ICLR 2022: Scene Transformer: A unified architecture for predicting future trajectories of multiple agents
Type: ICLR
Year: 2022
组织: waymo
-
参考与前言
- openreivew
https://openreview.net/forum?id=Wm3EA5OlHsG
Scene Transformer: A unified architecture for predicting multiple agent trajectories
主要受语言模型方法 language modeling approach 启发而来
问题场景任务:多agent的轨迹预测问题
难点:因为agent本身行为的多样性 (diverse),加之对彼此轨迹的影响(influence)
之前工作主要聚焦在根据过去动作预测 单独 agent的未来轨迹,然后根据各自的预测来进行规划;但是呢 independent predictions 并不利于表示未来状态下 不同agent之间的交互问题,从而引申规划时也是sub-optimal的轨迹
- marginal prediction:未来时刻 不同agent预测的轨迹可能会有冲突部分,即两者相交
- joint prediction:在同一未来时刻,不同agent的预测轨迹不会冲突, respect each others’ prediction
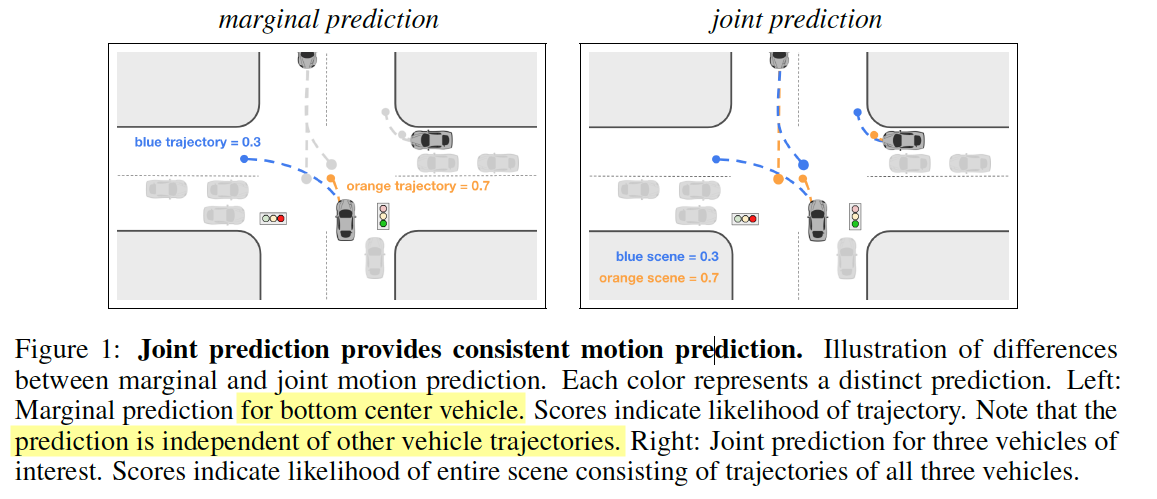
formulate a model 去同时(jointly)预测所有的agent行为,producing consistent future 来解释agent之间的行为
以下为原文,这个贡献的格式和jjh说的TRO格式好像,名词方法为主语
-
A novel, scene-centric approach that allows us to gracefully switch training the model to produce either marginal (independent) and joint agent predictions in a single feed-forward pass.
仅在单个feed-forward中进行marginal和joint prediction之间的切换
-
A permutation equivariant Transformer-based architecture factored over agents, time, and road graph elements that exploits the inherent symmetries of the problem.
使用与 transformer 相同(等价)的permutation 来将agents, time和road graph都考虑在系统内
-
A masked sequence modeling approach that enables us to condition on hypothetical agent futures at inference time, enabling conditional motion prediction or goal conditioned prediction.
masked sequence modeling 能使我们将未来考虑在内,时间意义上
问题区:
-
Through combining a scene-centric approach, agent permutation equivariant model, and a sequence masking strategy
-
后面介绍部分解释了,见前面解释
-
为什么要切换
方法处说明了 是不同的任务之间都可以用这一个网络进行,主要任务是:motion prediction、conditional motion prediction、goal-conditioned prediction
-
方法中有具体介绍,静止的road graph用feature vector形式,动态的比如红绿灯是one feature vector per object形式
-
mask的原因其实是切换... The approach is flexible, enabling us to simultaneously train a single model for MP, CMP, GCP.
