SLAM包含了两个主要的任务:定位与构图,在移动机器人或者自动驾驶中,这是一个十分重要的问题:机器人要精确的移动,就必须要有一个环境的地图,那么要构建环境的地图就需要知道机器人的位置。
本系列文章主要分成四个部分:
在第一部分中,将介绍Lidar SLAM,包括Lidar传感器,开源Lidar SLAM系统,Lidar中的深度学习以及挑战和未来。
第二部分重点介绍了Visual SLAM,包括相机传感器,不同稠密SLAM的开源视觉SLAM系统。
第三部分介绍视觉惯性里程法SLAM,视觉SLAM中的深度学习以及未来。
第四部分中,将介绍激光雷达与视觉的融合。
视觉SLAM的稳定性是一项技术挑战。因为基于单目的视觉SLAM需要初始化、尺度的不确定性和尺度漂移等问题[1]。尽管立体相机和RGB-D相机可以解决初始化和缩放的问题,但也存在一些不容忽视的问题,如运动速度快、视角小、计算量大、遮挡、特征丢失、动态场景和光照变换等。针对以上这些问题传感器的融合方案逐渐流行起来,IMU与相机融合的视觉里程计成为研究热点。
视觉与惯导
论文[2][3][4]是比较早期对VIO进行的一些研究。[5][6]给出了视觉惯导里程计的数学证明。而论文[7]则使用捆集约束算法对VIO进行稳健初始化。特别是tango[8]、Dyson 360 Eye和hololens[9]可以算的上是VIO真正的产品,得到了很好的反馈。除此之外,苹果的ARkit(filterbase)、谷歌的ARcore(filterbase)、uSens的Insideout都是VIO技术。下面就介绍一些开源VIO系统[10]:

•SSF:(松耦合,基于滤波的方法)是基于EKF的时延补偿的单传感器和多传感器融合框架[11]。
•MSCKF:(紧耦合,基于滤波的方法)为Google Tango所采用,基于扩展Kalman滤波器[12]。类似的工作有MSCKF-VIO[13],并且代码开源了。

•ROVIO:(紧耦合,基于滤波器的方法)是一种基于扩展卡尔曼滤波器VIO方法,可跟踪3D特征和图像块特征[14]。
•OKVIS:(紧耦合,基于优化的方法)是一个经典的基于关键帧的视觉惯性SLAM[15]开源方案。支持单目和立体相机的滑动窗口估计器。
•VINS:VINS Mono(紧密耦合,基于优化的方法),论文[16]是单目视觉惯导的实时SLAM框架。开源代码运行在Linux上,并集成了ROS。
VINS Mobile[17][18]是一款运行在兼容iOS设备上的实时单目视觉惯性里程计。此外,VINS Fusion支持多种视觉惯性传感器类型(GPS、单摄像头+IMU、立体声摄像头+IMU,甚至仅立体摄像头)。它具有位置校准、时间对齐和闭环检测等模块。

ICE-BA:(紧耦合,基于优化的方法)为视觉惯性SLAM提供了具有增量性、一致性且有效的捆集调整算法,在滑动窗口算法的基础上进行局部BA,在所有关键帧上并行全局BA,并实时输出每个帧的相机姿态和更新的地图点[19]。
