一、问题提出标题:视觉问答中关于组合泛化的多模态图神经网络
来源:NeurlPS 2020https://proceedings.neurips.cc/paper/2020/hash/1fd6c4e41e2c6a6b092eb13ee72bce95-Abstract.html
代码:https://github.com/raeidsaqur/mgn
重点:组合泛化问题

例子:自然语言为例,比如人们能够学习新单词的含义,然后将其应用到其他语言环境中。一个人如果学会了一个新动词 'dax' 的意思,就能立即类推到 'sing and dax' 的意思。” 类似地,在训练的时候,可能在测试集中出现了训练集中没有出现过的元素“组合”(这些元素在训练集中存在)。如:训练集中有“红色的狗”、“绿色的猫”,但是测试集中的数据是“红色的猫”。
问题:在最近的研究表明,模型无法推广到新的输入,而这些输入仅仅是训练集组合分布所见元素中的未遇见过的组合[6]。
一般地,使用卷积神经网络(CNN)构建多模态表示的神经架构将整个图像处理为单个全局表示(例如向量),但无法捕获这种细粒度相关性[29]。
基于神经符号的VQA方法(比如NMNs、NS-VQA和NS-CL)虽然在CLEVR等基准上取得了接近完美的分数[28,29]。但即使视觉输入的分布保持不变(输入图像不变),这些模型也无法推广到新的语言结构组合(问题发生变化)[6]。一个关键原因是缺乏关于图像和文本信息的细粒度的表示,这种表示允许在视觉和语言空间上进行联合合成推理。
二、主要思想作者提出了一种基于图的多模态表示学习方法——多模态图网络(MGN),重点是可以实现更好的泛化效果。图结构可以去捕获实体、属性和关系,从而可以在不同模态(例如图像和文本)的概念之间建立更紧密的耦合。
动机:
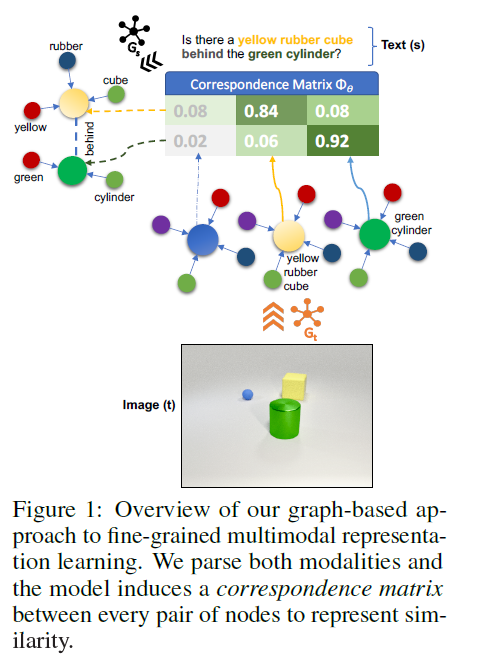
考虑图中的图像和相关的问题:“在大的绿色圆柱体后面有一个黄色的橡皮立方体。”回答这个问题需要首先找到绿色圆柱体,然后扫描它后面的空间,寻找黄色的橡胶立方体。具体来说,1)虽然可能存在其他对象(例如,另一个球),但关于它们的信息可以被抽象出来,2)需要在代表“黄色”和“立方体”的视觉和语言输入之间建立细粒度的联系。
核心思想:将文本和图像都表示为图,自然可以使两种模式之间的概念更紧密地耦合,并为推理提供合成空间。具体来说,首先将图像和文本解析为单独的图,对象实体和属性作为节点,关系作为边。然后,我们使用类似于图神经网络[16]中使用的消息传递算法(message passing),在两种模式的节点对之间导出相似因子矩阵(correspondence factor matrix)。最后,使用基于图的聚合机制来生成输入的多模态向量表示。
具体模型:
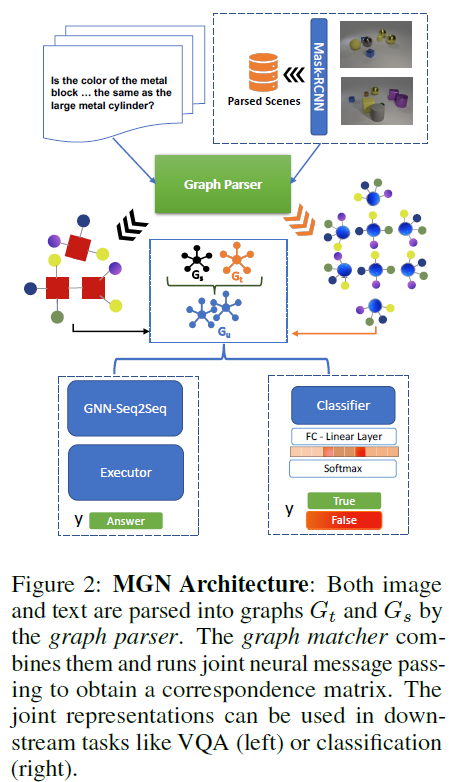
Part1:图结构
多模态输入实例:元组(s,t),其中s是源文本输入(例如,问题或标题),t是对应的目标图像。
图形解析器(Graph Parser):
输入:元组(s,t)
