GPU设备管理
Kubernetes实现对GPU等硬件加速设备管理的支持
需求:
只要在Pod的YAML里面声明某容器需要的GPU个数,那么Kubernetes为我创建的容器里就应该出现对应的GPU设备以及它对应的驱动目录

原理:
当用户的容器被创建之后这个容器里必须出现如下两部分设备和目录
1. GPU设备路径,比如 /dev/nvidia0
2. GPU驱动目录,比如 /usr/local/nvidia/*
GPU设备路径正是该容器启动时的Devices参数; 而驱动目录则是该容器启动时的Volume参数
在k8s的GPU支持的实现里,kubelet实际上就是将上述两部分内容设置在了创建该容器的CRI(Container Runtime Interface)参数
这样等到该容器启动之后,对应的容器里就会出现GPU设备和驱动的路径了
扩展资源类型字段(Extended Resource)
Kubernetes在Pod的API对象里没有为GPU专门设置资源类型字段,而是使用了一种叫作Extended Resource的特殊字段来负责传递GPU的信息
而在kube-scheduler里面并不关心这个字段的具体含义,只会在计算的时候,一律将调度器里保存的该类型资源的可用量,直接减去Pod声明的数值即可
Extended Resource其实是Kubernetes为用户设置的一种对自定义资源的支持
调度器如何获取各种自定义资源在每台宿主机上的可用量,宿主机节点本身就必须向APIserver汇报该资源的可用类型.在K8S中各种类型的资源可用量其实就是Node的Status
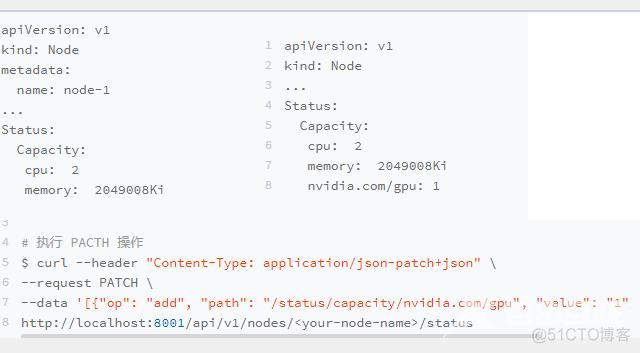
nvidia.com/gpu类型的资源的数量是1
Device Plugin插件
在Kubernetes的GPU支持方案里用户并不需要真正去手动做上述关于Extended Resource.在Kubernetes中对所有硬件加速设备进行管理的功能,都是由一种叫作Device Plugin的插件来负责的.这其中,当然也就包括了对该硬件的Extended Resource进行汇报的逻辑
对于每一种硬件设备都需要有它所对应的Device Plugin进行管理,这些Device Plugin都通过gRPC的方式和本节点上的kubelet连接起来
nvidia.com/gpu=3.用户在这里是不需要关心GPU信息向上的汇报流程
需要注意的是ListAndWatch向上汇报的信息,只有本机上GPU的ID列表而不会有任何关于GPU设备本身的信息.而且kubelet在向API Server汇报的时候,只会汇报该GPU对应的Extended Resource的数量.当然,kubelet本身会将这个GPU的ID列表保存在自己的内存里,并通过ListAndWatch API定时更新
nvidia.com/gpu:1.那么接下来Kubernetes的调度器就会从它的缓存里寻找GPU数量满足条件的Node,然后将缓存里的GPU数量减1,完成Pod与Node的绑定
调度成功后的Pod信息就会被对应的kubelet拿来进行容器操作.当kubelet发现这个Pod的容器请求一个GPU的时候.
