本期为 知乎热榜/微博热搜时序图 系列文章 上篇 内容,给大家介绍如何使用Python定时爬取知乎热榜/微博热搜数据,并保存至CSV文件供后续可视化使用,时序图部分将在 下篇 内容中介
本期为<知乎热榜/微博热搜时序图>系列文章上篇内容,给大家介绍如何使用Python定时爬取知乎热榜/微博热搜数据,并保存至CSV文件供后续可视化使用,时序图部分将在下篇内容中介绍,希望对你有所帮助。
read_html — 网页表格处理
import json import time import requests import schedule import pandas as pd from fake_useragent import UserAgent
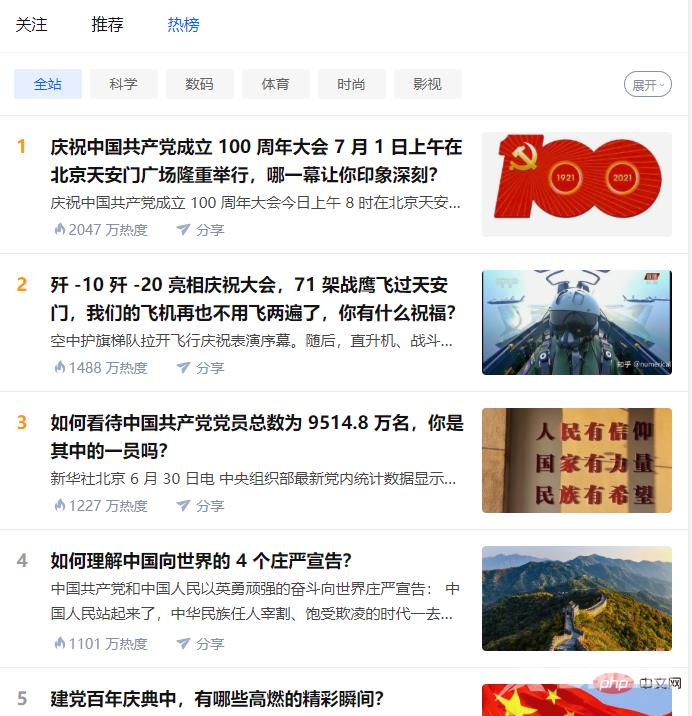
https://www.zhihu.com/hot
https://api.zhihu.com/topstory/hot-list?limit=10&reverse_order=0
注意:电脑端端直接F12调试页即可看到热榜数据,手机端需要借助抓包工具查看,这里我们使用手机端接口(返回json格式数据,解析比较方便)。
代码:
def getzhihudata(url, headers):
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
datas = json.loads(r.text)['data']
allinfo = []
time_mow = time.strftime("%Y-%m-%d %H:%M", time.localtime())
print(time_mow)
for indx,item in enumerate(datas):