输出:相应的以对象为中心的图\(G_s=(V_s,A_s,X_s,E_s)\)和\(G_t=(V_t,A_t,X_t,E_t)\)。
其中,图中所有节点构成集合V,A是图的邻接矩阵,X是图G中所有节点V的特征矩阵,E是图G中所有边的特征矩阵。
具体的方法:
对输入文本s,使用实体识别模块将对象和属性捕获为图形节点V,然后使用关系匹配模块捕获节点的关系作为图\(G_s\)中的边。

对图像t,使用预训练的Mask RCNN和ResNet-50 FPN图像语义分割模块来获取对象、属性和位置坐标(x、y、z)。这些节点在图\(G_t\)中形成单独的节点。
在\(G_s\)和\(G_t\)中构造节点和边之后,通过使用预先训练的语言模型中的词向量嵌入(word embadding)(假设维度为d)作为文本图节点(对象、属性)和边(关系)的特征向量,从而获得特征矩阵X和E。对于图像场景图,我们使用从“解析场景”(来自Mask-RCNN通道)获得的对象和属性标签作为语言模型的输入,来获得特征嵌入。
图形匹配器(Graph Matcher):
输入:图\(G_s=(V_s,A_s,X_s,E_s)\)和\(G_t=(V_t,A_t,X_t,E_t)\)
输出:生成多模态向量表示\({\vec{h}}_{s,t}\)(维度为2d)——它捕获源节点(文本)和匹配目标节点(图像)的潜在联合表示。
具体方法:
将两个图进行合并,其中节点的初始特征表示:\(h_i^{\left(0\right)}=x_i\epsilon\ X\)。之后利用图神经网路的消息传递算法,通过聚合其邻居的表示来迭代更新向量节点表示。在信息传递的最后,每个节点都获得了来自周围邻居的信息。
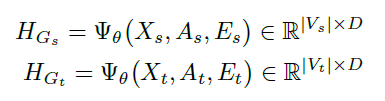
消息传递算法:1. AGGREGATE(聚合)、2. MERGE(合并)。经过k次迭代后,节点的特征表示向量\(h_v^{\left(k\right)}\)就可以捕获到图中k-hop邻域内的节点信息。
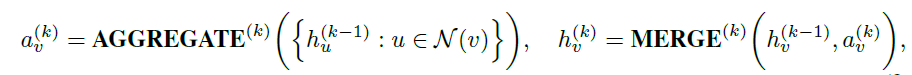
当进行图分类任务时,需要将点特征转化为全局特征;使用求和或者图池化的方法(READOUT函数),结合了最终迭代中的节点特征,从而获得整个图\(G_s\)或\(G_t\)的特征表示:
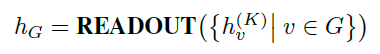
之后,为了将文本空间的特征投影到视觉空间,使用源图和目标图的向量局部节点表示\(H_{G_s}\)和\(H_{G_t}\),计算得到一个soft correspondence matrix \(\mathrm{\Phi}\)(相似性矩阵):