Maplab: :(紧密耦合,基于优化的方法)是一个开放的、面向研究的视觉惯性SLAM框架,用C++编写,支持创建和处理多种SLAM方案。一方面,maplab可以看作是一个现成的视觉惯性构图和定位系统。另一方面,maplab为研究社区提供了一系列多窗口的SLAM工具,包括地图合并、视觉惯性批处理优化、环路闭合、三维密集重建[20]。
当然还有其他解决方案,比如基于ORB-SLAM的VI-ORB[21],这是一种基于优化的紧耦合方案,StructVIO[22]该方案能够更好的应对AR应用中相机的快速运动和旋转。其他的基于事件相机的VIO等系统这里就不再一一列举。

深度学习与视觉SLAM
目前,深度学习在计算机视觉方面起着至关重要的作用。随着视觉SLAM的发展,越来越多的研究者开始关注基于深度学习的SLAM的研究。其中比较典型的就是语义SLAM,“语义SLAM”是指将语义信息包含到SLAM系统中,通过提供高层次的理解、鲁棒的性能、环境的感知和任务驱动感知来提高SLAM过程的性能和表示。接下来,我们将从以下几个方面介绍具有语义信息的SLAM的方案:
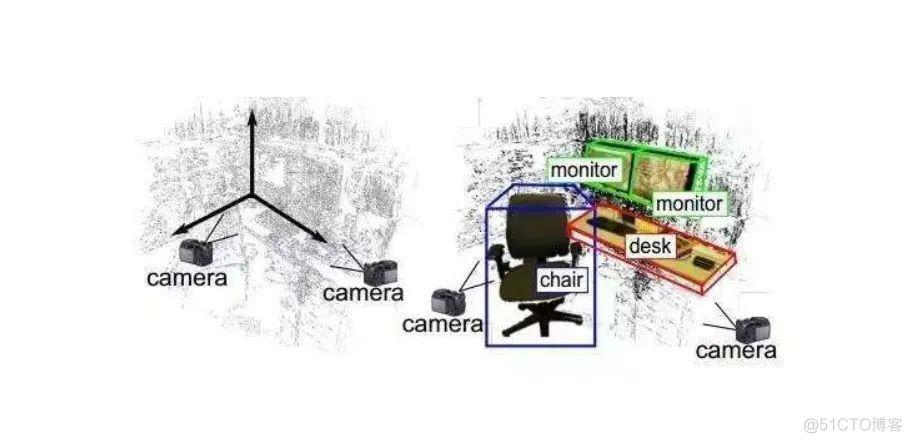
特征与检测:
基于单目视觉的 Pop-up SLAM [23]提出了实时单目平面SLAM,以证明 在低纹理环境下,语义理解可以提高状态估计和稠密重建的精度。
论文[24]得到由卷积网络(convnet)预测的语义关键点。
LIFT[25]可以得到比SIFT更密集的特征点。
DeepSLAM[26]在存在图像噪声的情况下进行特征点检测,相比较传统方案,具有显著的性能差距。
SuperPoint[27]提出了一个自监督框架,适用于计算机视觉中大量多视图几何问题的兴趣点检测器和描述符的训练。
GCN-SLAM[28]提出了一种基于深度学习的GCNv2网络,用于生成关键点和描述符。
论文[29]提出了融合3D形状、位置和语义标签的信息SLAM方案。
cube SLAM(Monocular)是一个基于立方体模型的三维目标检测与SLAM系统[30]。它实现了目标级的场景构建、定位和动态目标跟踪。基于鱼眼相机的SLAM方法介绍
论文[31]将cubeSLAM和Pop-up SLAM相结合,使地图比基于特征点的SLAM更稠密且准确的语义信息。公众号历史文章有介绍。

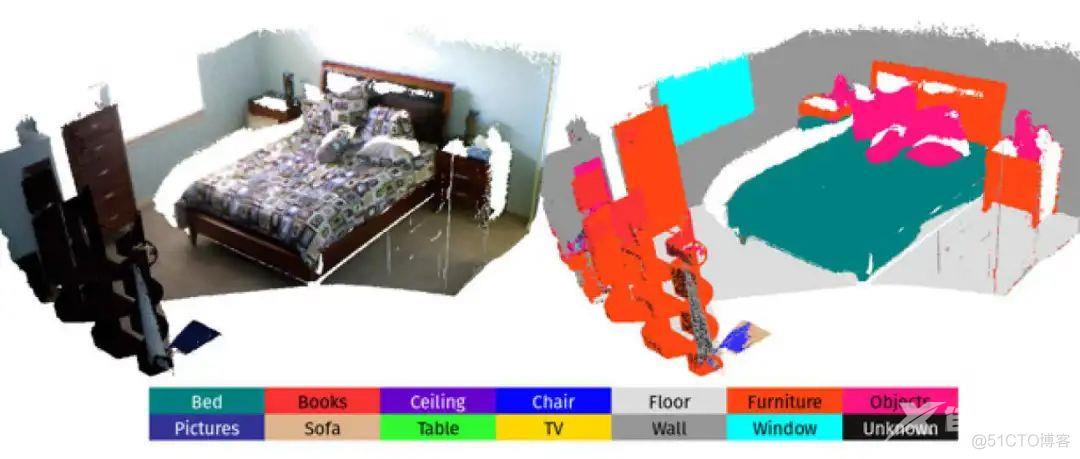
识别与分割:
SLAM++[32]展示了一种新的面向对象的3D SLAM方案的主要优点,它充分利用了先验知识的循环,即许多重复的场景、特定对象和结构构成。
论文[33]提出了结合了最先进的深度学习方法和基于单目摄像机视频流的LSD-SLAM,通过具有空间一致性的连接关键帧之间的对应关系,将二维语义信息转化为三维点云地图信息。
Semanticfusion[34]方法提出了将CNN和最先进的稠密SLAM融合方案,
ElasticFusion[35]是用来构建语义三维地图。
MarrNet提出了一个端到端的可训练框架,依次估计2.5D框架和3D对象形状。
