一、问题提出标题:抽象学习:神经状态机
来源:NeurIPS 2019 https://proceedings.neurips.cc/paper/2019/hash/c20a7ce2a627ba838cfbff082db35197-Abstract.html
代码:暂无 (该项目为网友复现,不全面--> https://github.com/ceyzaguirre4/NSM )
针对神经网络和符号网络各自的优缺点,引入有限自动机的思想,提出一种神经状态机,将各自的互补优势整合到视觉推理任务中。
首先基于给定的图像,使用一个场景图抽取模型,得到对应的概率场景图。其中,对象被转化为节点,并使用属性表示表示特征;关系被转化为边,来捕获对象之间的空间关系和语义关系。此外,对输入的问题进行语义理解,并转化为一系列软指令。在推理过程中,概率场景图被视为一个有限状态机,利用指令集合在其上执行顺序推理,迭代遍历它的节点,以回答一个给定的问题或得出一个新的推理。
不同于一些旨在将多模态数据进行紧密交互的神经网络结构,神经状态机定义了一组语义概念embedding的概念,其描述领域的不同实体和属性,如各种对象、属性和关系。通过将视觉和语言形式转换为基于语义概念的表示,有效地使两种模态可以”说同一种语言“,从而可以在抽象的语义空间中进行综合推理,这使得结构从内容中分离出来,实现模型的模块化,增强模型的透明度和可解释性。
二、主要思想两个阶段:
- 建模:构造状态机。将视觉和语言形式都转换成抽象的表示形式:图像被分解成一个表示其语义的概率图——描述的视觉场景中的对象、属性和关系,问题被转换成一系列推理指令,通过执行指令回答问题。
- 推理:模拟状态机的操作。在问题的指导下对语义视觉场景执行顺序推理:通过迭代地向机器输入指令并遍历其状态来模拟串行计算,以获得答案。
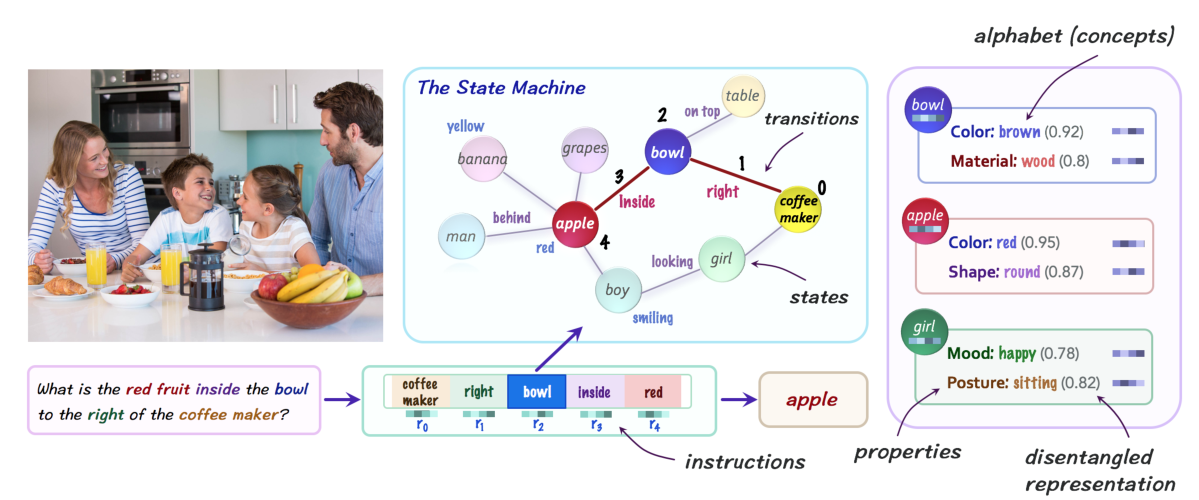