相关工作主要是围绕,此处仅做简单总结,主要是前情提要知识补充 可能能解答上面的问题
-
motion prediction框架:说明成功的模型大多都会考虑agent motion history和道路结构(包括lane, stop line, 红绿灯等等);
相关方式:
- 直接将输入渲染为多通道的鸟瞰图 top-down image,然后使用卷积,但是receptive field并不利于capturing spatially-distant intersection
- entity-centric approach:可以将agent的历史状态使用sequence modeling方式例如 RNN,进行编码,其中将道路结构中 pose 信息和 semantic type 都编码(比如以piecewise-linear segments)进入系统;使用如下方法将信息进行聚合:employ pooling, soft-attention, graph neural networks
-
scene-centric 和 agent-centric representation:主要是讨论 representation encoding所用的框架
- 以scene-level 作为坐标系,rasterized top-down image,虽然能有效的表示world状态在common的坐标系下,但是丧失了一些潜在的pose信息
- 以agent-coordinate 为坐标系,但是随着agent数量上升 同时 交互的数量也会二次方上升。
后续说明 waymo的另一篇工作LaneGCN就是以agent为中心 但是实在global frame下做的。同时也不需要将场景表示成为图像的形式
-
Representing multi-agent futures:主要是如何表示多agent的未来状态,常用的有直接对每个agent的轨迹使用权重
问题区:
-
一个是representation,一个是以什么为中心进行
输入
a feature for every agent at every time step
在模型中 是一个3d tensor,A 个 agents,每个里面有D个特征维度,在时间T steps,同时在每层layers中我们都想保持住这样的size:\([A,T,D]\)
注意在decoder中有多的一个维度:F potential futures
输出
an output for every agent at every time step
2.2 框架整体模型名称:scene transformer,一共有三个阶段:
- 将agents和road graph embed到一个高维空间
- employ attention-based network 去 encode agents和road graph之间的交互
- 使用attention-based network 去 decode multiple future

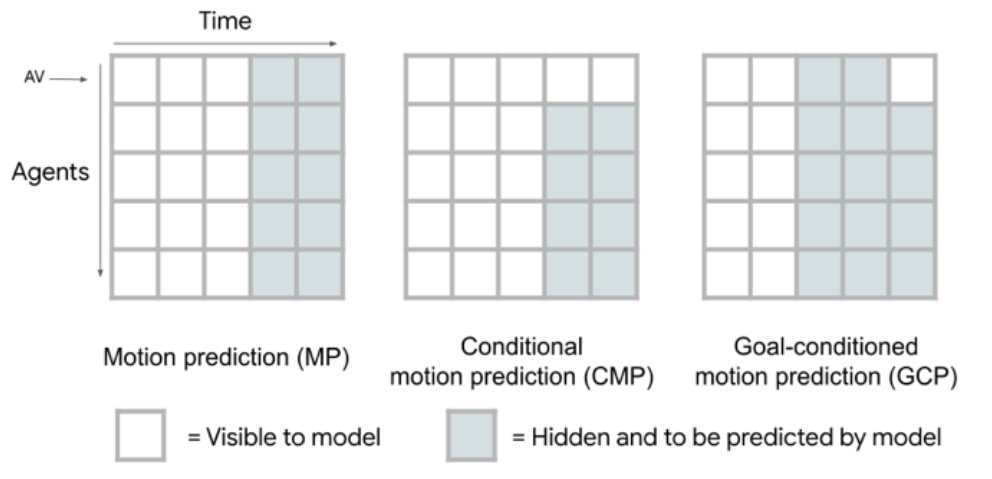
mask
对于多任务的切换主要用mask来实现,如下图所示,在做MP的时候时间维度上有mask被遮挡,但是如果是CMP则自身的motion提供未来时间内motion,GCP的话就是提供最远时间T的AV motion
此点主要是以什么为中心进行场景周围信息的获取,正如前面相关工作中提到的,此处以场景为中心 也就是使用 an agent of interest’s position 作为原点,对所有的road graph和agents进行编码;以agent为中心的话,就是对每个agent分别进行以其为原点的计算
此步中细节步骤为:
- 为每个agent生成 time step内的feature,if time step is visible
- 使用 PointNet 为static road graph和其余的元素 learning one feature vecctor per polyline,其中交通标志 sign为长度为1的polylines
- 为dynamics road graph 比如在空间上是静止的在时间上是变换的红绿灯,生成为 one feature vector per object
所有的以上类别都具有xyz位置信息,以其选定好的agent作为居中,对剩余类别进行居中 旋转等处理,再使用sinusoidal position embeddings
B. Encoding Ttansformer和基本的attention并无太大区别,query, key, value为需要学习的线性层,每个都乘一下输入 x,比如:\(Q=W_qx\),如上图的encoder和decoder框图,其中decoder最后接了两层MLP然后 predict 7 outputs,其中前六个对应的是:三个是在给定时间下的agent的三维与the agent of interest之间的绝对坐标,and 三个是不确定性 遵循Laplace 分布的参数。后一个是heading
为了寻求更高效的self-attention,仅在时间层上使模型独立于agent进行平滑轨迹的学习,同样的仅在agent层上使模型独立于time进行interaction的之间的学习,类似于解耦,如上图decoder部分下面,交替进行两次
与road graph之间是cross attention
C. Predicting Probabilities for each Futures预测的是概率分数,不论是joint里的每个未来的情况打分还是marginal model里对轨迹的打分。所以我们需要一个feature representation去总结 scene和each agent.