3DMV(RGB D)[36]结合RGB颜色和几何信息对RGB-D信息进行三维语义分割。
Pix3D[37]从单个图像研究三维形状建模。
scan complete[38]是一种数据驱动的方法,它以场景的不完全三维扫描作为输入,并预测一个完整的三维模型以及每个体素的语义标签。
Fusion++[39]是一个在线的对象级SLAM系统,它可以构建任意重构对象精确的三维点云地图。
SegMap[40]是一种基于分割方法的用于机器人定位、环境重建和语义提取的SLAM系统。
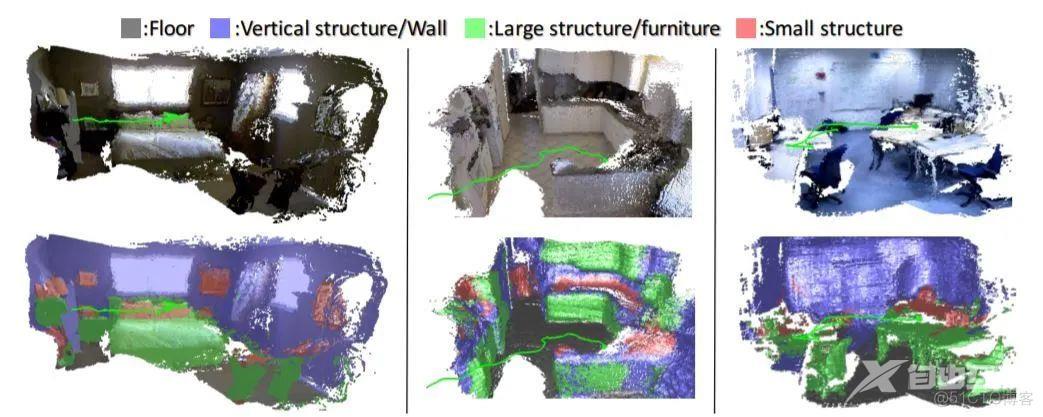
尺度恢复:
CNN-SLAM[41]是基于单目相机通过深度学习估计深度的工作,DeepVO[42]和GS3D[43以及UnDeepVO[44]是利用具有深度学习方法在单目相机中获得6自由度的姿态和深度。
GeoNet[45]是一个联合的无监督学习框架,用于从视频中估计单目深度、光流以及自身的运动。CodeSLAM[46]提出了一种基于单个图像的深度图,该深度图可以与姿态变量联合进行高效的优化。
Mono-stixels[47]利用动态场景中的深度、运动和语义信息来估计深度。
GANVO[48]使用一个无监督的学习框架,从未标记的图像中提取6-DoF姿态和单目深度图,使用深度卷积生成对抗网络。
GEN-SLAM[49]借助于传统的几何SLAM和单目的拓扑约束输出稠密点云地图。
动态SLAM
RDSLAM[50]是一种基于关键帧的在线表示和更新方法的实时单目SLAM系统。
DS-SLAM[51]是一个基于优化ORB-SLAM的语义信息SLAM系统。语义信息可以使SLAM系统在动态环境下具有更强的鲁棒性。
MaskFusion是一个基于Mask R-CNN的实时、对象感知、语义和动态RGB-D SLAM系统。该系统即使在连续的、自运动中,也能用语义信息对物体进行标注。
Detect SLAM[52]将SLAM与基于深度神经网络的目标检测器结合起来,使这两个功能在未知和动态环境中相互辅助。
DynaSLAM[53]是一个支持单目、立体和RGB-D相机在动态环境下辅助静态地图的SLAM系统。StaticFusion[54]提出了一种在动态环境中检测运动目标并同时重建背景结构的鲁棒密集RGB-D SLAM方法。
视觉SLAM的挑战与未来
鲁棒性和可移植性
视觉SLAM在光照变化、高动态环境、快速运动、剧烈旋转和低纹理环境等仍然面临着很大的挑战。首先,全局快门代替滚动快门是实现精准的相机姿态估计的基础。像动态视觉传感器这样的事件摄像机能够每秒产生100万个事件,足以在高速和高动态范围内进行非常快速的运动。其次,利用边缘、平面、曲面等语义特征,甚至减少特征依赖性,如用相邻边线的跟踪、直接跟踪或机器学习相结合,都可能成为更好的选择。第三,基于SfM/SLAM的数学原理,精确的数学公式优于隐式深度学习。SLAM的未来可以预见,一种是基于智能手机或无人机(UAV)等嵌入式平台的SLAM,另一种是更加详细的场景或者物体的三维重建、场景理解和深度学习。如何平衡实时性和准确性是一个至关重要的开放性问题。与动态、非结构化、复杂、不确定和大规模环境相关的解决方案还有待探索[55]。