定义:元组\((C,S,E,{{r_i}}_{i=0}^N,p_0,\delta)\)
(1)C:模型的概念词汇表,由一组属性概念组成。
(2)S:状态集。
(3)E:有向边的集合,指定状态之间的有效转换。
(4)\(\{{r_i}\}_{i=0}^N\):维数为d的指令序列,作为过渡函数\(\delta\)的输入依次传递。
(5)\(p_0\):S→[0,1] 初始状态的概率分布。
(6)\(\delta_{S,E}\):\(p_i\times\ r_i\rightarrow\ p_{i+1}\)是状态转移函数。实例化为神经模块,在每一步中,考虑状态分布\(p_i\)和输入指令\(r_i\),并使用它沿边更新分布概率,产生一个更新的状态分布\(p_{i+1}\)。
Part1:概念词汇表Concept vocabulary C
用于捕获和表示输入图像的语义内容。
L + 2个属性:
一个对象主体\(C_O=C_0\) eg:cat
L个属性\(C_A=U_{i=1}^LC_i\) eg:颜色、形状、材质
一种关系\(C_R=C_{L+1}\) eg:持有、看
每个属性类型定义了一组D维embedding。
Part2:状态集 S 和 边集 E
构建一个概率场景图,提取给定图像中的对象和关系,构建机器的状态图。
此处使用了前人提出的场景图生成模型和Mask R-CNN物体检测器。

场景图的组成:
(1)对象节点\(S\),每个对象包括一个边界框、一个mask遮罩、视觉特性表示和对应于概念词汇表中L个语义属性的离散概率分布\(\{{P_i}\}_{i=0}^L\)。转化到概率场景图中,每个对象对应一个状态\(s\in\ S\),使用\(L + 1\)的属性变量\(\{{s^j}\}_{i=0}^L\)表示其特征:
\[s^j=\sum_{c_k \in C_j}{P_j(k)c_k} \]其中,\(c_k\in\ C_j\)表示第j个属性类型的每个子类属性embedding(比如颜色属性里面的红色),\(P_j\)表示这些子属性上的概率分布。该公式主要抽取出每个对象的属性特征。
例子:具有”red“属性的对象,其颜色属性会被赋予接近”red“特征的embedding。
(2)对象之间的关系边,每条边都与语义类型\(C_{L+1}\)上的概率分布\(P_{L+1}\)相关联。类似,计算每一条边的关系语义embedding:
\[e^\prime=\sum_{c_k\in C_{L+1}}{P_{L+1}(k)c_k} \]补充:
每个对象有\((L+1) \times D\)维特征;每个边有\(D\)维特征。
Part3:推理指令Reasoning instructions \(\{{r_i}\}_{{i}={0}}^{N}\)
将问题翻译为推理指令。
Step1:
使用NLP领域的GloVe对问题进行词嵌入,之后将每个词翻译为词汇表中最相近的概念(即和图片映射到同一个语义空间),如果词汇表没有就保留。
针对每个词向量\(w_i\),首先计算和词汇表中属性的相似度的分布:
\[P_i=softmax(w_i^TWC) \]其中,C为所有子属性的embedding,该矩阵中还包括一个额外的embedding\(c^\prime\),表示非内容词汇。
之后,将每个词转变为基于词汇表C的特征表示:
\[v_i=P_i(c^`)w_i+\sum_{c \epsilon C \backslash \{c^`\}}{P_i(c)c} \]基于该变换,问题中属性词会被词典中的对应属性替代;而其余功能词等报错原始embedding。最终得到M个转换之后的词序列\(V^{M\times d}=\{{v_i}\}_{i=1}^M\)。
Step2:
使用一个基于注意力的encoder-decoder结构处理词序列:
encoder部分为一个LSTM循环神经网络,最终状态\(q\)作为问题特征表示;
decoder部分为固定步数(\(N+1\))的循环decoder,其产生\(N+1\)个隐藏状态\(h_i\),每一步decoding时计算对词序列的注意力,并转换为对应的推理指令:
\[r_i=softmax(h_iV^T)V \]该步骤使用注意力机制生成了一系列推理指令,其可以有选择性给关注问题中的各个部分,达到循序渐进找答案的效果。
补充:\(r_i\)为1*d维向量
Part4:模型推理
已求得:
概念词汇表\(C=U_{i=0}^{L+1}C_i\)
图的状态S 每个状态:\(\{{s^j}\}_{i=0}^L\)
边E 每一条边: \(e^\prime\)
指令序列\(\{{r_i}\}_{i=0}^N\)
自动机初始化:场景图上对象的初始概率分布\(p_0\)。
每个推理步\(i\):读取指令\(r_i\),并通过其沿着边更新概率,将注意力重新分配给状态。
\[\delta_{S,E}:p_i\times\ r_i\rightarrow\ p_{i+1} \]Step1:理解指令的含义,即找到与指令\(r_i\)最相关的属性类型。
设\(D\)为词汇表中\(L+2\)个属性,先求出指令和各属性相关的程度:
\(R_i=softmax(r_i^T \cdot D)\)
比如\(R_i(L+1)\in[0,1]\)表示为\(r_i^\prime\),代表着该指令和语义关系的相关性程度。
Step2:得到指令的内容,将其与所有的状态和边进行比较,计算节点和边的相关性分数:
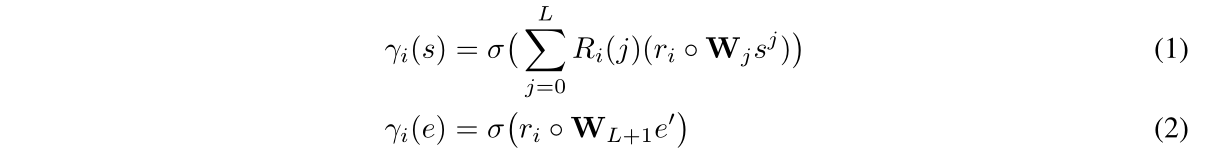
Step3:将模型的注意力从现有状态转移到最相关的邻居状态(即下一个状态):