根据agent和time下 对agent feature tensor进行分别求和,然后加到additional artificial agent and time,所以internal representation就会变成 \([A+1,T+1,D]\)
然后作为decoder的输入,经过两层 MLP+softmax 得到等价的probabilities for each features
D. Joint and Marginal Loss Formulation首先对于所有的agent都有一个displacement loss and time step to build a loss tensor of shape \([F]\),但是我们仅将最接近于真值的进行back-propagate反向传播;对于marginal的预测呢 则是每个agent都是单独的对待,也就是得到了displacement loss是 \([F,A]\),但是并不aggregate across agents而是为每个agent选取最小的loss然后反向
问题区:
-
有框图解释了两者的设计方式
-
应该是数据集,所以可以直接获取未来数据集内的motion进行此任务
-
-
脚注和open reivew中也有审稿人问了 hhh,脚注说明了 对于waymo是 自身车辆,对于Argoverse是需要预测的车辆
-
-
这里的所有是指?
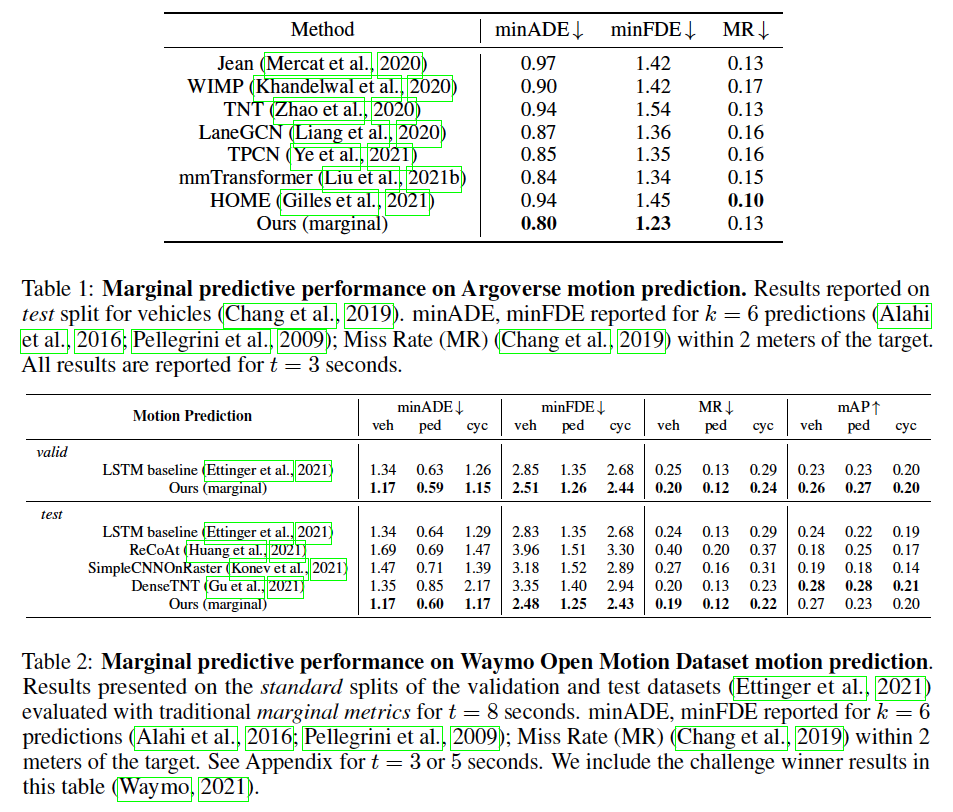
指标为预测中场景的minADE, minFDE, miss rate和mAP,基本上都是用来测量 how close the top k trajectories are to ground truth observation,也就是预测的轨迹离真值有多近
- L2: A simple and common distance-based metric is to measure the L2 norm between a given trajectory and the ground truth
- minADE: reports the L2 norm of the trajectory with the minimal distance
- minFDE: reports the L2 norm of the trajectory with the smallest distance only evaluated at the final location of the trajectory.
