在这里感谢最近一直阅读我文章的小伙伴,如果觉得文章对你有用,可以帮忙关注转载,需要的时候可以及时找到文章。
背景今年Q3季度我们在推广业务方使用Iceberg,当时为了让不同业务线的用户可以使用自己的hadoop账号权限把数据写到他们的hadoop集市目录,我们在Iceberg中添加了ugi,使Flink账号代理成业务方的hadoop账号。这次的堆内存泄漏就是因为我们使用ugi错误方式引发的。
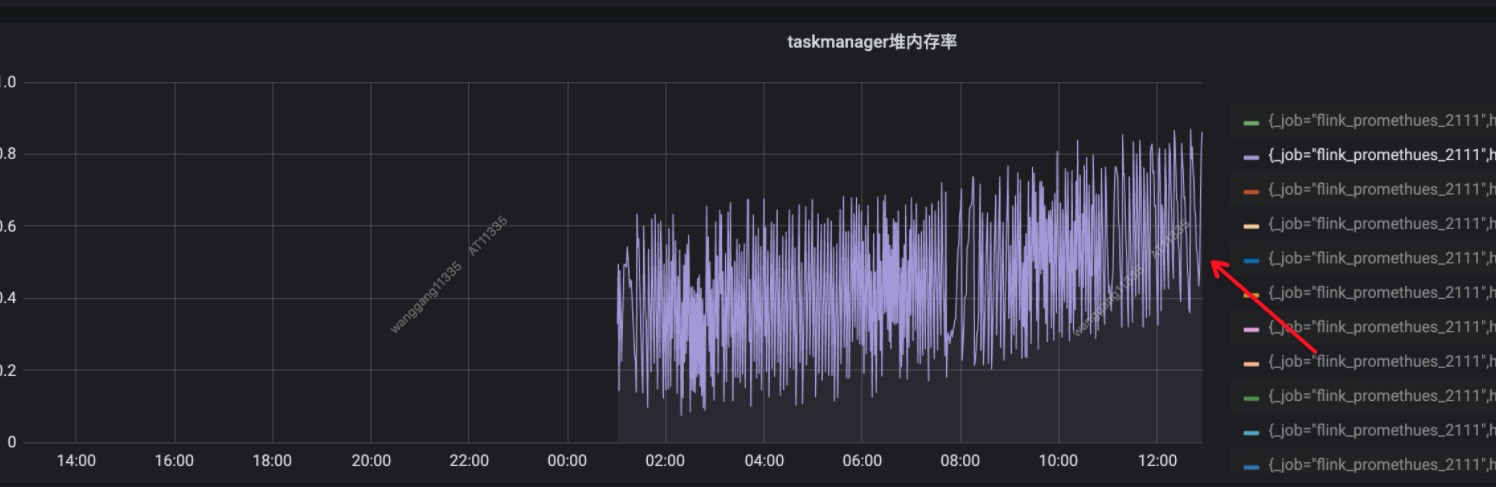
现象通过监控,我们发现用户的Flink写Iceberg任务的堆内存呈增长趋势,没多久就报堆内存oom了。
 定位过程