多传感器融合
实际的机器人和硬件设备通常携带了不止一种传感器,而往往是多个传感器的融合。例如,目前对手机VIO的研究将视觉信息和IMU信息结合起来,实现了两种传感器的优势互补,为SLAM的小型化和低成本提供了非常有效的解决方案。DeLS-3D[56]设计是一种融合摄像机视频、运动传感器(GPS/IMU)和三维语义地图的传感器融合方案,以实现系统的鲁棒性和效率。传感器列表如下,但不限于激光雷达、声纳、IMU、红外、摄像机、GPS、雷达等。传感器的选择取决于环境和所需的地图类型。
语义SLAM
事实上,人类识别物体的运动是基于感知而不是图像中的特征。SLAM中的深度学习可以实现目标的识别和分割,帮助SLAM系统更好地感知周围环境。语义SLAM也有利于全局优化、闭环检测和重定位。[57]这篇文章指出:传统的SLAM方法依赖于点、线(PL-SLAM,StructSLAM)和平面等几何特征来推断环境结构。而语义SLAM可以实现大规模场景中的高精度实时定位,它教会机器人可以像人类一样的感知环境。
参考文献
【1】Hauke Strasdat, J Montiel, and Andrew J Davison. Scale drift-aware large scale monocular slam. Robotics: Science and Systems VI, 2(3):7, 2010.
【2】 Stefan Leutenegger, Simon Lynen, Michael Bosse, Roland Siegwart, and Paul Furgale. Keyframe-based visual–inertial odometry using nonlinear optimization. The International Journal of Robotics Research, 34(3):314–334, 2015.
【3】 Guoquan Huang, Michael Kaess, and John J Leonard. Towards consistent visual-inertial navigation. In 2014 IEEE International Conference on Robotics and Automation (ICRA), pages 4926–4933. IEEE, 2014.
【4】 Mingyang Li and Anastasios I Mourikis. High-precision, consistent ekf-based visual-inertial odometry. The International Journal of Robotics Research, 32(6):690–711, 2013.
