,首先就是保存最后一个元素,将 stack 的最后一个元素删除,也就是变成 stack = [{tag: "div" ...}],这就是做了一个回退操作 。
②,设置 currentParent 为 stack 的最后一个元素。
end: function end (tag, start, end$1) {
// ①
var element = stack[stack.length - 1];
stack.length -= 1;
// ②
currentParet = stack[stack.length - 1];
...
},
为什么回退?
解析 <p>
当再次解析到开始标签时,就会再次调用 start 钩子函数,这里重点是在解析 p 的开始标签时:stack = [{tag:"div"...},{tag:"p"...}] ,由于在解析到上一个 </span>标签时做了一个回退操作, 这就能保证在解析 p 开始标签的时候,stack 中存储的是 p 标签父级元素的描述对象。
解析 </p>
解析结束标签,做回退操作。
遇到开始标签就生成元素,勾勒上下文关系 parent、children 等,每当遇到一个非一元标签的结束标签时,都会回退 currentParent 变量的值为之前的值,这样就修正了当前正在解析的元素的父级元素。
chars 钩子函数
当然在我们的代码中肯定不止是开始和结束标签,还会有文本。当遇到文本时,就会调用 chars 钩子函数。
①,首先判断 currentParent(指向的是当前节点的父节点) 变量是否存在,不存在就说明,说明 1:只有文本节点。2:文本在根元素之外。这两种情况都会警告 ⚠️ 提醒,接触后面的操作。
②,第二个判断主要是解决 ie textarea 占位符的问题。issue
③,判断当前元素未使用 v-pre 指令,text 不为空,使用 parseText 函数成功解析当前文本节点的内容。这里的重点在于 parseText 函数,parseText 函数的作用就是用来解析如果我们的文本包含了字面量表达式。例如:
<div>1111: {{ text }}</div>
这样的文本就会解析成如下的一个描述对象, 包含 expression 、tokens (包含原始的文本)。

解析完之后会生成一个 type = 2 的描述对象:
child = {
type: 2,
expression: res.expression,
tokens: res.tokens,
text: text
};
④,如果使用了 v-pre || test 为空 || parseText 解析失败,那么就会生成一个 type = 3 的存文本描述对象。
child = {
type: 1,
text: text
};
⑤,最后将解析到描述对象,添加到当前父元素的 children 列表中,注意:这里之前说明过因为我们的整个 template 是不能是纯文本的,必须由根元素,所以如果是文本节点,一点是会有父元素的。
chars: function chars (text, start, end) {
// ①
if (!currentParent) {
{
if (text === template) {
...警告
} else if ((text = text.trim())) {
...警告
}
}
return
}
// ②
if (isIE &&
currentParent.tag === 'textarea' &&
currentParent.attrsMap.placeholder === text
) {
return
}
var children = currentParent.children;
...
if (text) {
...
// ③
if (!inVPre && text !== ' ' && (res = parseText(text, delimiters))) {
child = {
type: 2,
expression: res.expression,
tokens: res.tokens,
text: text
};
// ④
} else if (text !== ' ' || !children.length || children[children.length - 1].text !== ' ') {
child = {
type: 3,
text: text
};
}
// ⑤
if (child) {
...
children.push(child);
}
}
},
到这里文本节点的解析完成。接下来看看注释解析的钩子函数。
commit 钩子函数
当我们配置了 options.comments = true ,也就意味着我们需要保留我们的注释,这个配置需要我们手动开启,开启后就会在页面渲染后保留注释。
注意:如果开启了保留注释匹配后,浏览器会保留注释。但是可能对布局产生影响,尤其是对行内元素的影响。为了消除这些影响带来的问题,好的做法是将它们去掉。
注释的解析比较简单,就是创建注释节点,然后添加当前父元素的子阶段列表中。要注意的是纯文本节点和注释节点的描述对象的 type 都是 3,不同的是注释节点的元素描述对象拥有 isComment 属性,并且该属性的值为 true,目的就是用来与普通文本节点作区分的。
shouldKeepComment: options.comments,
if (textEnd === 0) {
...
if (options.shouldKeepComment) {
options.comment(html.substring(4, commentEnd), index, index + commentEnd + 3);
}
...
