xs 用于多重索引中,先创立一个二级行索引的dataframe,如下所示: np.arrays = [[one, one, one, two, two, two], [1, 2, 3, 1, 2, 3]]df = pd.DataFrame(np.random.randn(6, 2), index = pd.MultiIndex.from_tuples(list(zip(*np.
xs用于多重索引中,先创立一个二级行索引的dataframe,如下所示:
np.arrays = [['one', 'one', 'one', 'two', 'two', 'two'], [1, 2, 3, 1, 2, 3]] df = pd.DataFrame(np.random.randn(6, 2), index = pd.MultiIndex.from_tuples(list(zip(*np.arrays))), columns = ['A', 'B']) df
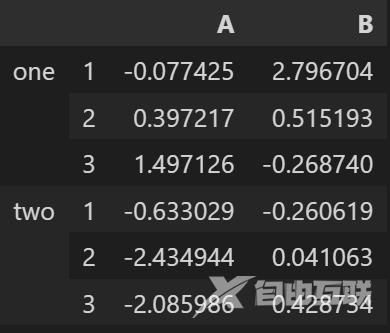
数据集如下展示:
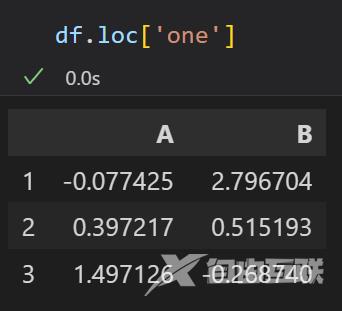
使用df.loc[‘one’]
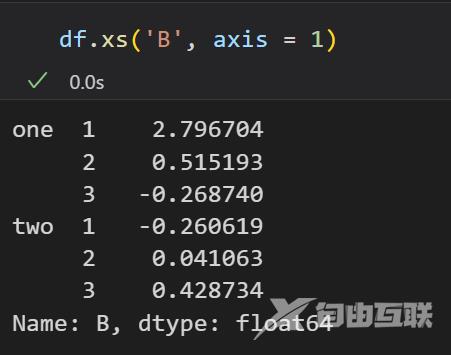
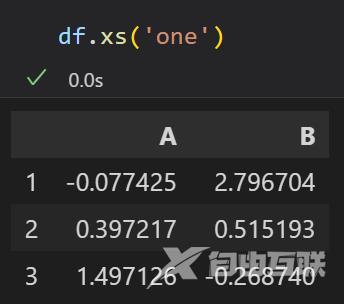
使用df.xs(‘one’)
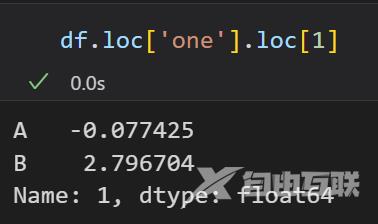
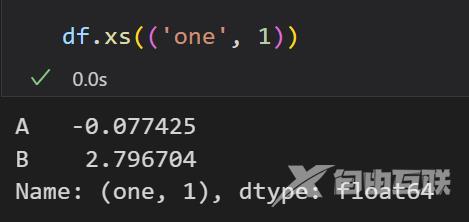
用df.xs(('one', 1))
用loc的方法