kubelet就会从自己持有的GPU列表里,为这个容器分配一个GPU.此时,kubelet就会向本机的Device Plugin发起一个Allocate() 请求.这个请求携带的参数,正是即将分配给该容器的设备ID,也就是GPU列表中的某个元素
当Device Plugin收到Allocate请求之后,它就会根据kubelet传递过来的设备ID,从Device Plugin里找到这些设备对应的设备路径和驱动目录.这些信息,正是Device Plugin周期性的从本机查询到的.比如,在NVIDIA Device Plugin的实现里,它会定期访问nvidia-docker插件,从而获取到本机的GPU信息
而被分配GPU对应的设备路径和驱动目录信息被返回给kubelet之后,kubelet 就完成了为一个容器分配GPU的操作.接下来kubelet会把这些信息追加在创建该容器所对应的CRI请求当中.当这个CRI请求发给 Docker,Docker创建出来的容器里就会出现这个GPU设备并把它所需要的驱动目录挂载进去
对于其他类型硬件来说要想在k8s所管理的容器里使用这些硬件的话,也需要遵循上述DevicePlugin的流程来实现的Allocate和ListAndWatch API
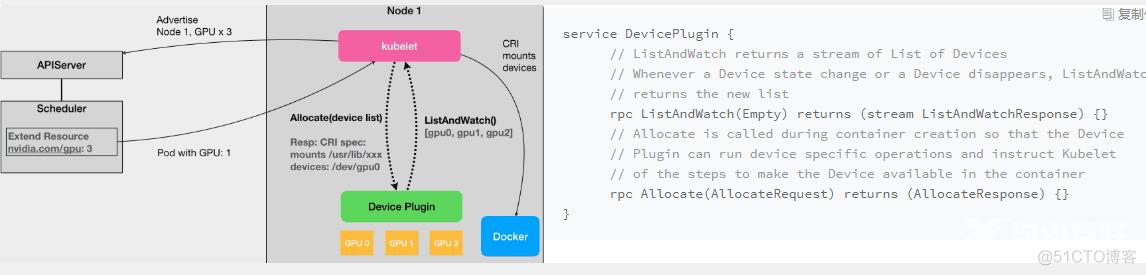
流程总结:
1.kubelet通过对应的Device Plugin收集本机的数据仅仅是设备ID列表信息,然后上报给API Server. kubelet上报给API Server的数据仅仅是一个设备的总数 这个设备名称和总数信息会缓存到Node的status列中
2.在pod中指定需要的设备名称和数量后 调度器会把Pod和Node进行绑定 同时减少对应Node中status列设备对应的数量(status.设备数-pod.设备数)
3.在Node上的kubelet会根据pod要求的设备数 在自己的缓存中弹出对应数量的设备ID号
4.根据这些设备ID号 kubelet再次向Device Plugin发起一个Allocate() 请求 这些设备ID做为请求参数进行发送
5.Device Plugin根据具体的设备ID号就能找到这些设备对应的设备路径和驱动目录 然后把这些信息返回给kubelet
6.kubelet在启动容器的时候把从Device Plugin获取到的设备路径和驱动目录做为CNI参数 传递给docker run命令,容器启动后就会出现相关设备
Device Plugin缺点
GPU等硬件设备的调度,实际上是由kubelet完成的.kubelet会负责从它所持有的硬件设备列表中,为容器挑选一个硬件设备,然后调用Device Plugin的Allocate API来完成这个分配操作. 在整条链路中,调度器扮演的角色仅仅是为Pod寻找到可用的支持这种硬件设备的节点而已.
这就使得Kubernetes 里对硬件设备的管理,只能处理“设备个数”这唯一一种情况 (只能找到节点级别)
一旦设备是异构的不能简单地用“数目”去描述具体使用需求的时候.如:我的Pod想要运行在计算能力最强的那个GPU上Device Plugin就完全不能处理了
在很多场景下我们希望在调度器进行调度的时候,就可以根据整个集群里的某种硬件设备的全局分布,做出一个最佳的调度选择 这种目前是无法实现的
【文章转自:新加坡服务器 http://www.558idc.com/sin.html 复制请保留原URL】