}
comment: function comment (text, start, end) {
if (currentParent) {
var child = {
type: 3,
text: text,
isComment: true
};
...
currentParent.children.push(child);
}
}
到这里在生成 AST 过程中的 四个钩子函数已经全部讲完。但是 Vue 本身在对元素做处理的时候的时候肯定不会是这么简单的,因为这处理的过程中还要处理一元标签、静态属性、动态属性等。
番外(可跳过)
这一小节注意是看看在生成 AST 过程中的一些重要的工具函数。
createASTElement 函数
创建元素的描述对象。
function createASTElement (
tag,
attrs,
parent
) {
return {
type: 1,
tag: tag,
attrsList: attrs,
attrsMap: makeAttrsMap(attrs),
rawAttrsMap: {},
parent: parent,
children: []
}
}
指令解析相关的正则
前面也讲到关于一些标签匹配相关的正则。其实这些正则大家在平时的项目中有涉及也可以用起来,毕竟这些正则是经过千万人测试的。
var onRE = /^@|^v-on:/; var dirRE = /^v-|^@|^:|^#/; var forAliasRE = /([\s\S]*?)\s+(?:in|of)\s+([\s\S]*)/; var forIteratorRE = /,([^,}]]*)(?:,([^,}]]*))?$/; var stripParensRE = /^(|)$/g; var dynamicArgRE = /^[.*]$/; var argRE = /:(.*)$/; var bindRE = /^:|^.|^v-bind:/; var modifierRE = /.[^.]]+(?=[^]]*$)/g;
onRE
匹配已字符 @ 或者 v-on开头的字符串,检测标签属性是否是监听事件的指令。
var onRE = /^@|^v-on:/;
dirRE