title = item['target']['title']
heat = item['detail_text'].split(' ')[0]
answer_count = item['target']['answer_count']
follower_count = item['target']['follower_count']
href = item['target']['url']
info = [time_mow, indx+1, title, heat, answer_count, follower_count, href]
allinfo.append(info)
# 仅首次加表头
global csv_header
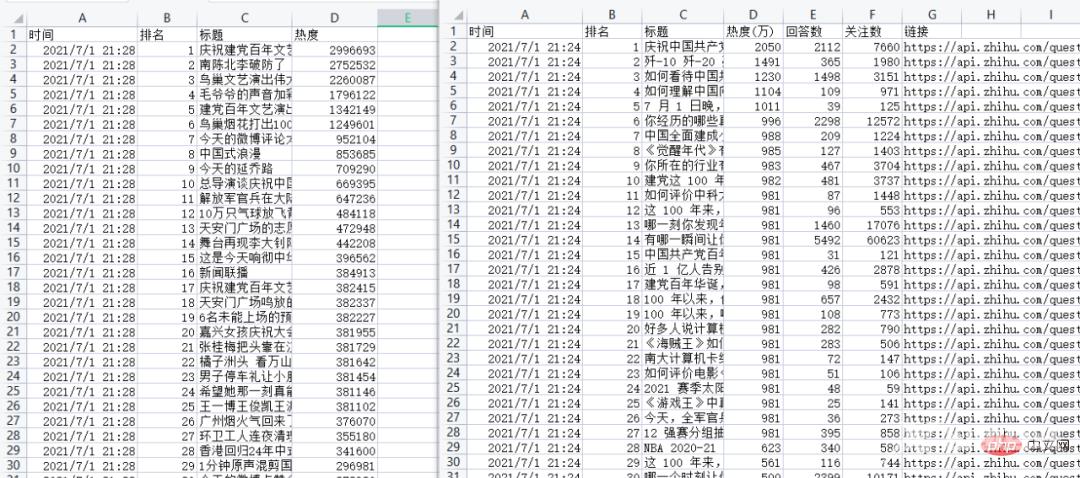
df = pd.DataFrame(allinfo,columns=['时间','排名','标题','热度(万)','回答数','关注数','链接'])
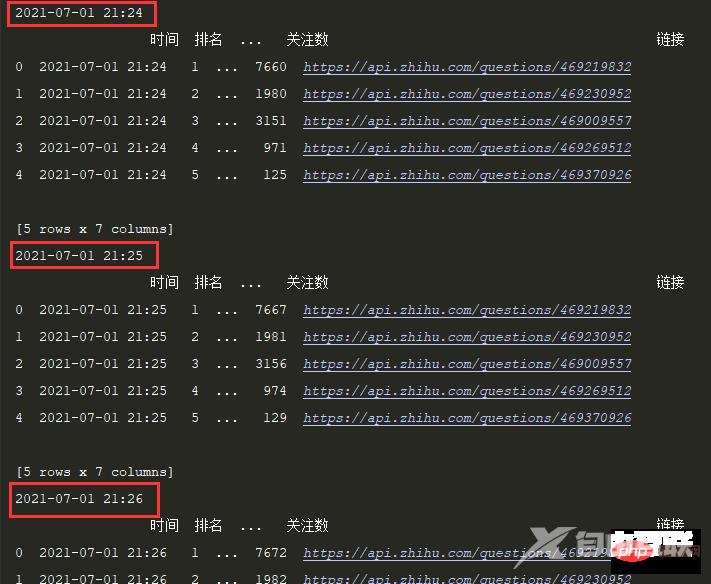
print(df.head())定时间隔设置1S:
# 每1分钟执行一次爬取任务:
schedule.every(1).minutes.do(getzhihudata,zhihu_url,headers)
while True:
schedule.run_pending()
time.sleep(1)效果:
2.3 保存数据
df.to_csv('zhuhu_hot_datas.csv', mode='a+', index=False, header=csv_header)
csv_header = False3.1 网页分析
微博热搜网址:
https://s.weibo.com/top/summary
