一、问题提出标题:机器推理的合成注意网络
来源:ICLR 2018 https://arxiv.org/abs/1803.03067
代码:https://github.com/stanfordnlp/mac-network
作者笔记:https://cs.stanford.edu/people/dorarad/mac/blog.html
虽然当前的深度神经网络模型在学习”输入和输出之间的直接映射“方面非常有效,其深度、规模和统计特性使得它们能够处理嘈杂和多样化的数据,但也限制了它们的可解释性,无法展示出一个连贯且透明的“思维过程”来得到他们的预测。
深度学习系统缺少推理能力,例如下例中,问题需要分步解决——从一个对象遍历到相关对象,迭代地朝着最终解决方案前进。

建立连贯的多步推理模型对于完成理解任务至关重要,作者文中提到了前人提出的一些将符号结构和神经模块起来的方法,例如:神经模块网络,其存在一定的问题,必须依赖于外部提供的结构化表示和功能程序,并且需要相对复杂的多阶段强化学习训练方案。这些模型结构的刚性和对特定操作模块的使用削弱了它们的鲁棒性和泛化能力。
为了在端到端的神经网络方法的通用性和鲁棒性 与 支持更加明确和结构化推理 的需求之间取得平衡,作者提出了MAC 网络,这是一种端到端的可微推理架构,用来顺序执行具体推理任务。
二、主要思想给定一个知识库K(对于VQA,是一个图像)和一个任务描述q(对于VQA,是一个问题),MAC网络将问题分解为一系列推理步骤,每一个推理步骤使用一个MAC单元。
其组成主要包括三部分:
- 输入单元
- 堆叠的MAC单元(执行推理任务)
- 输出单元
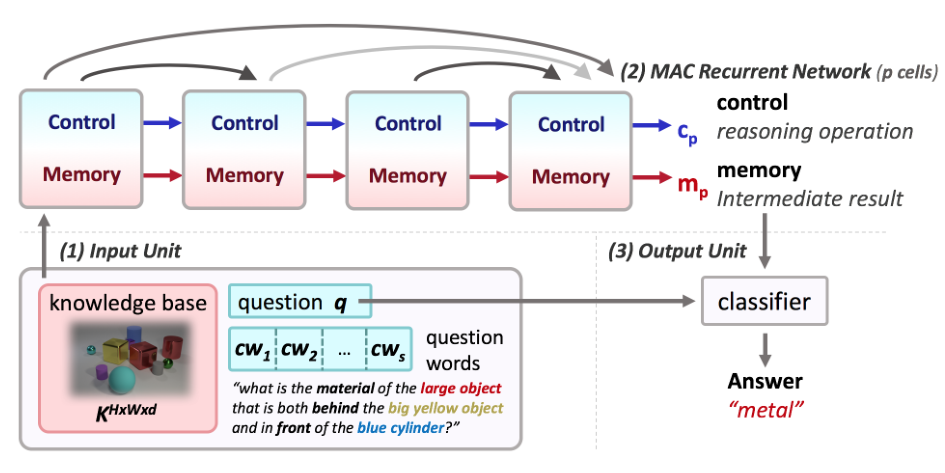
Part1:输入单元
处理输入的图片和问题:
图片:使用预训练的ResNet提取特征,获取中间层conv4特征,并后缀CNN得到图片每一个小块的特征表示,最终组合得到知识库:
\[K^{H\times W\times d}=\{k_{h,w}^d|_{h,w=1,1}^{H,W}\},H=W=14 \]文本:将字符串转换为单词嵌入序列,并通过d维Bi-LSTM网络提取特征:
一系列隐藏状态:\(cw_1,...,cw_s\)。
问题特征表示:最后的隐藏状态的拼接\(\overleftarrow{cw_1},\overrightarrow{cw_s}\),输入MAC单元时需要进行线性变换:\(q_i={W_i}^{d\times2d}q+b_i^d\)。
Part2:MAC单元
MAC单元(Memory、Attention、Composition)是一个循环单元,被设计的类似于GRU或LSTM。
设计理念:
MAC网络内部的设计作者借鉴了计算机体系结构的知识,将控制和内存分离,通过串行执行一系列指令来操作:
Step1:控制器获取指令并进行解码;
Step2:按照指令的指示,从内存中读取信息;
Step3:执行指令,选择地写入相应的内存,并考虑处理的信息进行下一步循环。
组成:
基于此,MAC单元显式地将内存与控制分离,内部保持双重隐藏状态:维度为\(d\)的控制状态\(c_i\)和内存状态\(m_i\),并由三个串联工作的操作单元组成,以执行一个推理步骤:
- 控制单元Control:在每一步选择性地处理问题词序列中的一些部分来计算推理操作(这一步计算注意力来得到单词序列上的概率分布,表示该步骤对每个词的关注程度),并更新控制状态来表示单元要执行的推理操作。
- 读取单元Read:在控制状态的指导下,从知识库中提取相关信息(在图片中选择性关注部分区域,同样使用注意力分布来表示提取到的信息)
- 写单元Write:将提取到的新信息和前一步内存状态整合在一起,存储中间结果并更新内存状态——该状态为当前推理获得的结果。
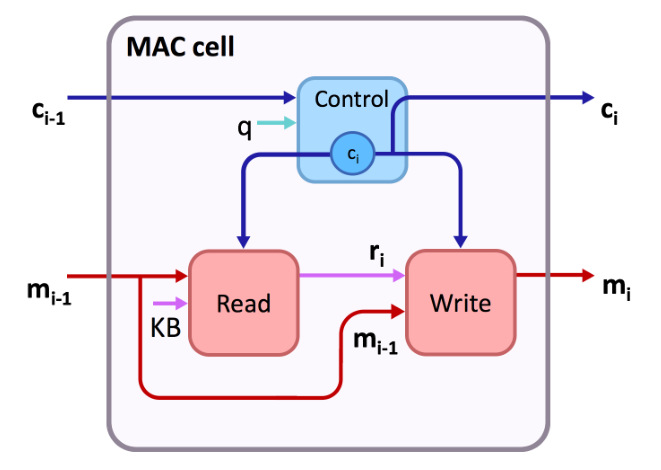
初始化:初始化学习参数\(c_0\)和\(m_0\)。
控制单元:
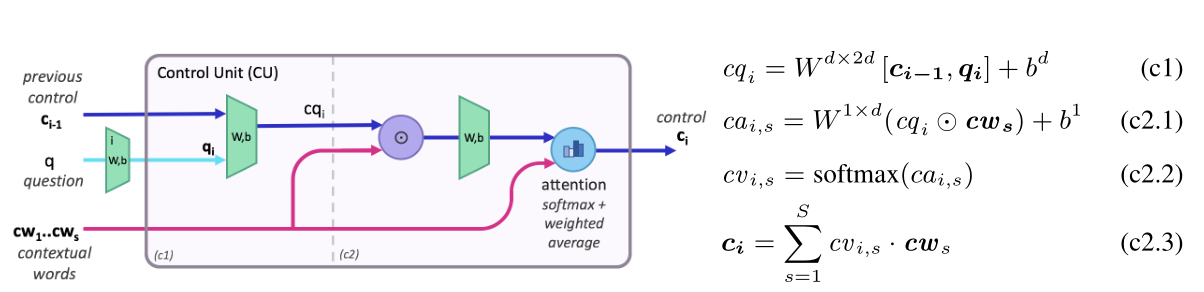
输入:问题词序列\(cw_1,...,cw_s\),问题特征\(q_i\),前一步的控制状态\(c_{i-1}\)
Step1:拼接问题特征表示\(q_i\)和先前的控制状态\(c_{i-1}\)并进行线性变换(获取相关知识);
Step2:基于注意力生成推理操作\(c_i\):首先计算\(cq_i\)和每个问题词特征的相似度,之后通过线性变换和softmax函数获得问题词序列上的注意力分布,最后基于该分布对词进行加权求和生成新的推理操作\(c_i\)。
补充:后续该注意力可以用于可视化并解释控制状态内容,提高模型的透明度。
读取单元:
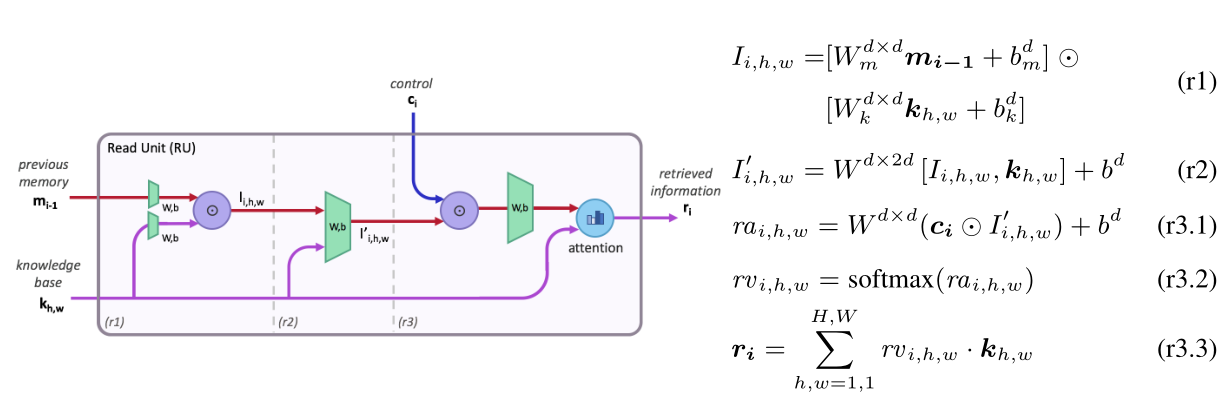
输入:知识库\(k_{h,w}\),前一步的内存状态 \(m_{i-1}\),当前步骤的控制状态\(m_i\)
Step1:通过将知识库元素和前一步的内存状态进行线性变换并对应位置相乘,提取模型从之前推理步骤中获取到的中间信息\(I_{i,h,w}\)。
Step2:拼接知识库元素和中间结果。考虑到一些推理过程需要将独立的事实组合在一起得到答案,该步骤将允许模型推理考虑与之前的中间结果不直接相关的新信息。
Step3:计算控制状态\(c_i\)和中间信息\(I_{i,h,w}^`\)的相似度,并通过softmax产生知识库元素上的注意力分布,最终加权求和得到读取单元的检索信息\(r_i\)。
可视化注意力:

例子:问题“what color is the matte thing to the right of the sphere in front of the tiny blue block”,首先找到蓝色小块并更新\(m_1\),之后控制单元关注到”the sphere in front of“,找到前面的球体并更新\(m_2\),最后关注到"the matte thing to the right of",找到问题的结果:紫色圆柱。
