1、分类模型评估指标
一、sklearn.metrics提供分类算法模型的评估指标
# 实例数据iris = load_iris()# 分割测试集和训练集x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=1)# 实例模型clf = DecisionTreeClassifier()# 训练模型clf.fit(x_train, y_train)# 预测测试集数据y_data = clf.predict(x_test)"""精确率:precision_score()(重)"""print("精确率评估方法的分数:", precision_score(y_test, y_data, average='micro'))"""F1值f1_score()(重)"""print("F1值评估方法的分数:", f1_score(y_test, y_data, average='micro'))# 注意点,如果是二分类的话average不需要更改,如果是多分类则需要更改为 {'micro', 'macro', 'samples', 'weighted'}# 模型评分过低时这几个参数换着来,哪个分数高换哪个##################################################################"""召回率recall_score()"""# 待补充代码##################################################################"""Cohen's Kappa系数:cohen_kappa_score()"""# 待补充代码##################################################################"""除了以上4中单一的评估方法,还提供输出评估指标报告的函数classification_report,可以输出上方4种评估指标"""# 待补充代码##################################################################"""ROC曲线:roc_curve(),本质上是把用图形画出结果,图形与x轴组合的面积越大,模型越好"""# 待补充代码
2、回归模型评估指标
一、sklearn.metrics模块提供回归算法模型的评估指标
# 提取数据housevalue = fetch_california_housing()x = housevalue.datay = housevalue.target# 分数据集x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)# 建立模型model = LinearRegression()# 训练模型model.fit(x_train, y_train)# 预测数据g = model.predict(x_test)# 均方误差:mean_squared_error(),越接近0越好print("均方误差", mean_squared_error(y_test, g))# 中值绝对误差(median_absolute_error()),越接近0越好print("平方绝对误差", mean_absolute_error(y_test, g))"""可解释方差值(explained_variance_score())"""# 待补充代码##################################################################"""R2值(r2_score())"""# 待补充代码
3、聚类模型评估指标
一、sklearn.metrics模块提供聚类模型评估指标
"""Calinski-Harabasz指数评价方法:calinski_harabasz_score()(重)"""# 这里的数据时使用make_blob生成的数据"""make_blobs用于生成聚类函数的样本n_samples:样本个数n_features: 数据的特征数量centers:数据的中心点(表示数据都是围绕着设定的这几个核心来创建的)random_state:随机模式"""x, y = make_blobs(n_samples=500, n_features=2, centers=3, random_state=1)# 创建模型,质心为4个k = KMeans(n_clusters=4, random_state=1)# 训练模型得出训练的结果data = k.fit(x)# 查看训练结果中每一个点所属的质心labels = data.labels_# 使用calinski_harabasz_score评估模型,传入点的数据和所属质心的数据,评分越大模型越好print(calinski_harabasz_score(x, labels=labels))##################################################################"""ARI评价方法(兰德系数):adjusted_rangd_score()"""# 待补充代码##################################################################"""AMI评价方法(互信息):adjusted_mutual_info_score()"""# 待补充代码##################################################################"""V-measure评分:completeness_score()"""# 待补充代码##################################################################"""FMI评价法:owlkes_mallows_score()"""# 待补充代码##################################################################"""轮廓系数评价法:silhouette_score()"""# 待补充代码
4、逻辑回归使用两种方法来评估模型
一、sklearn.metrics模块提供聚类模型评估指标二、计算方法
第一种
confusion_matrix(真实值,预测值):算出TP、FN、FP、TN这个二维矩阵accuracy_score(真实值,预测值):通过accuracy = (TP + TN / TP + FN + FP + TN)算出评估指标TP:真阳性、TN:真阴性、FN:假阴性(需要避免这种数据,最严重的错误)、FP:加阳性(也需要避免)
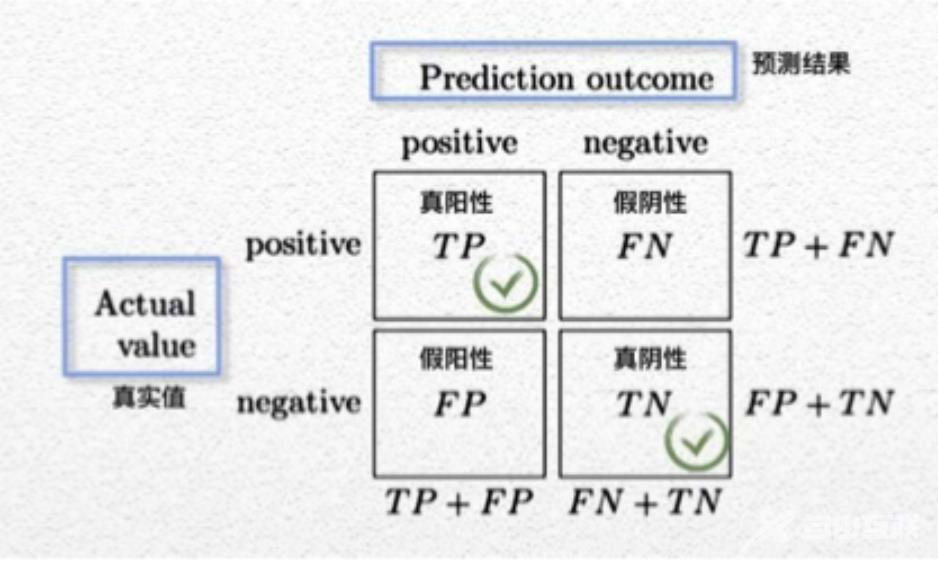
# 使用metrics中的accuracy_score(真实值,预测值)来评估模型# 取出数据data = load_breast_cancer()# 分割数据x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3)# 建立模型model = LogisticRegression(penalty="l1", solver="liblinear")# 训练模型model.fit(x_train, y_train)# 计算预测值y_pred = model.predict(x_test)# 评估模型print("使用accuracy_score预测的结果", accuracy_score(y_test, y_pred))print("使用confusion_matrix搭建混淆矩阵预测的结果\n", confusion_matrix(y_test, y_pred))
第二种
既是使用ROC绘制曲线来评估模型,与x轴组成的面积越大模型越好代码待补充