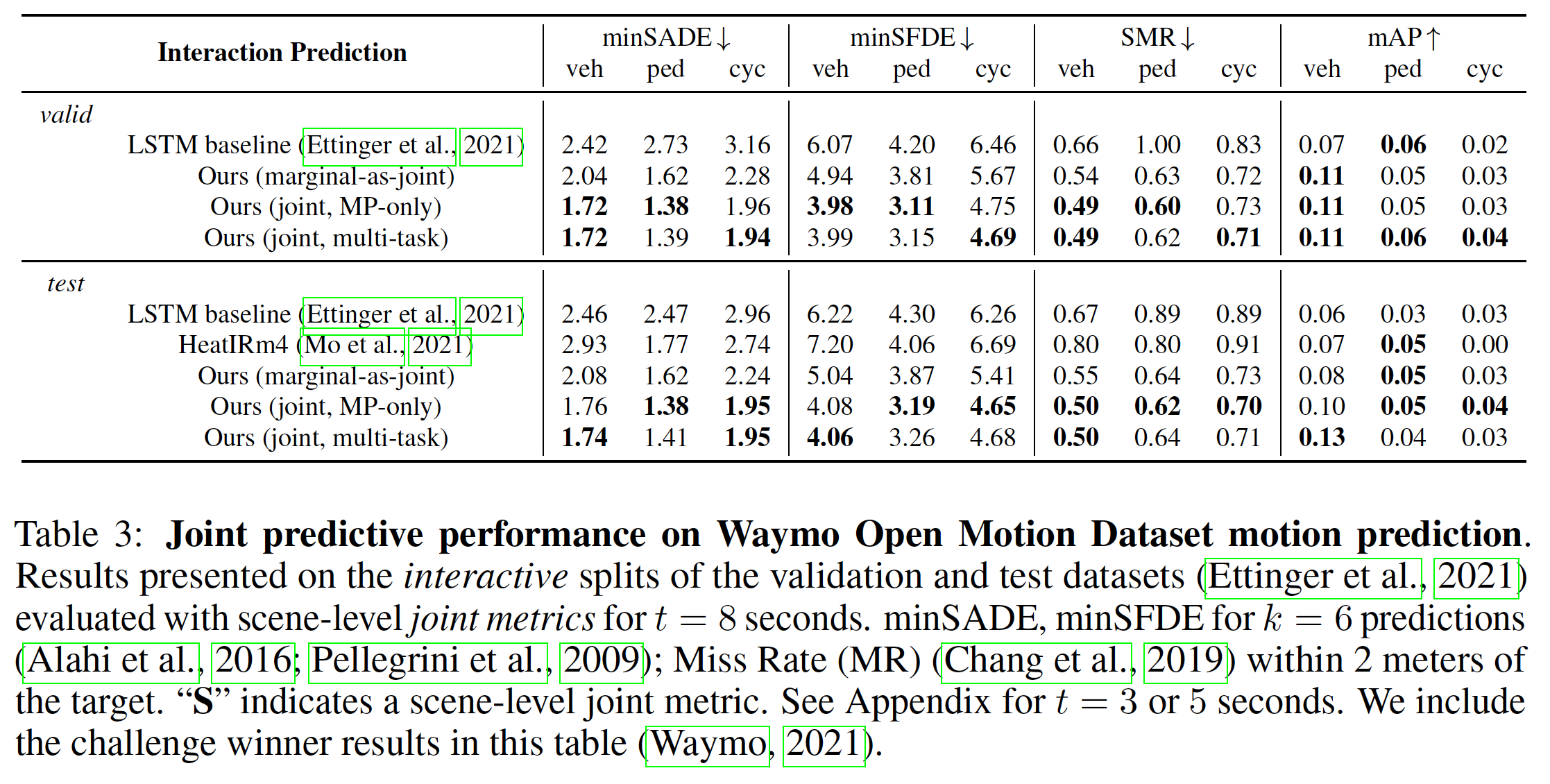
本文所有的是MR, mAP,对于joint future则是scene-level下的minSADE, minSFDE, SMR
- miss rate (MR) and mean average precision (mAP) to capture how well a model predicts all of the future trajectories of agents probabilistically
主要就贴一下实验表格等
场景分析图:
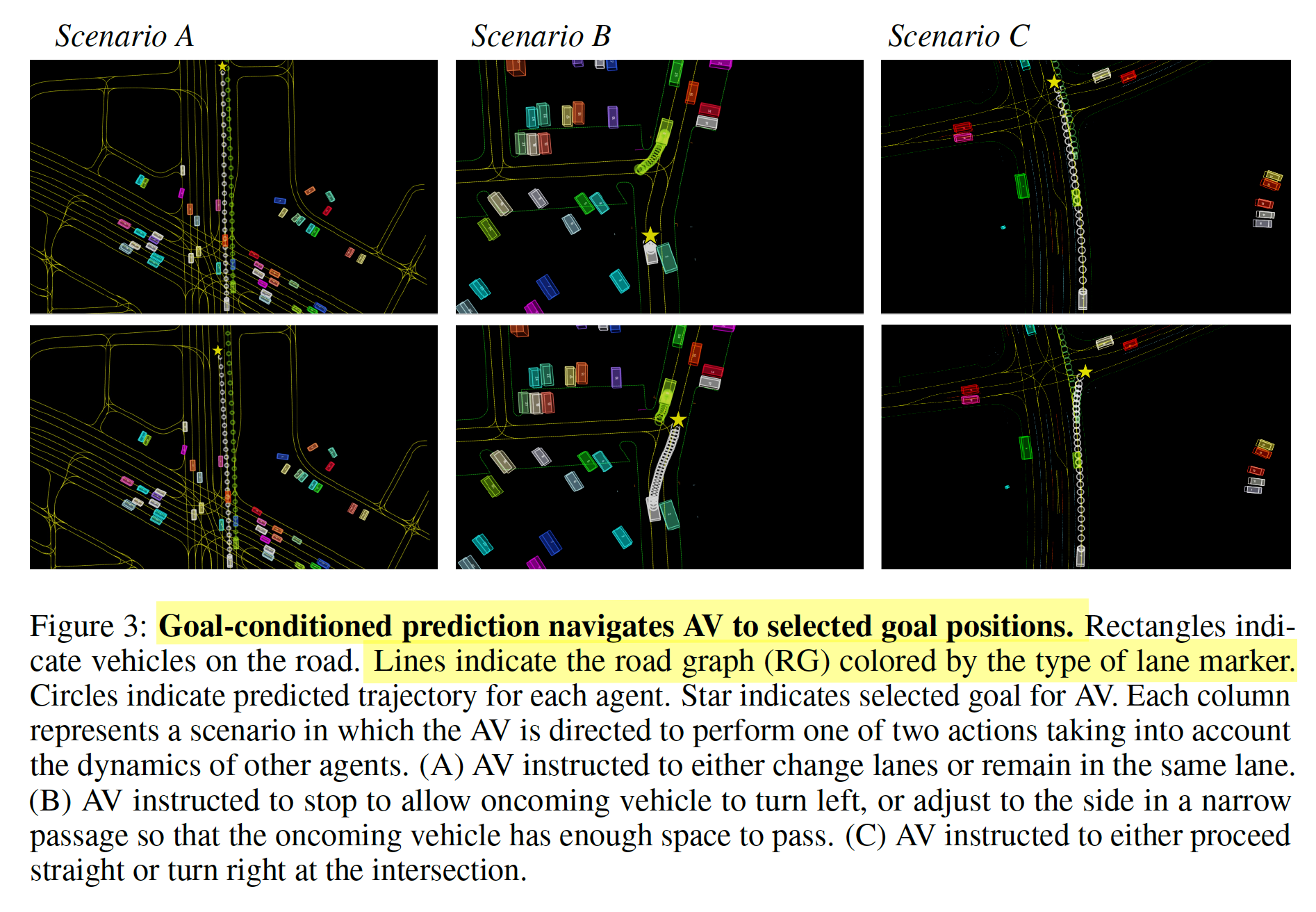
