 什么接口文档都不用手写了?自动挡?
目录
什么接口文档都不用手写了?自动挡?
目录- DRF 自动生成接口文档
- 接口文档如何去写?
- 自动生成接口文档
- 设置接口文档路径
- 文档描述说明的定义位置
- 配置文件
- 访问接口文档网页
- 两点说明:
- 如何写好接口文档
- HTTP携带信息的方式
- 分离通用信息
- 路径中的参数表达式
- 数据模型定义
- 请求示例
- 异常处理
- 如何组织?
- 一个创建用户的例子:创建用户
- 这样组织的原因
- 文档提供的形式
我们知道前后端分离,前端一般按后端写好的接口去开发,那么就需要我们明细后端接口数据等,需要写接口文档,前端按照接口文档去开发
接口文档如何去写?-
使用word或者md文档编写,自己纯手写
-
第三方平台录入数据,固定的位置填固定的东西
1. EOLINKER(推荐)可以协作,界面简洁 地址:https://www.eolinker.com/#/?status=link-jump 2.RAP(前阿里妈妈团队)支持版本管理,开源,有文档 地址:http://rap2.taobao.org/ 3.EasyAPI (相对来说easy) 地址:https://www.easyapi.com/ 4.apizza 地址:https://apizza.net/pro/#/ 5.showdoc 地址:https://www.showdoc.cc/ 6.胖胖羊 地址:http://doclever.cn/controller/console/console.html -
公司自己开发接口平台,搭建接口平台
-
自动生成接口文档:coreapi,swagger
自动生成接口文档REST framewrok生成接口文档需要coreapi库的支持。
安装:pip install coreapi
文档路由对应的视图配置为rest_framework.documentation.include_docs_urls
参数title为接口文档网站的标题
from rest_framework.documentation import include_docs_urls
urlpatterns = [
...
path('docs/', include_docs_urls(title='站点页面标题'))
]
1) 单一方法的视图,可直接使用类视图的文档字符串,如
class BookListView(generics.ListAPIView):
"""
返回所有图书信息.
"""
2)包含多个方法的视图,在类视图的文档字符串中,分开方法定义,如
class BookListCreateView(generics.ListCreateAPIView):
"""
get:
返回所有图书信息.
post:
新建图书.
"""
3)对于视图集ViewSet,仍在类视图的文档字符串中分开定义,但是应使用action名称区分,如
class BookInfoViewSet(mixins.ListModelMixin, mixins.RetrieveModelMixin, GenericViewSet):
"""
list:
返回图书列表数据
retrieve:
返回图书详情数据
latest:
返回最新的图书数据
read:
修改图书的阅读量
"""
写视图类,只需要加注释即可
配置文件REST_FRAMEWORK = {
'DEFAULT_SCHEMA_CLASS': 'rest_framework.schemas.coreapi.AutoSchema',
# 新版drf schema_class默认用的是rest_framework.schemas.openapi.AutoSchema
}
# 不配置报错:#AttributeError: 'AutoSchema' object has no attribute 'get_link'
浏览器访问 127.0.0.1:8000/docs/,即可看到自动生成的接口文档。
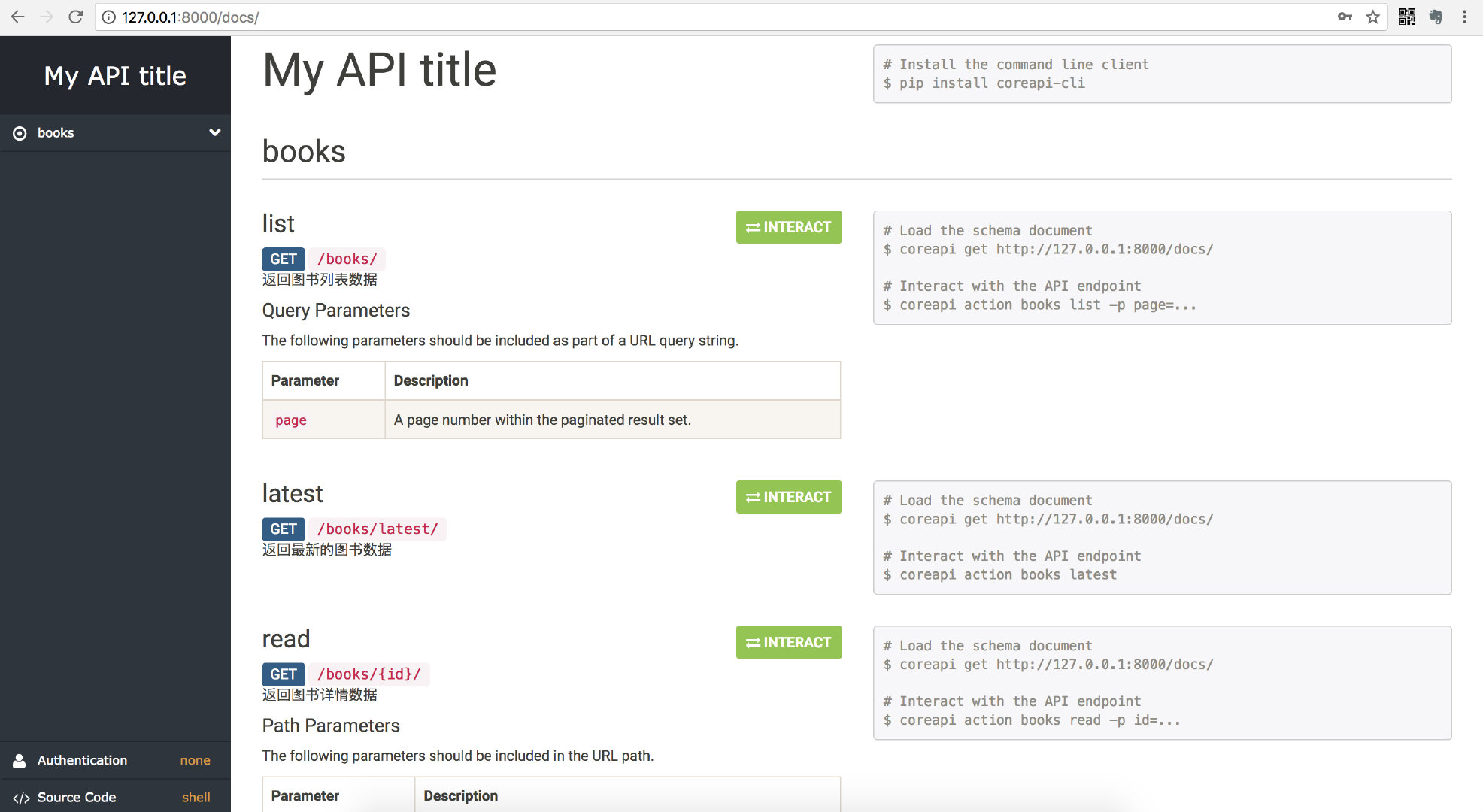
1) 视图集ViewSet中的retrieve名称,在接口文档网站中叫做read
2)参数的Description需要在模型类或序列化器类的字段中以help_text选项定义,如:
class Student(models.Model):
...