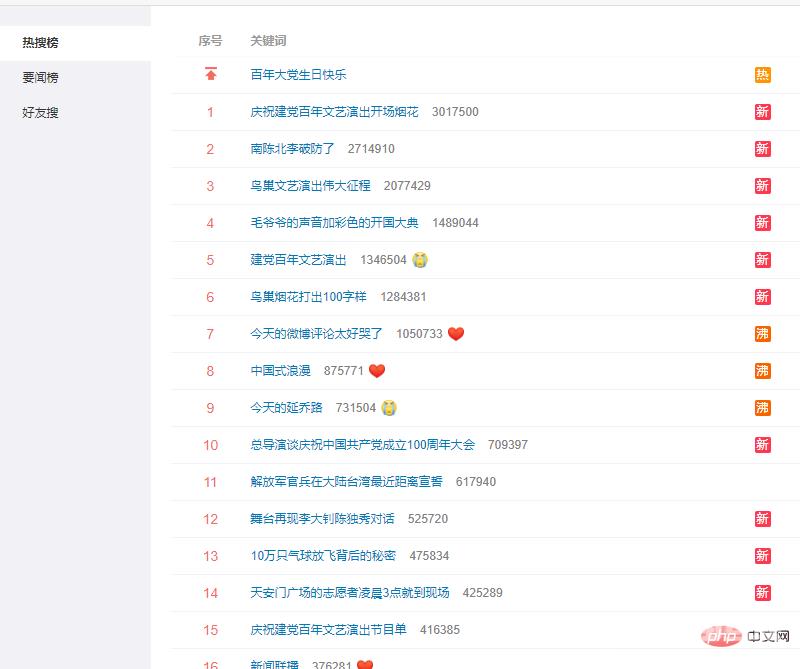
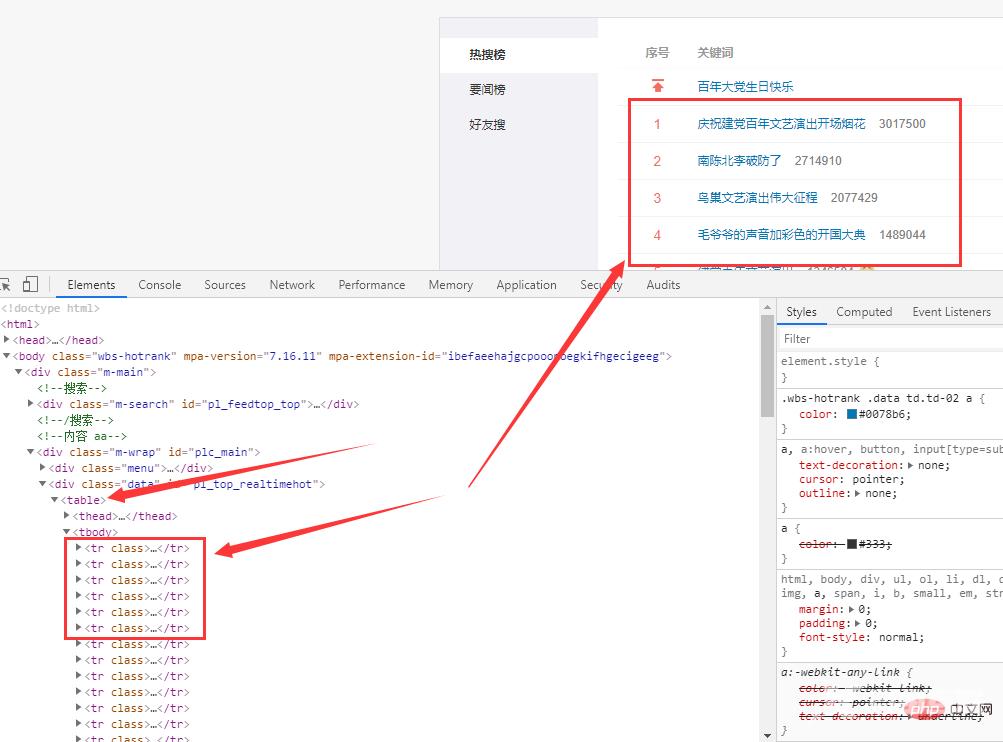
数据在网页的<table>标签里。
3.2 获取数据
代码:
def getweibodata():
url = 'https://s.weibo.com/top/summary'
r = requests.get(url, timeout=10)
r.encoding = r.apparent_encoding
df = pd.read_html(r.text)[0]
df = df.loc[1:,['序号', '关键词']]
df = df[~df['序号'].isin(['•'])]
time_mow = time.strftime("%Y-%m-%d %H:%M", time.localtime())
print(time_mow)
df['时间'] = [time_mow] * df.shape[0]
df['排名'] = df['序号'].apply(int)
df['标题'] = df['关键词'].str.split(' ', expand=True)[0]
df['热度'] = df['关键词'].str.split(' ', expand=True)[1]
df = df[['时间','排名','标题','热度']]
print(df.head())定时间隔设置1S,效果:
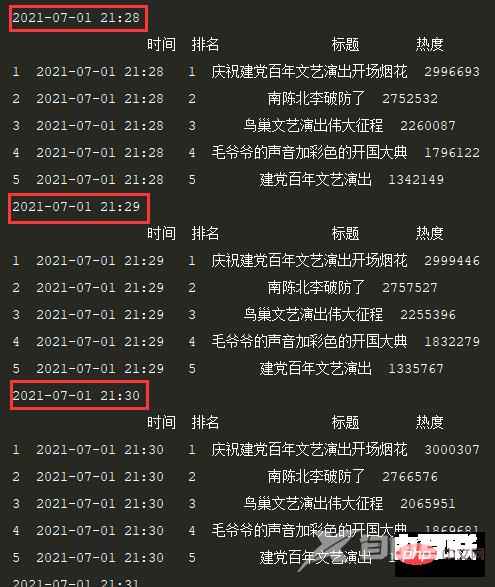
3.3 保存数据
df.to_csv('weibo_hot_datas.csv', mode='a+', index=False, header=csv_header)结果: