1.前言
在平时的开发中,Java集合一直是比较常用的。以前,对集合的掌握并不深入,仅简单的使用增删改查的相关方法。这个星期,抽时间反复的读了几遍ArrayList的源码,有了一些收获,写出来给自己,也希望对大家有帮助。
2.走进ArrayList
- 看一下ArrayList的声明和属性
声明:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
属性:
private transient Object[] elementData;
private int size;
分析:
- ArrayList内部维护了一个Object[]数组,数组有一个大小,即ArrayList的容量。同时ArrayList还有一个int变量来标示实际列表的大小。
- 注意到ArrayList实现了RandomAccess,Cloneable,Serializable接口
RandomAccess接口,其实并无方法需要实现,只是一个标示。说明ArrayList可以快速访问,说白了就是可以通过下标索引的方式进行随机访问。
疑问:那么对于ArrayList而言,访问的方式,有 迭代遍历/随机访问/增强FOR循环,哪一种方式更加快速呢?
Serializable接口,同上,也是一个标示接口。注意到transient修饰了object[],说明在序列化的时候,object[]并不会序列化,那么反序列化的时候,object[]将为null。是这样吗?
疑问:很显然,ArrayList的很多方法必然是要操作object[]的,如果我们对ArrayList的对象实例进行了序列化,然后反序列化,最终object[]由于被transient修饰了,读出来是一个null。这显然是不行的,那么ArrayList对序列化做了哪些处理?
Cloneable接口亦是一个标示接口,表示可以进行对象的克隆。ArrayList复写了Object类的clone()方法。
疑问:克隆,深拷贝 OR 浅拷贝 ?
下面,我们一个疑问一个疑问的解决。
- 迭代器遍历 VS 随机访问 VS 增强FOR循环
看一个测试例子:
//构造一个大列表用于测试
List<String> list = new ArrayList<String>();
for ( int i = 0 ; i < 1000000 ; i++){
list.add( "" + i);
}
long start = System.currentTimeMillis();
Iterator<String> it = list.iterator();
while (it.hasNext()){
//遍历进行我们的业务操作
it.next();
}
System.out.println( "iterator访问耗时(ms) : " + (System.currentTimeMillis() - start));
start = System.currentTimeMillis();
int length = list.size();
for ( int i = 0 ; i < length ; i++){
//遍历进行我们的业务操作
list.get(i);
}
System.out.println( "index访问耗时(ms) : " + (System.currentTimeMillis() - start));
start = System.currentTimeMillis();
for (String tmp : list){
//遍历进行我们的业务操作
}
System.out.println( "for-each访问耗时(ms) : " + (System.currentTimeMillis() - start));
运行结果如下:
iterator访问耗时(ms) : 47
index访问耗时(ms) : 15
for-each访问耗时(ms) : 47
结论:
对于支持RandomAccess的列表而言,用索引的方式进行访问是非常快速的。虽然,迭代器和增强FOR循环写法上简单,但是效率并不高。
- ArrayList的序列化分析
阅读下java.io.Serializable的代码,发现有如下说明:
Classes that require special handling during the serialization and
deserialization process must implement special methods with these exact
signatures:
private void writeObject(java.io.ObjectOutputStream out)
throws IOException
private void readObject(java.io.ObjectInputStream in)
throws IOException, ClassNotFoundException;
private void readObjectNoData()
throws ObjectStreamException;
上面的意思就是说:
在序列化和反序列化过程中需要特殊处理的类必须使用上面的准确签名来实现特殊方法。
下面,我们看一下ArrayList是否提供了这些方法的签名。
private void writeObject(ObjectOutputStream objectoutputstream)
throws IOException
{
int i = modCount;
objectoutputstream.defaultWriteObject();
objectoutputstream.writeInt(elementData.length);
for ( int j = 0 ; j < size; j++)
objectoutputstream.writeObject(elementData[j]);
if (modCount != i)
throw new ConcurrentModificationException();
else
return ;
}
private void readObject(ObjectInputStream objectinputstream)
throws IOException, ClassNotFoundException
{
objectinputstream.defaultReadObject();
int i = objectinputstream.readInt();
Object aobj[] = elementData = new Object[i];
for ( int j = 0 ; j < size; j++)
aobj[j] = objectinputstream.readObject();
}说明:
有时候,ArrayList的容量是大于列表的实际大小的,如果序列化和反序列化object[]的所有元素,会消耗更多的资源,因此将object[]声明为transient,不调用默认的序列化/反序列化方法,而是提供自己的序列化、反序列化实现,从而仅仅序列化实际列表的元素。
- 浅拷贝 AND 深拷贝

举例说明:
Book:
public class Book implements Cloneable{
private String name;
private double price;
private Author author;
@Override
protected Object clone() throws CloneNotSupportedException {
// TODO Auto-generated method stub
return super .clone();
}
public Book(String name, double price, Author author) {
super ();
this .name = name;
this .price = price;
this .author = author;
}
//setter,getter...