匹配 v-、@、:、#开头的字符串,检测属性名是否是指令。v-开头的属性统统都认为是指令。@字符是 v-on 的缩写。: 是 v-bind 的缩写。 #是 v-slot 的缩写。
var dirRE = /^v-|^@|^:|^#/;
forAliasRE
匹配 v-for属性的值,目的是捕获 in 或者 of 前后的字符串。
var forAliasRE = /([\s\S]*?)\s+(?:in|of)\s+([\s\S]*)/;
forIteratorRE
这个也是用来匹配 v-for属性的,不同的是,这里是匹配遍历时的 value 、 key 、index 。
var forIteratorRE = /,([^,}]]*)(?:,([^,}]]*))?$/;
stripParensRE
匹配以字符 (开头、)结尾的字符串。作用是配合上面的正则对字符进行处理(、)。
var stripParensRE = /^(|)$/g;
argRE
匹配指令中的参数。作用是捕获指令中的参数。常见的就是指令中的修饰符。
var argRE = /:(.*)$/;
bindRE
匹配:、.、v-bind:开头的字符串。作用是检查属性是否是绑定。
var bindRE = /^:|^.|^v-bind:/;
modifierRE
匹配修饰符。主要作用是判断是否有修饰符。
var modifierRE = /.[^.]]+(?=[^]]*$)/g;
parseText 函数
这个函数的作用是解析 text,在上面讲 chars 钩子函数的时候也说到这个函数。函数有两个参数text、delimiters。delimiters参数作用就是:改变纯文本插入分隔符。例如:
delimiters: ['${', '}'],
// 模板
<div>{{ text }}</div>
模板会被编译成这样。

在 parseText 函数中,重点逻辑是开启一个 while 循环,使用 tagRE 正则匹配文本内容,并将匹配结果保存在 match 变量中,直到匹配失败循环才会终止,这时意味着所有的字面量表达式都已经处理完毕了。
while ((match = tagRE.exec(text))) {
index = match.index;
if (index > lastIndex) {
rawTokens.push(tokenValue = text.slice(lastIndex, index));
