大家好,我是咔咔 不期速成,日拱一卒
ElasticSearch致力于搜索的同时,也提供了聚合实时分析数据的功能,聚合可以实现把复杂的数据进行一系列计算后得出我们想要的数据。
虽然聚合的功能与搜索完全不同,但使用的数据结构是完全相同的,因此聚合的执行速度很快,也就是说在一次请求中对相同数据可以同时进行搜索+过滤、分析。
在ElasticSearch中聚合共分为四大类:
- Bucket Aggregation:分桶类型,一些列满足特定条件的文档集合
- Metric Aggregation:指标分析类型,对数据进行数学运算,例如求最大、小值
- Pipeline Aggregation:管道分析类型,已经聚合的结果进行二次聚合
- Matix Aggregation:矩阵分析类型,支持对多个字段操作并提供一个结果矩阵
先从简开始,看一下Bucket、Metric这两种类型,Bucket实现的结果就是MySQL中group关键字的使用,Metric则是MySQL中max、min函数的使用。

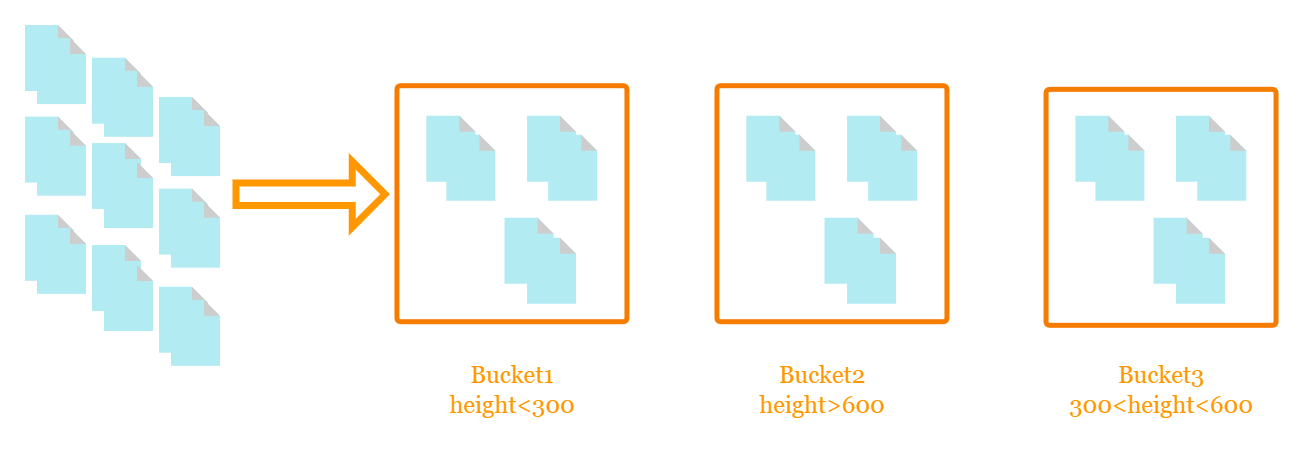
通过上图可得知将数据分为了三个桶,第一个桶统计的是身高小于300,第二个桶统计的是身高大于600,第三个桶统计的是身高在300到600之间的,在这个案例中就是根据不同的身高分到不同的桶中。
使用聚合分析机制还可以按照年龄、地理位置、性别、薪资范围、订单增长情况、工作岗位分布等。只要有一定共同点的数据都可使用聚合进行归档处理。
常见的Bucket分桶策略
- terms:按照term来分桶,如果是text类型则会按照分词后的结果进行分桶
- range:指定数值的范围来设定分桶规则
- data range:指定日期的范围来设定分桶规则
- histogram:固定的间隔来来设定分桶规则
- data histogram:针对日期的直方图或柱状图
根据目的地进行分桶
post /kibana_sample_data_flights/_search
{
"size":0,
"aggs":{
"destcountry_term":{
"terms": {
"field": "DestCountry"
}
}
},
"profile":"true"
}
从返回结果中看到根据目的地将航班信息进行了归类处理,同时也会发现在ElasticSearch中如果不手动定义size值都会默认只返回10条结果
"aggregations" : {
"destcountry_term" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 3187,
"buckets" : [
{
"key" : "IT",
"doc_count" : 2371
},
{
"key" : "US",
"doc_count" : 1987
},
{
"key" : "CN",
"doc_count" : 1096
},
{
"key" : "CA",
"doc_count" : 944
},
{
"key" : "JP",
"doc_count" : 774
},
{
"key" : "RU",
"doc_count" : 739
},
{
"key" : "CH",
"doc_count" : 691
},
{
"key" : "GB",
"doc_count" : 449
},
{
"key" : "AU",
"doc_count" : 416
},
{
"key" : "PL",
"doc_count" : 405
}
]
}
}
想要查询平均价格在300以下、300~600之间、大于600的案例
post /kibana_sample_data_flights/_search
{
"size":0,
"aggs":{
"avgticketprice_range":{
"range": {
"field": "AvgTicketPrice",
"ranges": [
{"to":300},
{"from":300,"to":600},
{"from":600}
]
}
}
}
}
返回结果如下,可以三条结果都根据不同的区间设置了key值
"aggregations" : {
"avgticketprice_range" : {
"buckets" : [
{
"key" : "*-300.0",
"to" : 300.0,
"doc_count" : 1816
},
{
"key" : "300.0-600.0",
"from" : 300.0,
"to" : 600.0,
"doc_count" : 4115
},
{
"key" : "600.0-*",