}
Author:
public class Author {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this .name = name;
}
public Author(String name) {
super ();
this .name = name;
}
}测试:
Author author = new Author( "zhangfengzhe" );
Book book1 = new Book( "java" , 1 ,author);
Book book2 = (Book)book1.clone();
System.out.println( "book1 : " + book1.getName() + " , author:" +
book1.getAuthor().getName());
System.out.println( "book2 : " + book2.getName() + " , author:" +
book2.getAuthor().getName());
book2.setName( "python" );
System.out.println( "book1 : " + book1.getName() + " , author:" +
book1.getAuthor().getName());
System.out.println( "book2 : " + book2.getName() + " , author:" +
book2.getAuthor().getName());
author.setName( "lisi" );
System.out.println( "book1 : " + book1.getName() + " , author:" +
book1.getAuthor().getName());
System.out.println( "book2 : " + book2.getName() + " , author:" +
book2.getAuthor().getName());
结果:
book1 : java , author:zhangfengzhe
book2 : java , author:zhangfengzhe
book1 : java , author:zhangfengzhe
book2 : python , author:zhangfengzhe
book1 : java , author:lisi
book2 : python , author:lisi
说明:
如果一个类实现了Cloneable接口,并提供了默认的clone(),那么这个类的对象就具备了克隆的能力,并且JAVA的默认的clone()是对象的浅拷贝。
那么,在实际开发中,我们常常需要深拷贝,应该如何做呢?
第一种方式:改写clone()方法
核心逻辑如下:
@Override
public Object clone() throws CloneNotSupportedException {
// TODO Auto-generated method stub
Book tmp = (Book) super .clone();
tmp.author = (Author)author.clone();
return tmp;
}
实际上,就是将Book类中的所有对象类型手动的来一次clone
第二种方式:序列化
Book,Author不需要在实现Cloneable,而是需要实现Serializable。同时Book提供一个深拷贝的方法,如下:
public Object deepCopy() throws Exception{
// 将对象写到流里
ByteArrayOutputStream bo = new ByteArrayOutputStream();
ObjectOutputStream oo = new ObjectOutputStream(bo);
oo.writeObject( this );
// 从流里读出来
ByteArrayInputStream bi = new ByteArrayInputStream(bo.toByteArray());
ObjectInputStream oi = new ObjectInputStream(bi);
return (oi.readObject());
}将对象进行串行话后进行传递,是比较耗时的。
有了上面的知识,我们来看一下ArrayList中的clone()实现:
public Object clone()
{
try
{
ArrayList arraylist = (ArrayList) super .clone();
arraylist.elementData = Arrays.copyOf(elementData, size);
arraylist.modCount = 0 ;
return arraylist;
}
catch (CloneNotSupportedException clonenotsupportedexception)
{
throw new InternalError();
}
}看一个测试例子:
ArrayList<Student> stus = new ArrayList<Student>();
stus.add( new Student( 20 , "zfz" ));
ArrayList<Student> stus2 = (ArrayList<Student>)stus.clone();
stus2.get( 0 ).setName( "lisi" );
System.out.println(stus.get( 0 ).getName() + "," + stus2.get( 0 ).getName());运行结果:
lisi,lisi
实际上,JAVA默认的就是浅拷贝,而浅拷贝可能带来问题。
- ArrayList增删改查实现原理分析
先不看ArrayList怎么实现,就自己而言,应该如何实现呢?
增加:
- 数组的容量够吗?不够的话,要扩展容量
- 如果扩展容量,就是申请新的数组了,那么应该要将以前的数组的数据COPY过来

实际上,ArrayList的add方法的实现原理就是这样的。会调用ensureCapacity方法来确保数组容量,注意size也会变化。插入的过程,就是数组元素复制和移动的过程,因此这会比较耗时。
删除,可以同上分析。
查找,直接看一下indexOf方法的实现:
public int indexOf(Object obj)
{
if (obj == null )
{
for ( int i = 0 ; i < size; i++)
if (elementData[i] == null )
return i;
} else
{
for ( int j = 0 ; j < size; j++)
if (obj.equals(elementData[j]))
return j;
}
return - 1 ;
}其实,针对查找的对象是否为null,以决定在索引遍历过程中是用 == 还是 equals
lastIndexOf方法不过是逆向查找而已,思路一致。
先不看ArrayList怎么实现,就自己而言,应该如何实现呢?
增加:
- 数组的容量够吗?不够的话,要扩展容量
- 如果扩展容量,就是申请新的数组了,那么应该要将以前的数组的数据COPY过来
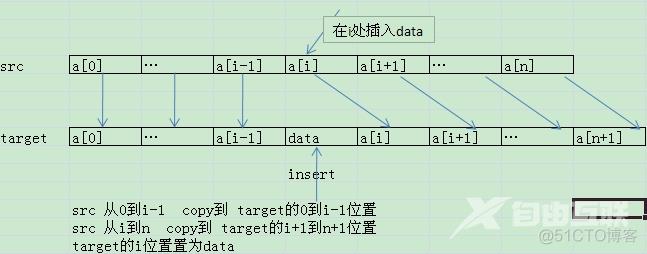
实际上,ArrayList的add方法的实现原理就是这样的。会调用ensureCapacity方法来确保数组容量,注意size也会变化。插入的过程,就是数组元素复制和移动的过程,因此这会比较耗时。
删除,可以同上分析。
查找,直接看一下indexOf方法的实现:
其实,针对查找的对象是否为null,以决定在索引遍历过程中是用 == 还是 equals
lastIndexOf方法不过是逆向查找而已,思路一致。
- 构造ArrayList
ArrayList提供了3种构造方法。默认情况下,会构造一个大小为10的Object[]。
public ArrayList( int i){...}
public ArrayList()
{
this ( 10 );
}
public ArrayList(Collection collection){...}
通过对ArrayList的add/addAll分析,为了确保数组容量,会调用ensureCapacity方法。
查看下ensureCapacity方法的代码:
public void ensureCapacity( int i)
{
modCount++;
int j = elementData.length;
if (i > j)
{
Object aobj[] = elementData;
int k = (j * 3 ) / 2 + 1 ;
if (k < i)
k = i;
elementData = Arrays.copyOf(elementData, k);
}
}
可以发现,在这个方法中完成了2件事情:
第一,确定新的容量,新的容量至少是 原来的容量*1.5+1
第二,完成容量扩展后的数组元素复制
由于对于ArrayList使用最频繁的方法就是add,而为了确保容量,就会调用ensureCapacity方法,而在ensureCapacity中又涉及到元素的复制,多次调用这个方法必然导致效率受到影响。
如果,我们在添加大量元素前,大致判断列表的大小,在构造ArrayList指定其容量,或者构造完成后调用ensureCapacity方法,通过提前分配好空间,避免递增式的分配空间,从而提高运行速度。
看一个例子:
ArrayList<String> list = new ArrayList<String>( 1000000 );
//ArrayList<String> list = new ArrayList<String>();
long start = System.currentTimeMillis();
for ( int i = 0 ; i < 1000000 ; i++){
list.add( "" + i);
}
System.out.println( "耗时: " + (System.currentTimeMillis() - start));
提前分配容量,耗时:594
没有提前分配容量,耗时:625
说明,在大量添加元素到列表中时,考虑提前分配空间,可以提高效率。
- 列表与数组的相互转换
ArrayList转成数组
涉及到的方法是:
public Object[] toArray(){...}
public Object[] toArray(Object aobj[]){...}
有些时候,我们调用toArray()经常遇到java.lang.ClassCastException。比如:
List<String> list = new ArrayList<String>();
list.add( "1" );
String[] array = (String[])list.toArray();
究其原因,是因为toArray方法返回的是Object[],要知道将Object[]强制转化成String[]就会报:
java.lang.ClassCastException: [Ljava.lang.Object; cannot be cast to [Ljava.lang.String;
这个时候,我们应该调用的是toArray(Object aobj[])来实现。比如:
List<String> list = new ArrayList<String>();
list.add( "1" );
String[] array = (String[])list.toArray( new String[ 0 ]);
System.out.println(array[ 0 ]);实际上,toArray(Object aobj[])所返回的数组,就是aobj类型的。
数组转成ArrayList
String[] tmp = new String[ 10 ];
tmp[ 0 ] = "a" ;
tmp[ 1 ] = "b" ;
tmp[ 2 ] = "c" ;
List<String> list2 = Arrays.asList(tmp);
System.out.println(list2.get( 1 ));
利用Arrays.asList方法,省时省力。
3.ArrayList小结
- ArrayList是基于数组实现的,动态申请内存,容量可以自动增长。
- 注意到ArrayList的相关方法,都没有用synchronized修饰,显示出ArrayList在多线程的情况下是不安全的。【多线程环境下,可以考虑并发包下的CopyOnWriteArrayList或者用Collections.synchronizedList(List l)返回一个线程安全的ArrayList;或者干脆使用Vector】。
- ArrayList可以通过下标直接查找到指定元素,因此查找效率高。但是插入,删除,需要移动元素,效率低。
- 允许重复,允许null。
- 在大量添加元素到列表中时,考虑提前分配空间,可以提高效率。
- 通过索引下标的方式较迭代器、增强FOR循环,效率高。

欢迎大家访问我的个人网站
萌萌的IT人