【5】Ra´ul Mur-Artal and Juan D Tard ´os. Visual-inertial monocular slam with map reuse. IEEE Robotics and Automation Letters, 2(2):796– 803, 2017.
【6】 Christian Forster, Luca Carlone, Frank Dellaert, and Davide Scaramuzza. On-manifold preintegration for real-time visual–inertial odometry. IEEE Transactions on Robotics, 33(1):1–21, 2016.
【7】Carlos Campos, J. M. M. Montiel, and Juan D. Tard ´os. Fast and robust initialization for visual-inertial slam. 2019 International Conference on Robotics and Automation (ICRA), pages 1288–1294, 2019.
【8】Mark Froehlich, Salman Azhar, and Matthew Vanture. An investigation of google tango R tablet for low cost 3d scanning. In ISARC. Proceedings of the International Symposium on Automation and Robotics in Construction, volume 34. Vilnius Gediminas Technical University, Department of Construction Economics , 2017.
【9】 Mathieu Garon, Pierre-Olivier Boulet, Jean-Philippe Doironz, Luc Beaulieu, and Jean-Franc¸ois Lalonde. Real-time high resolution 3d data on the hololens. In 2016 IEEE International Symposium on Mixed and Augmented Reality (ISMAR-Adjunct), pages 189–191. IEEE, 2016.
【10】Jeffrey Delmerico and Davide Scaramuzza. A benchmark comparison of monocular visual-inertial odometry algorithms for flying robots. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 2502–2509. IEEE, 2018.
【11】Stephan M Weiss. Vision based navigation for micro helicopters. PhD thesis, ETH Zurich, 2012.
[12] Anastasios I Mourikis and Stergios I Roumeliotis. A multi-state constraint kalman filter for vision-aided inertial navigation. In Proceedings 2007 IEEE International Conference on Robotics and Automation, pages 3565–3572. IEEE, 2007.
[13] Ke Sun, Kartik Mohta, Bernd Pfrommer, Michael Watterson, Sikang Liu, Yash Mulgaonkar, Camillo J Taylor, and Vijay Kumar. Robust stereo visual inertial odometry for fast autonomous flight. IEEE Robotics and Automation Letters, 3(2):965–972, 2018.
[14] Michael Bloesch, Sammy Omari, Marco Hutter, and Roland Siegwart. Robust visual inertial odometry using a direct ekf-based approach. In 2015 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 298–304. IEEE, 2015.
[15] Peiliang Li, Tong Qin, Botao Hu, Fengyuan Zhu, and Shaojie Shen. Monocular visual-inertial state estimation for mobile augmented reality. In 2017 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), pages 11–21. IEEE, 2017.
[16] Tong Qin and Shaojie Shen. Online temporal calibration for monocular visual-inertial systems. In 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3662–3669. IEEE, 2018.
[17] Tong Qin and Shaojie Shen. Robust initialization of monocular visualinertial estimation on aerial robots. In 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4225– 4232. IEEE, 2017.
[18] Zhenfei Yang and Shaojie Shen. Monocular visual–inertial state estimation with online initialization and camera–imu extrinsic calibration. IEEE Transactions on Automation Science and Engineering, 14(1):39– 51, 2016.
【19】Haomin Liu, Mingyu Chen, Guofeng Zhang, Hujun Bao, and Yingze Bao. Ice-ba: Incremental, consistent and efficient bundle adjustment for visual-inertial slam. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1974–1982, 2018.
【20】T. Schneider, M. T. Dymczyk, M. Fehr, K. Egger, S. Lynen, I. Gilitschenski, and R. Siegwart. maplab: An open framework for research in visual-inertial mapping and localization. IEEE Robotics and Automation Letters, 2018.
[21] Ra´ul Mur-Artal and Juan D Tard ´os. Visual-inertial monocular slam with map reuse. IEEE Robotics and Automation Letters, 2(2):796– 803, 2017.
