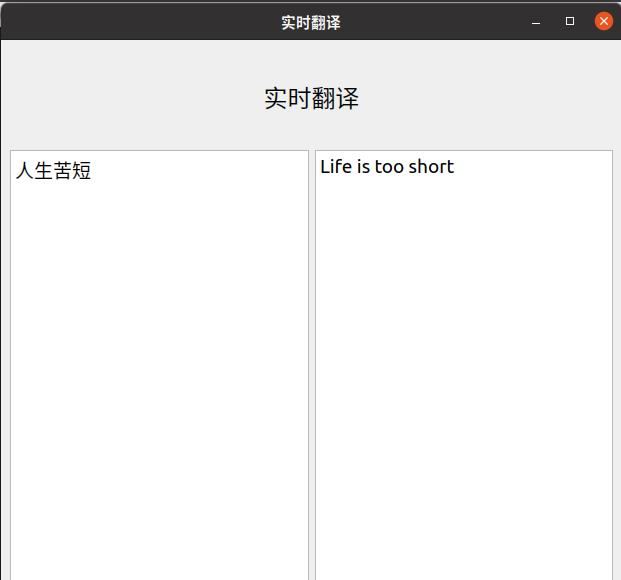
1.设计ui界面效果如下
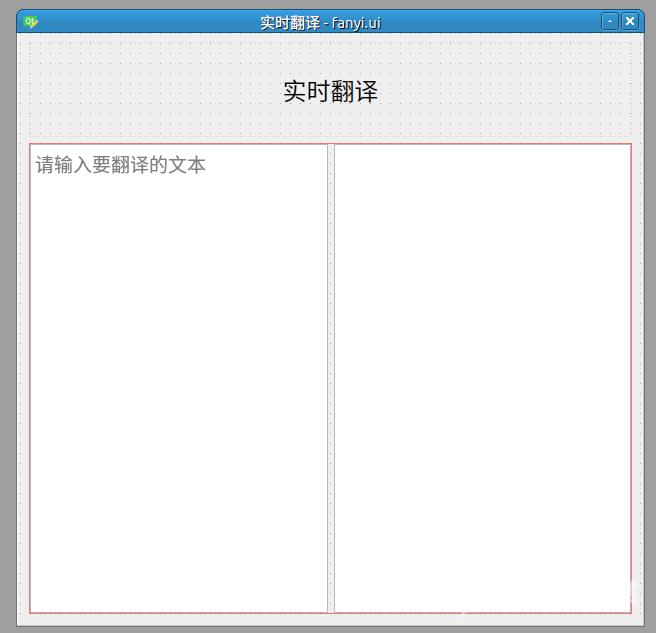
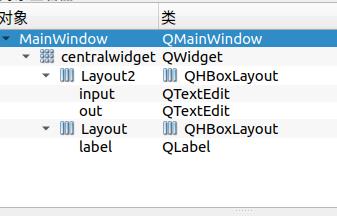
placeholderText为请输入要翻译的文本。
2.编写translate.py文件
这里用的是python内置的HTTP请求库urllib数据库可以更加有效的进行爬取。包括四个模块;
第一个模块 request它是最基本的 HTTP 请求模块我们可以用它来模拟发送一请求就像在浏览器里输入网址然后敲击回车一样只需要给库方法传入 URL 还有额外的参数就可以模拟实现这个过程了。
第二个 error 模块即异常处理模块如果出现请求错误我们可以捕获这些异常然后进行重试或其他操作保证程序不会意外终止。
第三个 parse 模块是一个工具模块提供了许多 URL 处理方法比如拆分、解析、合并等等的方法。
第四个模块是 robotparser主要是用来识别网站的 robots.txt 文件然后判断哪些网站可不可以爬取。
下面是程序代码
import urllib.request
import urllib.parse
import json
import *from PyQt5.QtWidgets
import QApplication, QMainWindowfrom PyQt5.QtGui
import QIconfrom Ui_translate
import Ui_MainWindow
class App(QMainWindow, Ui_MainWindow):
def __init__(self, parentNone):
super(App, self).__init__(parent)
self.setWindowIcon(QIcon(translateIcon.ico))
self.master 0
self.setupUi(self)
self.data {}
self.urlhttp://fanyi.youdao.com/translate?smartresultdictrule
self.data[doctype] json #文档类型
def translateText(self):
text self.translate_in.toPlainText()
if text ! :
self.data[i] text
data urllib.parse.urlencode(self.data).encode(utf-8) #将data以utf-8的形式编码。urlencode主要作用就是将url附上要提交的数据。
request urllib.request.urlopen(self.url, data) #获得响应用data访问代码中的url链接
html request.read().decode(utf-8) #读取打开的网页并进行utf-8解码
target json.loads(html) #识别json取出需要的数据
result [] #返回结果
for i in range(len(target[translateResult])): #for循环
res target[translateResult][i][0][tgt]
result.append(res)
self.translate_out.setPlainText(\n.join(result))
if __name__ __main__:
app QApplication(sys.argv) #pyqt窗口必须在QApplication方法中使用
MainWindow App() #生成App类的实例MainWindow
MainWindow.show() #MainWindow调用show方法
sys.exit(app.exec()) #消息结束时结束进程并返回0接着调用sys.exit()退出程序3.运行效果