1.打印日志及设置oom时dump堆内存到磁盘
定位过程
1.打印日志及设置oom时dump堆内存到磁盘
clusterConf.env.java.opts=-XX:+PrintGCDetails
-XX:+PrintGCDateStamps -Xloggc:${LOG_DIRS}/gc.log -XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/${CONTAINER_ID}.dump
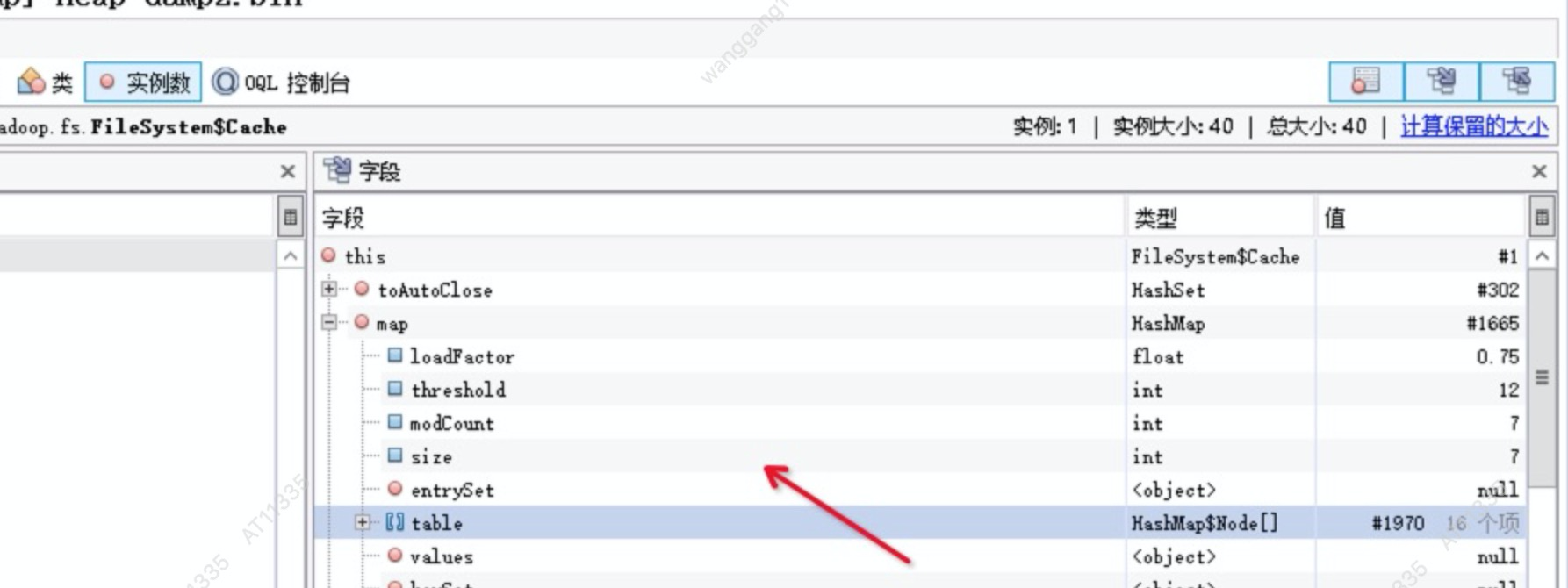
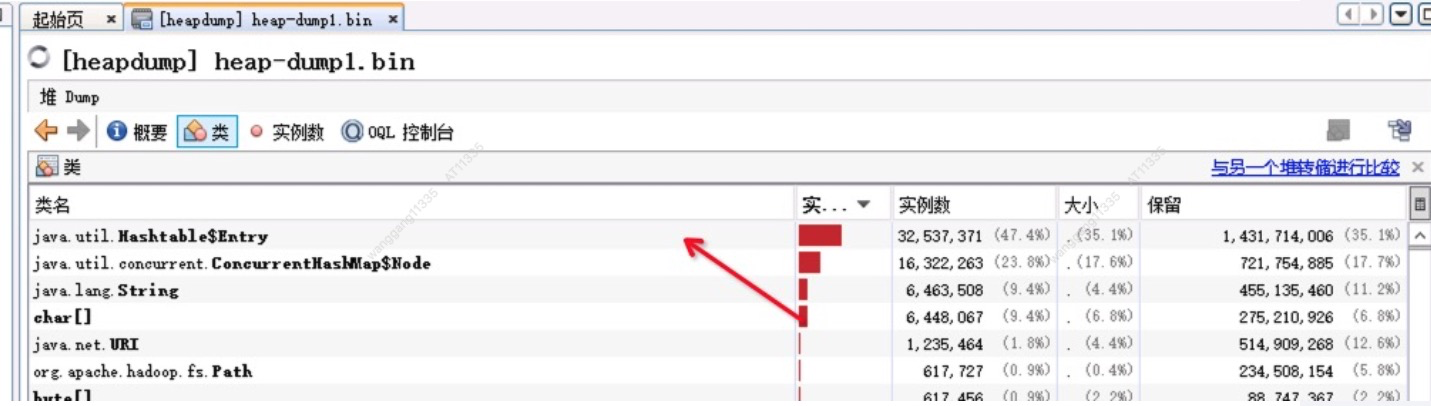