[22]Danping Zou, Yuanxin Wu, Ling Pei, Haibin Ling, and Wenxian Yu. Structvio: Visual-inertial odometry with structural regularity of manmade environments. IEEE Transactions on Robotics, 2019.
【23】] Shichao Yang, Yu Song, Michael Kaess, and Sebastian Scherer. Popup slam: Semantic monocular plane slam for low-texture environments. In 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1222–1229. IEEE, 2016.
【24】 Georgios Pavlakos, Xiaowei Zhou, Aaron Chan, Konstantinos G Derpanis, and Kostas Daniilidis. 6-dof object pose from semantic keypoints. In 2017 IEEE International Conference on Robotics and Automation (ICRA), pages 2011–2018. IEEE, 2017.
[25] Kwang Moo Yi, Eduard Trulls, Vincent Lepetit, and Pascal Fua. Lift: Learned invariant feature transform. In European Conference on Computer Vision, pages 467–483. Springer, 2016.
【26】Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Toward geometric deep slam. arXiv preprint arXiv:1707.07410, 2017.
[27] Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 224–236, 2018.
【28】Jiexiong Tang, Ludvig Ericson, John Folkesson, and Patric Jensfelt. Gcnv2: Efficient correspondence prediction for real-time slam. arXiv preprint arXiv:1902.11046, 2019.
[29] Margarita Grinvald, Fadri Furrer, Tonci Novkovic, Jen Jen Chung, Cesar Cadena, Roland Siegwart, and Juan Nieto. Volumetric instanceaware semantic mapping and 3d object discovery. arXiv preprint arXiv:1903.00268, 2019.
【30】Shichao Yang and Sebastian Scherer. Cubeslam: Monocular 3-d object slam. IEEE Transactions on Robotics, 2019.
[31] Shichao Yang and Sebastian Scherer. Monocular object and plane slam in structured environments. IEEE Robotics and Automation Letters, 4(4):3145–3152, 2019.
【32】Renato F. Salas-Moreno, Richard A. Newcombe, Hauke Strasdat, Paul H. J. Kelly, and Andrew J. Davison. Slam++: Simultaneous localisation and mapping at the level of objects. In Computer Vision & Pattern Recognition, 2013.
[33] Xuanpeng Li and Rachid Belaroussi. Semi-dense 3d semantic mapping from monocular slam. 2016
【34】John McCormac, Ankur Handa, Andrew Davison, and Stefan Leutenegger. Semanticfusion: Dense 3d semantic mapping with convolutional neural networks. In 2017 IEEE International Conference on Robotics and automation (ICRA), pages 4628–4635. IEEE, 2017.
【35】Thomas Whelan, Renato F Salas-Moreno, Ben Glocker, Andrew J Davison, and Stefan Leutenegger. Elasticfusion: Real-time dense slam and light source estimation. The International Journal of Robotics Research, 35(14):1697–1716, 2016
【36】Jiajun Wu, Yifan Wang, Tianfan Xue, Xingyuan Sun, Bill Freeman, and Josh Tenenbaum. Marrnet: 3d shape reconstruction via 2.5 d sketches. In Advances in neural information processing systems, pages 540–550, 2017.
【37】Xingyuan Sun, Jiajun Wu, Xiuming Zhang, Zhoutong Zhang, Chengkai Zhang, Tianfan Xue, Joshua B Tenenbaum, and William T Freeman. Pix3d: Dataset and methods for single-image 3d shape modeling. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
【38】Angela Dai, Daniel Ritchie, Martin Bokeloh, Scott Reed, J ¨urgen Sturm, and Matthias Nießner. Scancomplete: Large-scale scene completion and semantic segmentation for 3d scans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4578– 4587, 2018.
[39] John McCormac, Ronald Clark, Michael Bloesch, Andrew J. Davison, and Stefan Leutenegger. Fusion++: Volumetric object-level slam. 2018 International Conference on 3D Vision (3DV), pages 32–41, 2018.
[40] Renaud Dub´e, Andrei Cramariuc, Daniel Dugas, Juan Nieto, Roland Siegwart, and Cesar Cadena. Segmap: 3d segment mapping using datadriven descriptors. arXiv preprint arXiv:1804.09557, 2018.