age = models.IntegerField(default=0, verbose_name='年龄', help_text='年龄')
...
或
class StudentSerializer(serializers.ModelSerializer):
class Meta:
model = Student
fields = "__all__"
extra_kwargs = {
'age': {
'required': True,
'help_text': '年龄'
}
}
- url
- headers
- body: 包括请求体,响应体
一般来说,headers里的信息都是通用的,可以提前说明,作为默认参数
路径中的参数表达式URL中参数表达式使用mustache的形式,参数包裹在双大括号之中``
例如:
/api/user//api/user/?age=&gender=
数据模型定义包括:
- 路径与查询字符串参数模型
- 请求体参数模型
- 响应体参数模型
数据模型的最小数据集:
- 名称
- 是否必须
- 说明
“最小数据集”(MDS)是指通过收集最少的数据,较好地掌握一个研究对象所具有的特点或一件事情、一份工作所处的状态,其核心是针对被观察的对象建立起一套精简实用的数据指标。最小数据集的概念起源于美国的医疗领域。最小数据集的产生源于信息交换的需要,就好比上下级质量技术监督部门之间、企业与质量技术监督部门之间、质量技术监督部门与社会公众之间都存在着信息交换的需求。
一些文档里可能会加入字段的类型,但是我认为这是没必要的。以为HTTP传输的数据往往都需要序列化,大部分数据类型都是字符串。一些特殊的类型,例如枚举类型的字符串,可以在说明里描述。
另外:数据模型非常建议使用表格来表现。
举个栗子?:
commom表示普通用户,vip表示vip用户
age
否
用户年龄
gender
否
用户性别。1表示男,0表示女
请求示例
// general
POST http://www.testapi.com/api/user
// request payload
{
"name": "HammerZe",
"age": 18,
"like": ["music", "reading"],
"userType": "vip"
}
// response
{
"id": "asdkfjalsdkf"
}
异常处理最小数据集
- 状态码
- 说明
- 解决方案
举个栗子?:
之前我一直不想把解决方案加入异常处理的最小数据集,但是对于很多开发者来说,即使它知道424代表超过最大在线数量。如果你不告诉如果解决这个问题,那么他们可能就会直接来问你。所以最好能够一步到位,直接告诉他应该如何解决,这样省时省力。
1 请求示例
// general
POST http://www.testapi.com/api/user/vip/?token=abcdefg
// request payload
{
"name": "qianxun",
"age": 14,
"like": ["music", "reading"]
}
// response
{
"id": "asdkfjalsdkf"
}
2 路径与查询字符串参数模型
POST http://www.testapi.com/api/user//?token=
commom表示普通用户,vip表示vip用户
token
是
认证令牌
3 请求体参数模型
4 响应体参数模型
5 异常处理
请求示例: 请求示例放在第一位的原因是,要用最快的方式告诉开发者,这个接口应该如何请求路径与查询字符串参数模型: 使用mustache包裹参数请求体参数模型:如果没有请求体,可以不写响应体参数模型异常处理
文档建议由一下两种形式,在线文档,pdf文档。
- 在线文档
- 更新方便
- 易于随时阅读
- 易于查找
- PDF文档
- 内容表现始终如一,不依赖文档阅读器
- 文档只读,不会被轻易修改
其中由于是面对第三方开发者,公开的在线文档必须提供;由于某些特殊的原因,可能需要提供文件形式的文档,建议提供pdf文档。当然,以下的文档形式是非常不建议提供的:
- word文档
- markdown文档
word文档和markdown文档有以下缺点:
文档的表现形式非常依赖文档查看器:各个版本的word文档对word的表现形式差异很大,可能在你的电脑上内容表现很好的文档,到别人的电脑上就会一团乱麻;另外markdown文件也是如此。而且markdown中引入文件只能依靠图片链接,如果文档中含有图片,很可能会出现图片丢失的情况。文档无法只读:文档无法只读,就有可能会被第三方开发者在不经意间修改,那么文档就无法保证其准确性了。
总结一下,文档形式的要点:
只读性:保证文档不会被开发者轻易修改一致性:保证文档在不同设备,不同文档查看器上内容表现始终如一易于版本管理:文档即软件(DAAS: Document as a Software),一般意义上说软件 = 数据 + 算法, 但是我认为文档也是一种组成软件的重要形式。既然软件需要版本管理,文档的版本管理也是比不可少的。