
文章目录
- 前言
- 读入评论数据集
- 用Tokenizer给文本分词
- 构建长度统一词向量
- 构建RNN神经网络
- 完整代码如下
博文配套视频课程:自然语言处理与知识图谱
前言
前面的理论和原理介绍完了,接下来回到鉴定文本的情感属性这个案例。可以先把文本向量化,然后在通过Keras构建最简单循环神经网络SimpleRNN层。最后得出结论哪些客户是好评,哪些客户是差评。
读入评论数据集
该项目涉及到的代码和数据文件可以通过百度云盘进行下载,提取密码:lsqz。同学们也可以通过Kaggle网站通过关键字Product Comments 搜索该数据集进行下载。
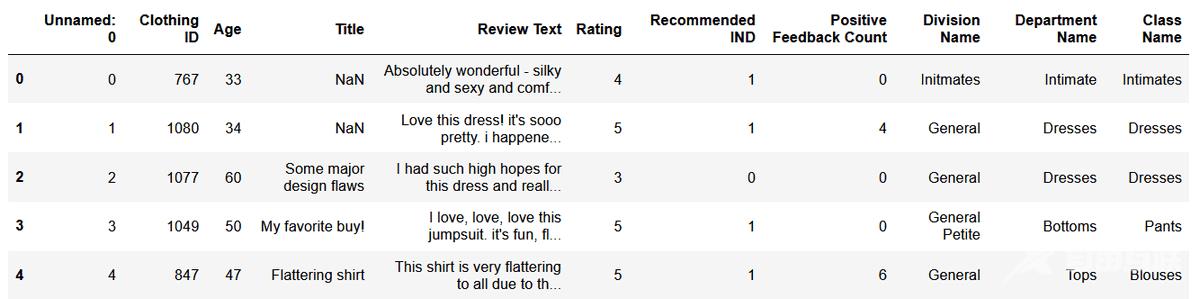
import pandas as pddf = pd.read_csv("../data/Clothing Reviews.csv")df.head()df[Review Text] = df[Review Text].astype(str)x_train = df[Review Text].values # 训练集y_train = df[Rating].values
加载数据呈现如下:
用Tokenizer给文本分词
from tensorflow.keras.preprocessing.text import Tokenizer# 创建字典索引,设定词典大小为2wdict_size = 20000tokenizer = Tokenizer(num_words=dict_size)# jieba 停用词,标点符号, 词性....tokenizer.fit_on_texts(x_train) # 使用训练集创建词典索引print(len(tokenizer.word_index))# 把文本转化为序列编码 (特征工程)x_train_tokenized = tokenizer.texts_to_sequences(x_train)# list.shape ?print(len(x_train_tokenized))for v in x_train_tokenized[:50]:print(len(v),end="\t")
构建长度统一词向量
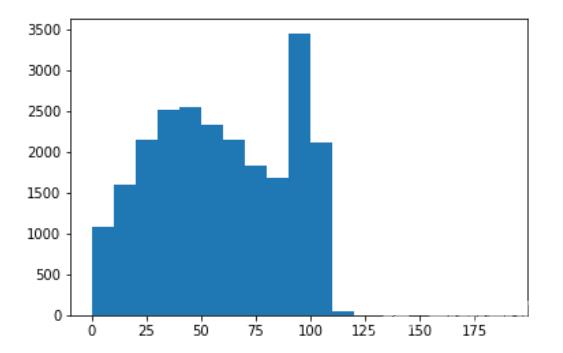
发现评论有长有短,但是后续我们要转化为向量必须是等长的,如何处理呢? 可以通过可视化(直方图)展示每个评论的长度。取一个均衡值例如120,长度超过120则截断,小于120,将填充为无意义的0值
# 通过可视化直方图展示每个评论的长度import matplotlib.pyplot as plt # 导入matplotlibimport numpy as npword_per_comment = [len(comment) for comment in x_train_tokenized]plt.hist(word_per_comment,bins=np.arange(0,200,10))plt.show()# 就是把不等长的list变成等长from tensorflow.keras.preprocessing.sequence import pad_sequencesmax_comment_length = 120 # 设定评论输入长度为120x_train = pad_sequences(x_train_tokenized,maxlen=max_comment_length)for v in x_train[:50]:print(len(v), end="\t")
构建RNN神经网络
from tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Densefrom tensorflow.keras.layers import SimpleRNN,Embeddingimport tensorflow as tfrnn = Sequential()# (None, 120, 60) ==> (评论数,每条评论长度,词向量) ==> (评论数,词向量)# [batch,feature len] @ [feature len, hideen len] ==> [batch,hidden len]# [batch,hidden len] @ [hidden len hidden len] ==> [batch,hideen len]# [b,60] @ [60,100] ==> [b,100] + [b,100] @ [100,100] ==> [b,100]rnn.add(SimpleRNN(units=100)) # 第二层构建了100个RNN神经元# [b,100] @ [100,10] ==> [b,10]rnn.add(Dense(units=10,activation=tf.nn.relu))# [b,10] @ [10,5] ==> [b,5]# 如果设置为5 则未来的数据也需要进行转化rnn.add(Dense(units=5,activation=tf.nn.softmax)) # 输出分类的结果rnn.compile(loss=sparse_categorical_crossentropy,optimizer="adam",metrics=[accuracy])print(rnn.summary())# epochs = 1 测试随机数 ==> tf.random.set_seed(1)# 修改为 14848 (与20000结果相同)result = rnn.fit(x_train,y_train,validation_split=0.3,epochs=10,batch_size=64)print(result)print(result.history)