写单元:
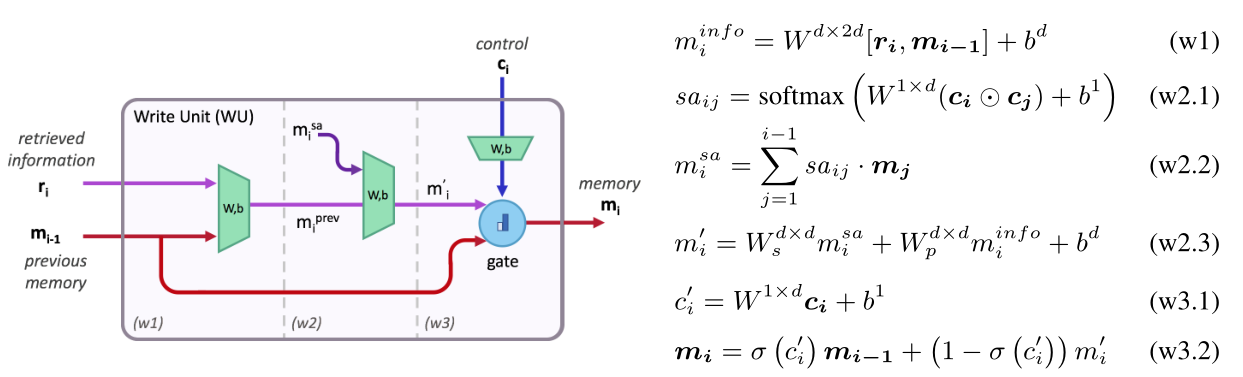
输入:前一步的内存状态 \(m_{i-1}\),读取单元的检索信息\(r_i\),当前步骤的控制状态\(m_i\)
主要用于基于推理指令,集成先前推理得到的内存状态和该步得到的检索信息
Step1:拼接\(r_i\)和\(m_{i-1}\)并进行线性变换,得到更新的内存状态\(m_i^{info}\);
可选操作:
Step2:注意力机制:为了支持非顺序推理,允许单元综合先前的所有内存状态进行更新。计算当前指令\(c_i\)和先前指令序列\(c_1,...,c_{i-1}\)的相关性并生成注意力分布\(sa_{ij}\)。利用该概率分布对前序内存状态进行加权求和,并组合\(m_i^{info}\)得到更新的内存状态\(m_i^`\)。
Step3:记忆门控:允许模型根据给定的问题动态调整推理过程长度。基于指令可选的更新内存状态\(m_i\)。
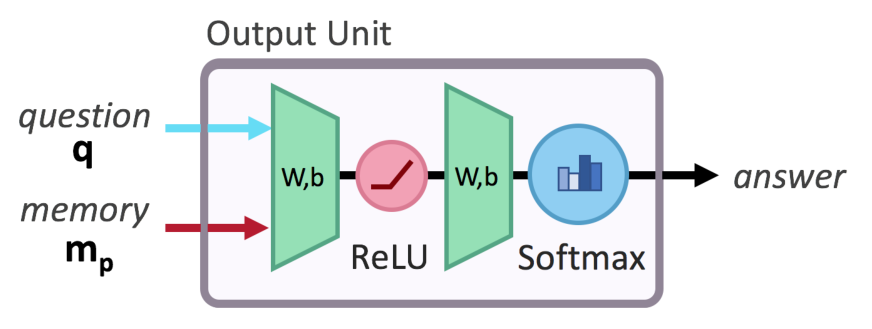
Part3:输出单元
基于问题特征表示\(q\)和最终的存储状态\(m_p\),利用双层全连接softmax分类器获得最终的答案预测。
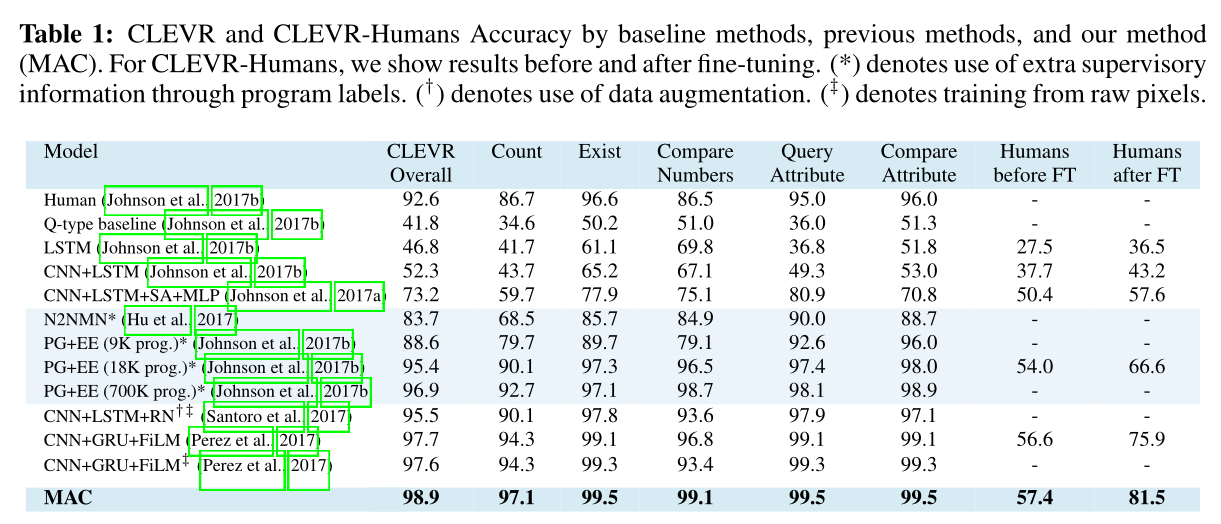
实验:CLEVR数据集
结果:
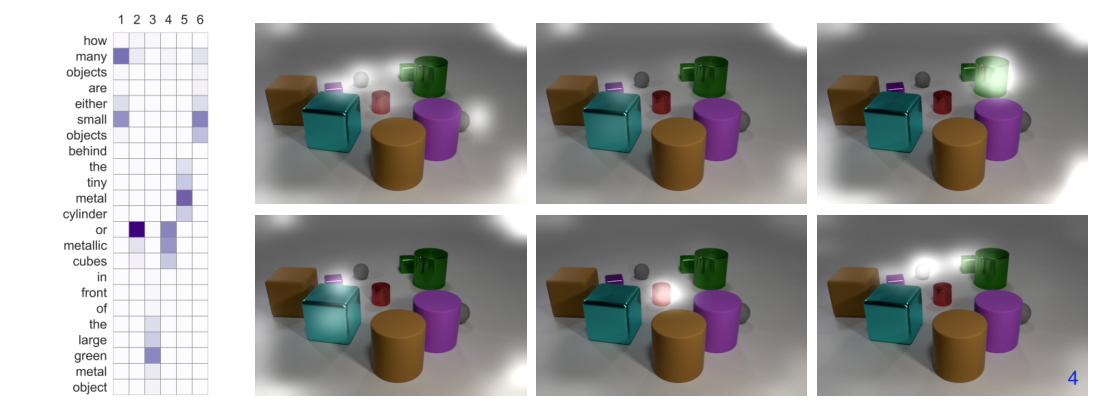
可解释性:

计数:
1、保持问题和图像的表征空间之间的严格分离(它们只能通过可解释的离散分布进行交互),极大地增强了网络的可泛化性,并提高了其透明度。
2、不同于模块网络,MAC是端到端的完全可微网络,无需额外的监督数据,通过MAC单元的堆叠顺序执行推理才做,不需要依靠语法树或者其他设计和部署模块集合。此外,与深度神经网络方法相比,MAC具有更好的泛化性能、更高的计算效率和更透明的关系推理能力。