发现最多的实例竟然是Entry对象,开始去分析其引用(主要是想查找找有没有比较大的HashMap),
如下图好多引用都是DistributedFileSystem引用的DFSclient对象。
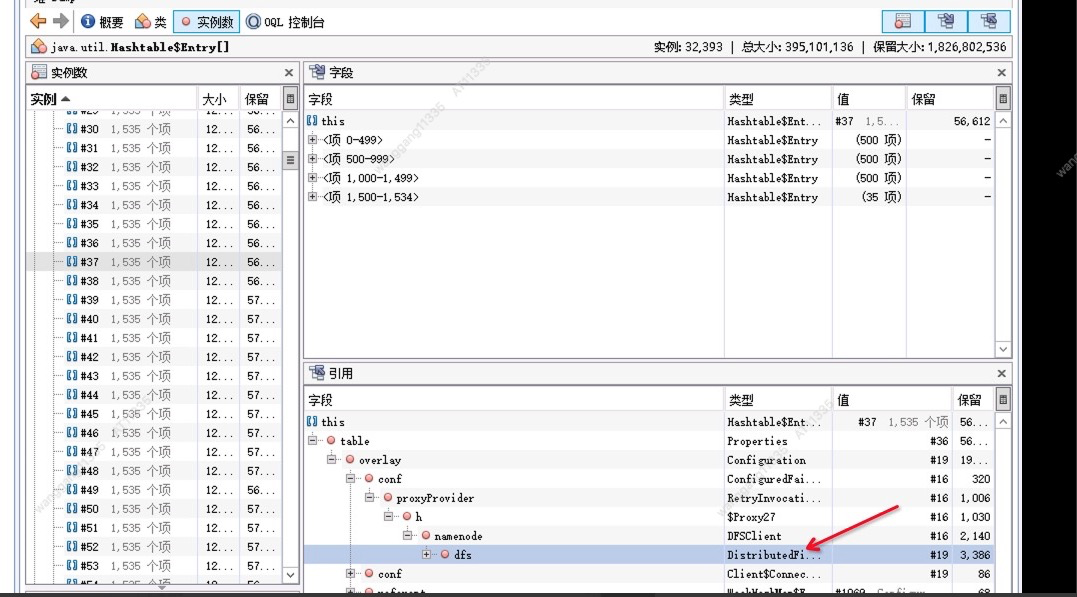
搜下DFSClient对象,发现其数量有16000多个。DFSClient对象为什么会这么多,继续往下跟发现其被缓存到DistributedFileSystem的cache里面。
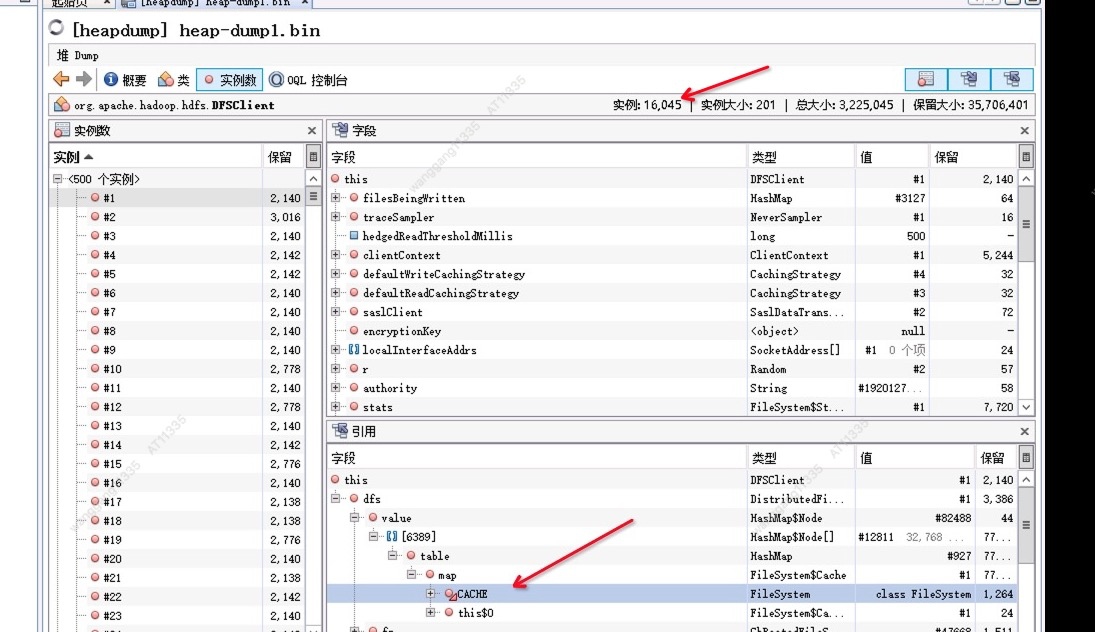
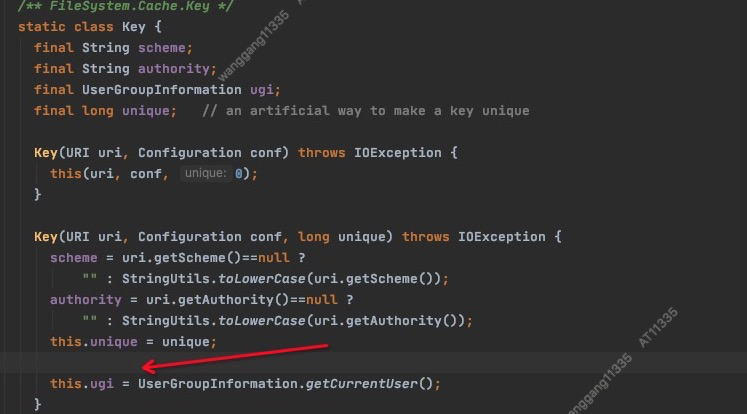