指明不同的目标点,预测也会随之变换,响应前文提出的switch task GCP
4. Conclusion
正如CJ哥所言:waymo必然不开源;但是吧 每个论文的附录都特别仔细到 让我这种小白菜觉得 哇 emm 似乎可以复现呢,但是这篇可能没细看附录的原因 有好几个地方还是有点存疑的,hhhh。所以主要重点看看他们的框架是怎么搭的 更为重要,waymo三篇基本都是自己设计的网络不走resnet或者regnet 有预训练的参数。更多细节 要是感兴趣的话 建议读一下原文的附录部分,网络参数等都介绍的较为详细
这一篇虽不及MP3惊艳,但似乎奠定了应该用vector的形式去做预测 类似于CJ哥在multipath++笔记中提到,vectornet有一统的趋势。其实pointnet之类的在17年的就提出了 进来以pointnet → vectornet → 再到现在的一系列基本都是attention下的各种玩法
open review值得一看 还是这种开放审稿的有意思啊,因为有审稿人对GCP的结果说明产生了问题,类似于建议作者在CARLA做 就是以目标点的condition prediction其实已经很像planning了,基本就是 加一下控制器,然后作者谢谢提醒,我知道(内心OS:但是我不做hhhh)
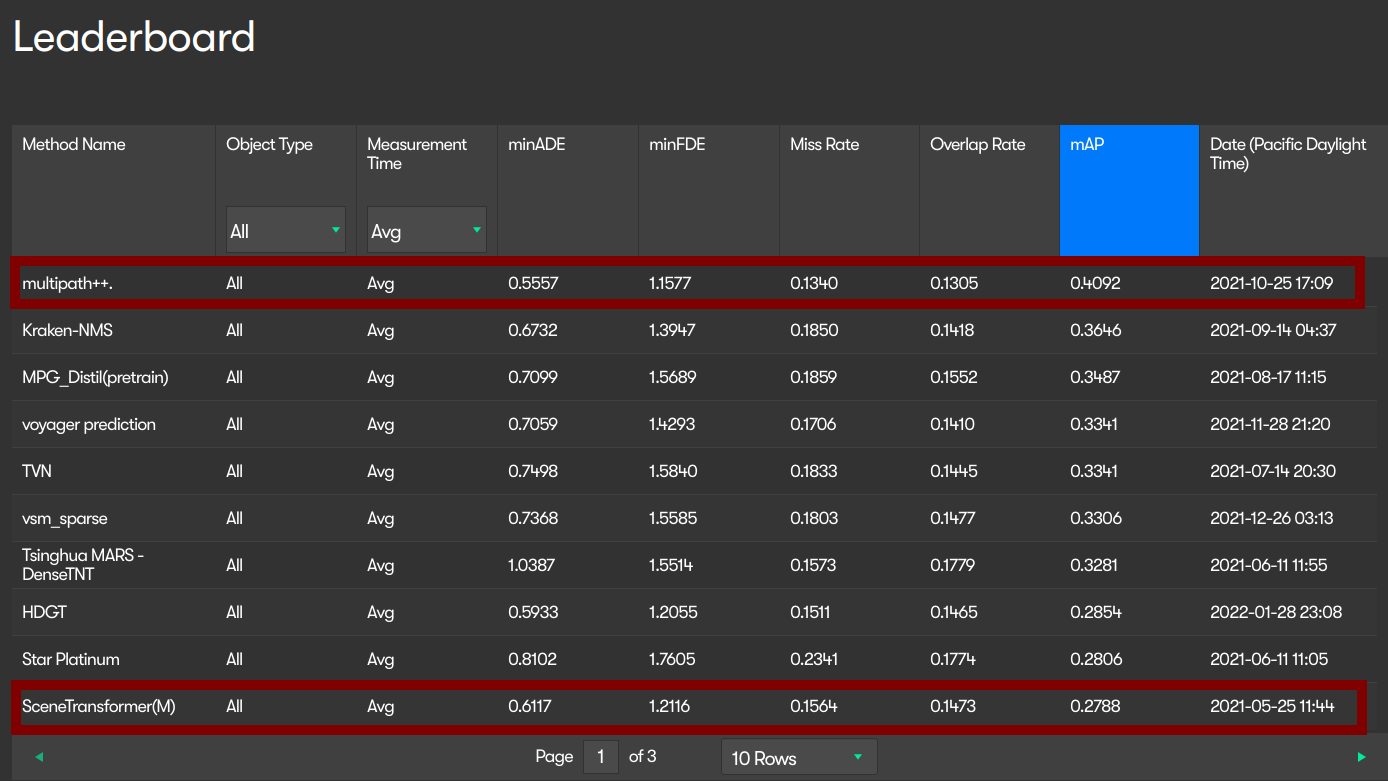
另外贴一下 我在前面说的 online leaderboard 下 确实排名不高,不过按提交时间的话 就另说了
赠人点赞 手有余香