"from" : 600.0,
"doc_count" : 7128
}
]
}
}
可以通过设置keyed:true,使每个区间都返回一个特定的名字
post /kibana_sample_data_flights/_search
{
"size":0,
"aggs":{
"avgticketprice_range":{
"range": {
"field": "AvgTicketPrice",
"keyed":"true",
"ranges": [
{"to":300},
{"from":300,"to":600},
{"from":600}
]
}
}
}
}
可以好好的跟上一个案例对比一下区别
"aggregations" : {
"avgticketprice_range" : {
"buckets" : {
"*-300.0" : {
"to" : 300.0,
"doc_count" : 1816
},
"300.0-600.0" : {
"from" : 300.0,
"to" : 600.0,
"doc_count" : 4115
},
"600.0-*" : {
"from" : 600.0,
"doc_count" : 7128
}
}
}
}
当然也可以指定区间的名字
post /kibana_sample_data_flights/_search
{
"size":0,
"aggs":{
"avgticketprice_range":{
"range": {
"field": "AvgTicketPrice",
"keyed":"true",
"ranges": [
{"key":"小于300","to":300},
{"key":"300到600之间","from":300,"to":600},
{"key":"大于600","from":600}
]
}
}
}
}
返回结果
"aggregations" : {
"avgticketprice_range" : {
"buckets" : {
"小于300" : {
"to" : 300.0,
"doc_count" : 1816
},
"300到600之间" : {
"from" : 300.0,
"to" : 600.0,
"doc_count" : 4115
},
"大于600" : {
"from" : 600.0,
"doc_count" : 7128
}
}
}
}
通过指定日期的范围来设定分桶规则,如对timestamp字段按照设定的时间段来分桶。
post /kibana_sample_data_flights/_search
{
"size":0,
"aggs":{
"data_range_timestamp":{
"date_range":{
"field":"timestamp",
"format":"yyyy-MM",
"ranges":[
{"from":"2022-01","to":"2022-02"},
{"from":"2022-02","to":"2022-03"}
]
}
}
}
}
返回结果,思考一下如果想要设置固定的key值应该怎么设置呢?还有要注意的是日期格式yyyy-MM-dd HH:mm:ss
"aggregations" : {
"data_range_timestamp" : {
"buckets" : [
{
"key" : "2022-01-2022-02",
"from" : 1.6409952E12,
"from_as_string" : "2022-01",
"to" : 1.6436736E12,
"to_as_string" : "2022-02",
"doc_count" : 9580
},
{
"key" : "2022-02-2022-03",
"from" : 1.6436736E12,
"from_as_string" : "2022-02",
"to" : 1.6460928E12,
"to_as_string" : "2022-03",
"doc_count" : 1837
}
]
}
}
直方图,以固定间隔的策略来分割数据,如对AvgTicketPrice字段按照100的间隔进行分桶
- interval :每次间隔50
- min_doc_count :存在的文档数最少是0条
- extended_bounds :此值只有当min_doc_count 为0时才具有意义
在实现时你会发现extended_bounds不过滤桶。extended_bounds.min高于从文档中提取的值,那么文档仍然会规定第一个存储段将是什么(对于extended_bounds.max和最后一个存储段也是如此)。为了过滤桶,您应该将直方图聚合嵌套在范围过滤器聚合中,并使用适当的从/到设置