cache中具体缓存使用的key如图 scheme, authority,ugi,unique 其中unique可以忽略,在visualvm上看都是相同的,scheme及authority记录着几个namenode的地址,值也并不多,唯一异常的就是存在超大量的ugi对象,此时内存泄漏的真凶差不多找到了。
发现在改造的Iceberg支持代理用户的代码中,每次调用getFs方法都要重新创建一个ugi对象。
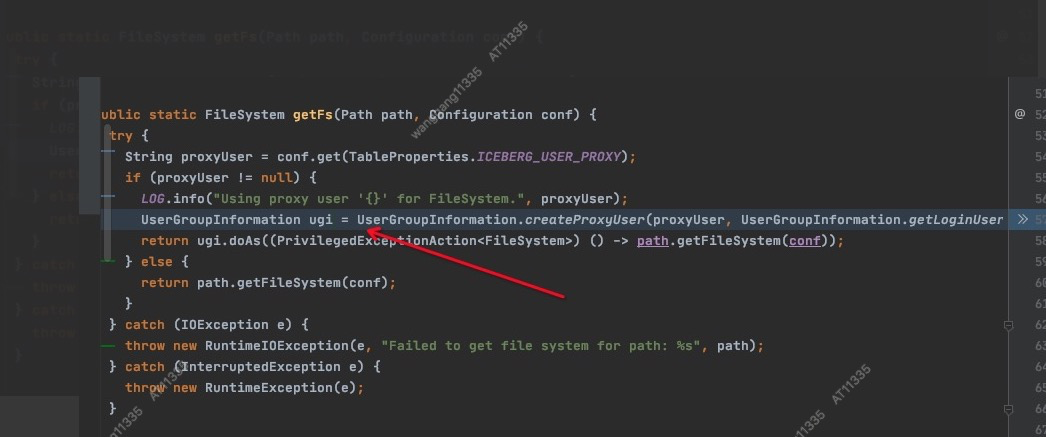
ugi按用户缓存起来之后,cache里面的DFSClient对象数量就符合预期了。这个任务就再也没有发生过堆内存泄漏了。