生成神经网络层如下:
Model: "sequential_1"_________________________________________________________________Layer (type) Output Shape Param # =================================================================embedding (Embedding) (None, 120, 60) 1200000 _________________________________________________________________simple_rnn_1 (SimpleRNN) (None, 100) 16100 _________________________________________________________________dense_2 (Dense) (None, 10) 1010 _________________________________________________________________dense_3 (Dense) (None, 5) 55 =================================================================Total params: 1,217,165Trainable params: 1,217,165Non-trainable params: 0_________________________________________________________________
完整代码如下
import pandas as pddf = pd.read_csv("../data/Clothing Reviews.csv")print(df.info())df[Review Text] = df[Review Text].astype(str)x_train = df[Review Text]y_train = df[Rating]from tensorflow.keras.preprocessing.text import Tokenizer# 创建词典的索引,默认词典大小20000dict_size = 20000tokenizer = Tokenizer(num_words=dict_size)# 词与索引映射关系print(len(tokenizer.word_index),tokenizer.index_word)# 把评论的文本转化序列编码x_train_tokenized = tokenizer.texts_to_sequences(x_train)print(x_train_tokenized)# 通过指定长度,把不等长list转化为等长from tensorflow.keras.preprocessing.sequence import pad_sequencesmax_comment_length = 120x_train = pad_sequences(x_train_tokenized,maxlen=max_comment_length)for v in x_train[:10]:print(v,len(v))from tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Densefrom tensorflow.keras.layers import SimpleRNN,Embeddingimport tensorflow as tfrnn = Sequential()# 词嵌入操作学习到的结果为向量长度为60的密集矩阵rnn.add(Embedding(input_dim = dict_size,output_dim = 60,input_length=max_comment_length))rnn.add(SimpleRNN(units=100)) # 构建100 RNN循环神经元rnn.add(Dense(10,activation=tf.nn.relu)) # 全连接层rnn.add(Dense(5,activation=tf.nn.softmax)) # 全连接层输出分类的结果rnn.compile(loss=sparse_categorical_crossentropy,optimizer=adam,metrics=[accuracy])print(rnn.summary())# history = rnn.fit(x_train,y_train,validation_split=0.3,epochs=10,batch_size=64)