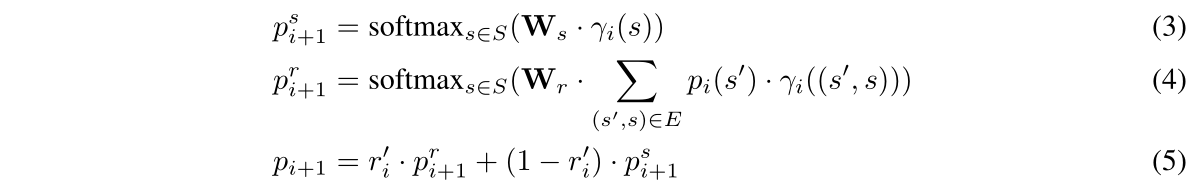
(3)计算基于每个状态自身属性潜在转移的概率,(4)则考虑到相对于当前状态、转移到下一状态的上下文相关性。最终通过加权平均概率得到下一状态的概率分布。
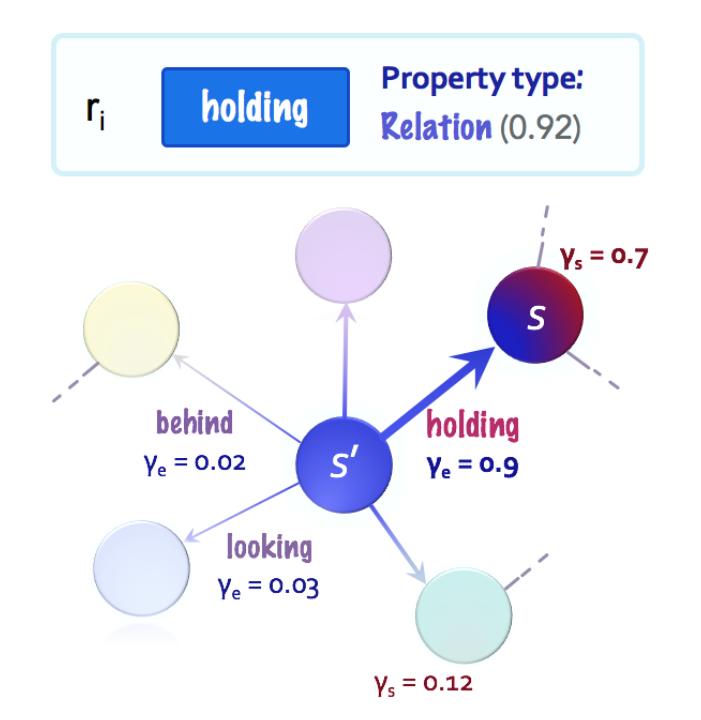
通过将该过程重复执行N步,模拟神经状态机的推理步骤。
Part5:分类
为了预测问题,使用两次全连接层的softmax分类器,接收LSTM输出的问题特征和最终指令\(r_N\)引导下提取到的最终状态聚合得到的信息m:
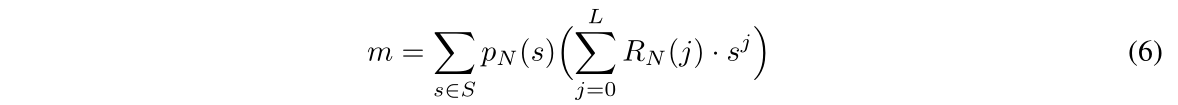
(6)先按照指令类型求平均值,之后加上了对最终状态的注意力\(p_N\)。
三、实验数据集:GQA VQA-CP
结果:
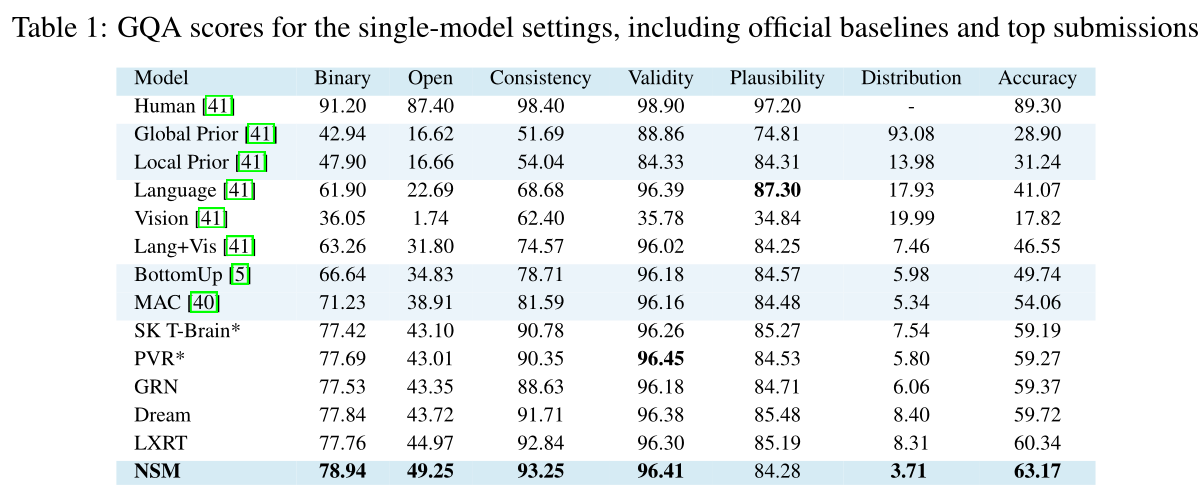
GQA:
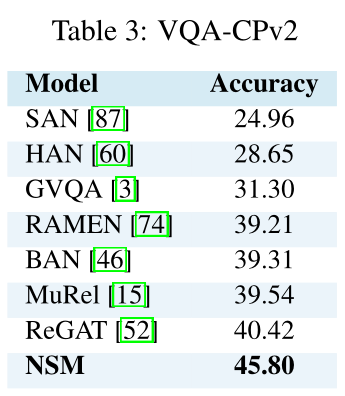
VQA-CPv2:
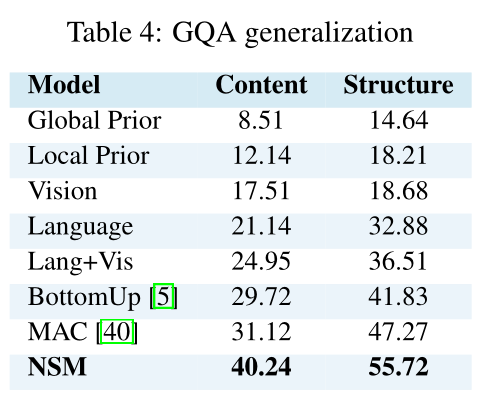
模型泛化性能:
对GQA数据集进行修改,泛化了内容以及语法结构:内容泛化:测试机包括训练集不存在的种类;结构泛化:同中问题语法表达修改。

可视化推理过程:
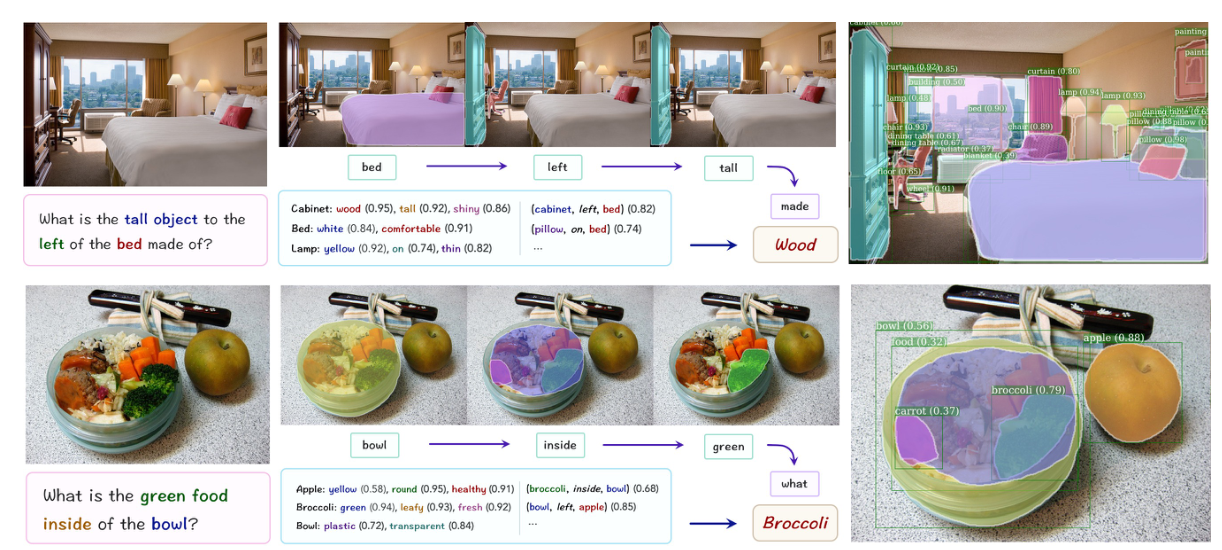
本文提出了神经状态机NSM,其从图像中抽取出一个图结构,并模拟有限自动机的推理步骤,来执行视觉推理任务。通过实验,证明了其有效性、鲁棒性和很好的泛化性能,此外也提高了可解释性。
通过将有限状态机的概念融入神经网络结构,使得符号和连接主义方法更加紧密的整合在一起,从而将神经模型从感官和知觉任务提升到更高层次的抽象、知识表征、组合性和推理领域。