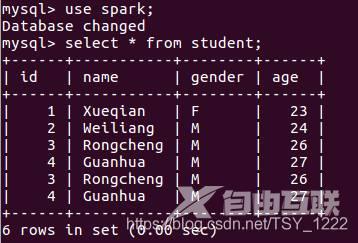
JDBC(Java DataBase Connectivity, java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。
1、准备工作
•在Linux中启动MySQL数据库
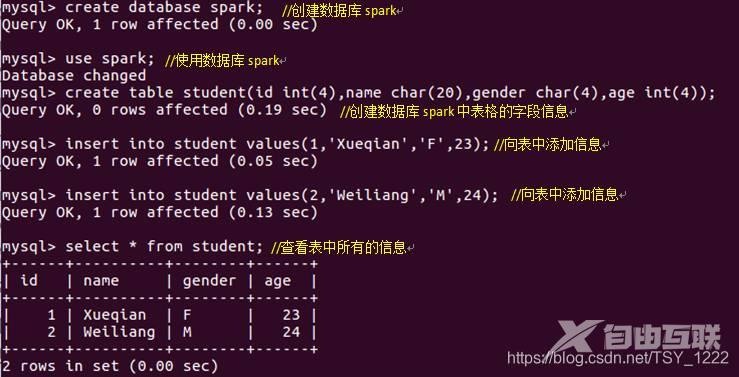
•在MySQL Shell环境中,输入下面SQL语句完成数据库和表的创建:(MySQL每条语句后面都要加分号“ ; ”)
•要想顺利连接MySQL数据库,需要使用MySQL数据库驱动程序。
•下载MySQL的JDBC驱动程序,比如mysql-connector-java-5.1.40.tar.gz
•把该驱动程序解压到spark的安装目录” /usr/local/spark/jars”下

•启动一个spark-shell,启动Spark Shell时,必须指定mysql连接驱动jar包。(每条语句后面加“ \ ”)

2、读取MySQL数据库中的数据
spark.read.format("jdbc")操作可以实现对MySQL数据库的读取,执行以下命令连接数据库,读取数据,并显示:
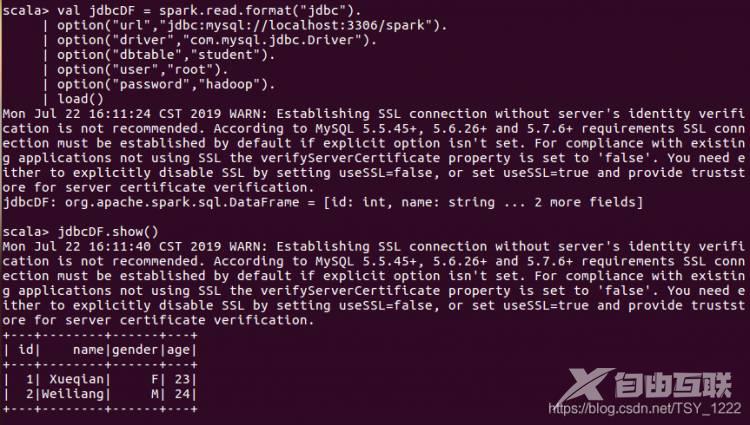
在通过JDBC连接MySQL数据库时,通过option()方法设置相关的连接参数,各个参数的意义,如下表:
参数名称 参数的值 含义urljdbc:mysql://localhost:3306/spark数据库的连接地址drivercom.mysql.jdbc.Driver数据库的JDBC驱动程序dbtablestudent所要访问的表userroot用户名passwordhadoop用户密码3、向MySQL数据库写入数据
在MySQL数据库中,已经创建了一个名称为spark的数据库,并创建了一个名称为student的表,向MySQL数据库中写入两条记录。为了对比数据库记录的变化,先查看一下数据库的当前内容:
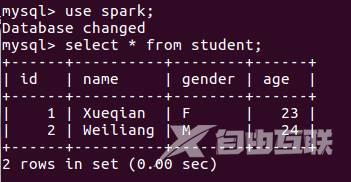
向spark.student表中插入两条记录的完整代码如下:
进入Spark shell环境时,

①、导入包
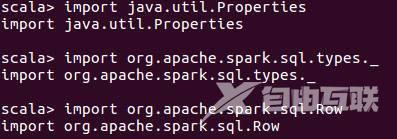
②、下面设置两条数据,表示两个学生的信息。

③、设置模式信息,schema就是“表头”

④、创建Row对象,每个Row对象都是rowRDD中的一行

⑤、建立Row对象和模式之间的对应关系,也就是把数据和模式对应起来,studentDF是一个DataFrame。

⑥、创建一个prop变量用来保存JDBC连接参数。
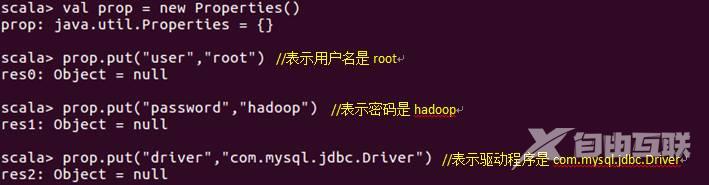
⑦、连接数据库,采用append模式,表示追加记录到数据库spark的student表中。

⑧、进入MySQL Shell环境中使用SQL语句查询student表。

(一不小心添加了两次=.=)