tokens.push(JSON.stringify(tokenValue));
}
var exp = parseFilters(match[1].trim());
tokens.push(("_s(" + exp + ")"));
rawTokens.push({ '@binding': exp });
lastIndex = index + match[0].length;
}
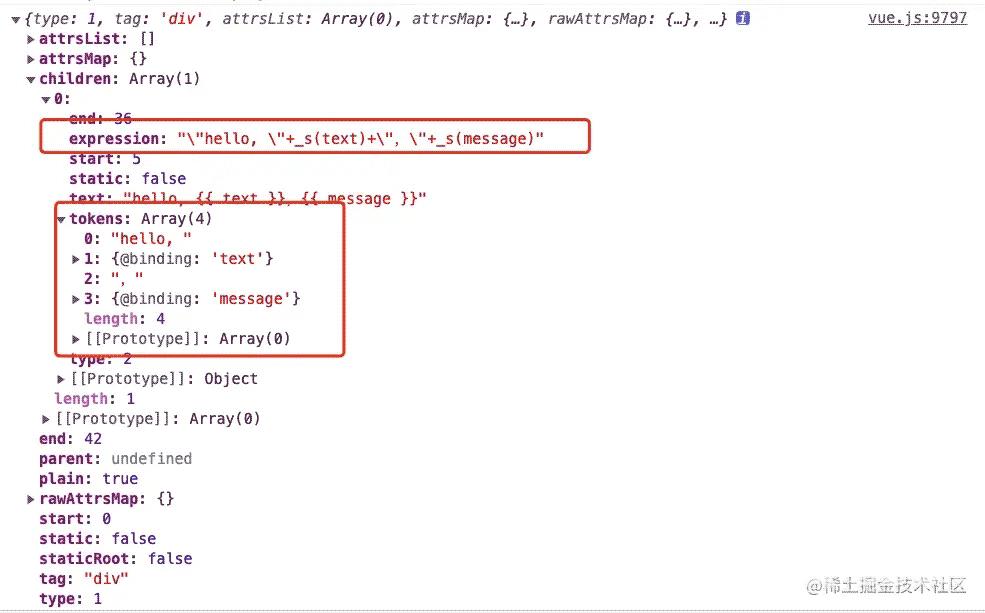
例如有一段这样的 template:
// text: '小白',
// message: '好久不见'
<div>hello, {{ text }},{{ message }}</div>
会被解析成如下 AST:
closeElement 函数
这个函数会在解析非一元开始标签和解析结束标签的时候调用,主要作用有两个:
- 对数据状态进行还原,
- 调用后置处理转换钩子函数。
整体流程
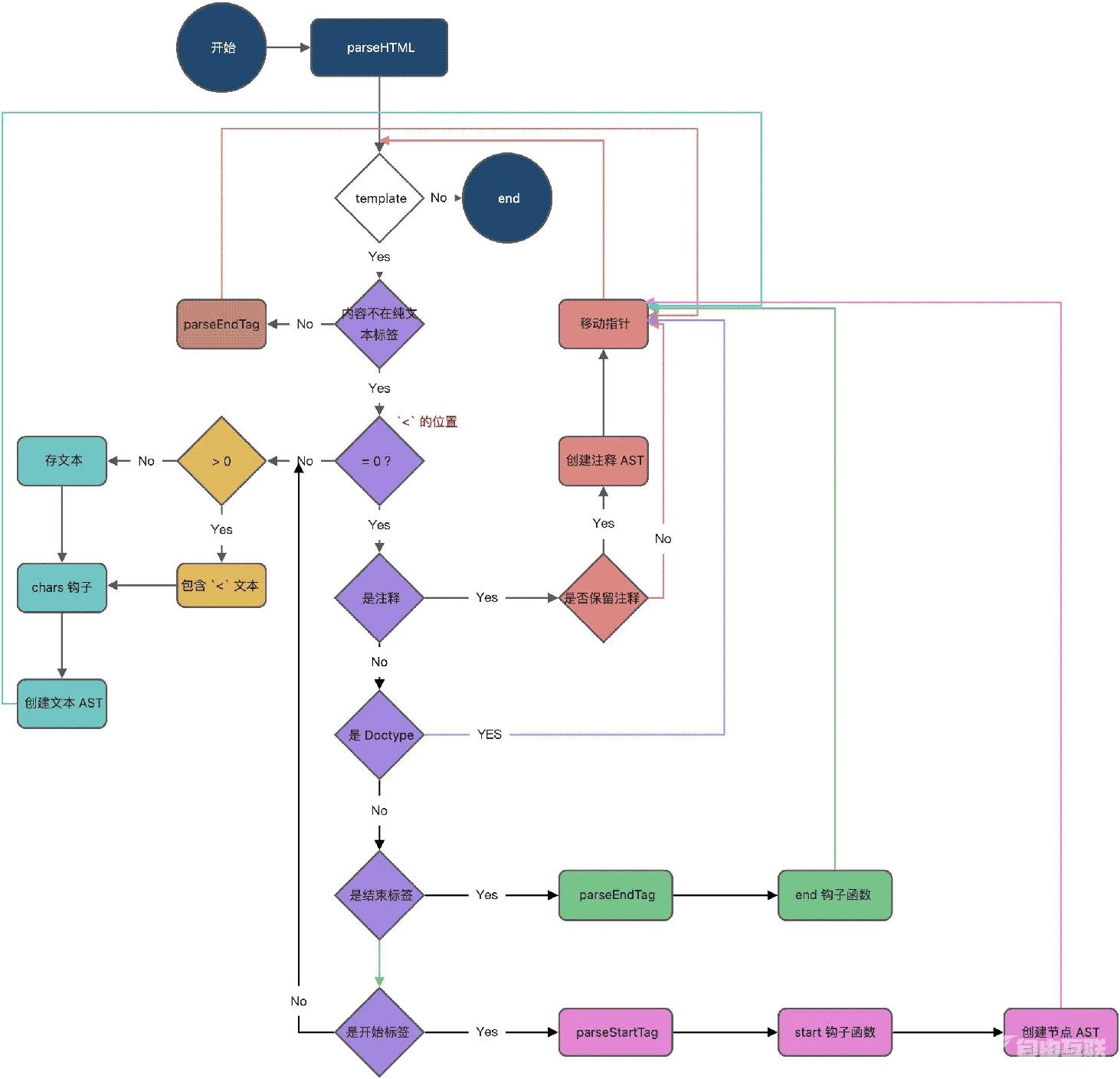
总结
Vue 编译三部曲第一步 parse的整个流程就已经分享完了,虽然源码看似非常的复制,但是如果只是抽离主流程的话,还是比较简单的。parse 的目的是将开发者写的 template 模板字符串转换成抽象语法树 AST ,AST 就这里来说就是一个树状结构的 JavaScript 对象,描述了这个模板,这个对象包含了每一个元素的上下文关系。那么整个 parse 的过程是利用很多正则表达式顺序解析模板,当解析到开始标签、闭合标签、文本的时候都会分别执行对应的回调函数,来达到构造 AST 树的目的。
template 编译成 AST 的过程就为大家解析到这里,下一篇为大家来分享编译中关于 「模型树的优化」。
参考
编译入口
整体流程
https://cn.vuejs.org/v2/guide/installation.html
Vue编译器源码分析 AST 抽象语法树
parseHTML 函数源码解析chars、end、comment钩子函数
parseHTML 函数源码解析AST 基本形成
https://github.com/vuejs/vue/issues/4098
更多关于Vue template编译成AST的资料请关注易盾网络其它相关文章!