【41】Keisuke Tateno, Federico Tombari, Iro Laina, and Nassir Navab. Cnnslam: Real-time dense monocular slam with learned depth prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6243–6252, 2017.
【42】Vikram Mohanty, Shubh Agrawal, Shaswat Datta, Arna Ghosh, Vishnu Dutt Sharma, and Debashish Chakravarty. Deepvo: A deep learning approach for monocular visual odometry. arXiv preprint arXiv:1611.06069, 2016.
[43] Buyu Li, Wanli Ouyang, Lu Sheng, Xingyu Zeng, and Xiaogang Wang. Gs3d: An efficient 3d object detection framework for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1019–1028, 2019.
[44] Ruihao Li, Sen Wang, Zhiqiang Long, and Dongbing Gu. Undeepvo: Monocular visual odometry through unsupervised deep learning. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 7286–7291. IEEE, 2018.
【45】 Zhichao Yin and Jianping Shi. Geonet: Unsupervised learning of dense depth, optical flow and camera pose. In CVPR, 2018.
[46] Michael Bloesch, Jan Czarnowski, Ronald Clark, Stefan Leutenegger, and Andrew J Davison. Codeslamlearning a compact, optimisable representation for dense visual slam. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2560– 2568, 2018.
[47] Fabian Brickwedde, Steffen Abraham, and Rudolf Mester. Monostixels: monocular depth reconstruction of dynamic street scenes. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 1–7. IEEE, 2018.
[48] Yasin Almalioglu, Muhamad Risqi U. Saputra, Pedro Porto Buarque de Gusm˜ao, Andrew Markham, and Agathoniki Trigoni. Ganvo: Unsupervised deep monocular visual odometry and depth estimation with generative adversarial networks. 2019 International Conference on Robotics and Automation (ICRA), pages 5474–5480, 2018.
[49] Punarjay Chakravarty, Praveen Narayanan, and Tom Roussel. Genslam: Generative modeling for monocular simultaneous localization and mapping. arXiv preprint arXiv:1902.02086, 2019
【50】Wei Tan, Haomin Liu, Zilong Dong, Guofeng Zhang, and Hujun Bao. Robust monocular slam in dynamic environments. In 2013 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), pages 209–218. IEEE, 2013.
[51] Chao Yu, Zuxin Liu, Xin-Jun Liu, Fugui Xie, Yi Yang, Qi Wei, and Qiao Fei. Ds-slam: A semantic visual slam towards dynamic environments. In 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1168–1174. IEEE, 2018.
【52】Fangwei Zhong, Wang Sheng, Ziqi Zhang, China Chen, and Yizhou Wang. Detect-slam: Making object detection and slam mutually beneficial. In IEEE Winter Conference on Applications of Computer Vision, 2018.
[53] Berta Bescos, Jos´e M F´acil, Javier Civera, and Jos´e Neira. Dynaslam: Tracking, mapping, and inpainting in dynamic scenes. IEEE Robotics and Automation Letters, 3(4):4076–4083, 2018.
[54] Raluca Scona, Mariano Jaimez, Yvan R Petillot, Maurice Fallon, and Daniel Cremers. Staticfusion: Background reconstruction for dense rgb-d slam in dynamic environments. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 1–9. IEEE, 2018
【55】Muhammad Sualeh and Gon-Woo Kim. Simultaneous localization and mapping in the epoch of semantics: A survey. International Journal of Control, Automation and Systems, 17(3):729–742, 2019.
【56】Peng Wang, Ruigang Yang, Binbin Cao, Wei Xu, and Yuanqing Lin. Dels-3d: Deep localization and segmentation with a 3d semantic map. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5860–5869, 2018.
【57】Nikolay Atanasov, Sean L Bowman, Kostas Daniilidis, and George J Pappas. A unifying view of geometry, semantics, and data association in slam. In IJCAI, pages 5204–5208, 2018.
本文仅做学术分享,如有侵权,请联系删文。