post /kibana_sample_data_flights/_search
{
"size":0,
"aggs":{
"price_histogram":{
"histogram": {
"field": "AvgTicketPrice",
"interval": 50,
"min_doc_count":"0",
"extended_bounds":{
"min":0,
"max":600
}
}
}
}
}
返回结果
"aggregations" : {
"price_histogram" : {
"buckets" : [
{
"key" : 0.0,
"doc_count" : 0
},
{
"key" : 50.0,
"doc_count" : 0
},
{
"key" : 100.0,
"doc_count" : 380
},
{
"key" : 150.0,
"doc_count" : 369
},
{
"key" : 200.0,
"doc_count" : 398
}
]
}
}
针对日期的直方图或者柱状图,是时序数据分析中常用的聚合分析类型,如对timestamp字段按照月的间隔进行分桶
post /kibana_sample_data_flights/_search
{
"size":0,
"aggs":{
"timestamp_data_histogram":{
"date_histogram": {
"field": "timestamp",
"interval": "month",
"min_doc_count": 0,
"format": "yyyy-MM-dd",
"extended_bounds": {
"min": "2021-10-10",
"max": "2022-01-19"
}
}
}
}
}
返回结果
"aggregations" : {
"timestamp_data_histogram" : {
"buckets" : [
{
"key_as_string" : "2021-10-01",
"key" : 1633046400000,
"doc_count" : 0
},
{
"key_as_string" : "2021-11-01",
"key" : 1635724800000,
"doc_count" : 0
},
{
"key_as_string" : "2021-12-01",
"key" : 1638316800000,
"doc_count" : 1642
},
{
"key_as_string" : "2022-01-01",
"key" : 1640995200000,
"doc_count" : 9580
},
{
"key_as_string" : "2022-02-01",
"key" : 1643673600000,
"doc_count" : 1837
}
]
}
}
上文中列举了五种分桶的实现,在实际开发中只是单一的进行聚合查询是非常少的,大多情况下都是会进行嵌套操作。
先根据机票进行分桶后,再对分桶后的数据取总数、最小值、最大值、平均值、总和
post /kibana_sample_data_flights/_search
{
"size":0,
"aggs":{
"price_range":{
"range": {
"field": "AvgTicketPrice",
"ranges": [
{"to":300},
{"from":300,"to":600},
{"from":600}
]
},
"aggs":{
"price_status":{
"stats": {
"field": "AvgTicketPrice"
}
}
}
}
}
}
返回结果(返回结果截取显示了)
"aggregations" : {
"price_range" : {
"buckets" : [
{
"key" : "*-300.0",
"to" : 300.0,
"doc_count" : 1816,
"price_status" : {
"count" : 1816,
"min" : 100.0205307006836,
"max" : 299.9529113769531,
"avg" : 212.5348257619379,
"sum" : 385963.2435836792
}
}
]
}
}
还有更多的操作等待我们去挖掘,先把基础的搞定,不期速成,日拱一卒
坚持学习、坚持写作、坚持分享是咔咔从业以来所秉持的信念。愿文章在偌大的互联网上能给你带来一点帮助,我是咔咔,下期见。