\[\mathrm{\Phi}=H_{G_s}{H_{G_t}}^T\in\ R^{|V_s|\times|V_t|} \]其中第i个行向量\(\mathrm{\Phi}_i\in\ R^{V_t}\)表示图\(G_t\)的节点和\(V_s\)中任意节点的潜在相似性关系的概率分布(可以视为用来衡量两个不同图中节点之间的匹配度的似然分数)。为了得到源节点特征和目标节点特征之间的离散相似性分布,将“sinkhorn normalization”(一种正则化方法)应用于相似性矩阵,以满足矩形双随机矩阵约束(对于\(\sum_{j\in V_t}\mathrm{\Phi}_{i,j}=1,\forall\ i\in\ V_s\ \ \ and\ \ \ \sum_{i\in V_s}\mathrm{\Phi}_{i,j}=1,\forall\ j\in\ V_t\))。
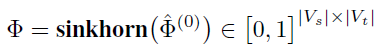
最后,给定\(\mathrm{\Phi}\),可以获取一个从源(文本)潜空间\(L(G_s)\)到目标(图像)潜空间\(L(G_t)\)的投影函数:
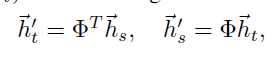
最终联合多模态表示\(h_{s,t}\)包括\([h_s,{\vec{h}}_s^\prime]\)的concat拼接操作,其中\({\vec{h}}_s^\prime\)是文本特征h_t到视觉空间上的投影。
Part2:下游任务
任务1:字幕分类任务
在这个任务中,给定一幅图像和一个标题,模型必须预测该图像上下文中的标题是真(T)还是假(F)。用来测试模型处理图像空间成分变化的能力。

图像来自CLEVR数据集[28],字幕使用模板生成正确和错误样例。为了衡量模型的泛化性能,在测试期间,交换对象属性值,并评估模型是否能够在不降低性能的情况下检测到新的属性值组成。
模型:
\(h_{s,t}\)可以被馈送到一个具有sigmoid激活函数的全连接层,以进行二分类分类0/1(匹配/不匹配)。
损失函数选择二元交叉熵损失函数:
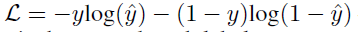
VQA任务:
CLOSURE数据集:基于CLEVR数据集生成,CLOSURE中的问题模板系统地使用原始语言构造,在生成的问题中创建看不见的组合。使用了七种不同的模板,针对五种广泛的CLEVR问题类型之一(计数、存在、数值比较、属性比较和查询)。

模型:
\(h_{s,t}\)被提供给一个基于注意力机制的seq2seq模型,该模型具有encoder-decoder结构。
使用双向LSTM[24]作为encoder。在时间步i,encoder接受一个具有padding的包括可变长度的单词token的问题\(q_i\),以及\(h_{s,t}\)作为输入:
之后使用双向LSTM进行编码:
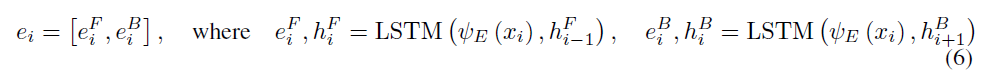
decoder是具有注意力机制的LSTM网络:利用前一个输出序列\(y_{t-1}\),经过LSTM网络产生向量\(o_t\),之后送入注意力层并获取加权后的encoder向量:
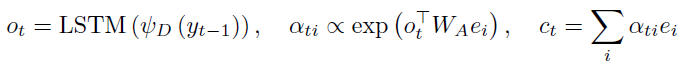
最后,decoder输出\(o_t\)和\(c_t\)被送到一个具有softmax激活的全连接层,以获得预测的符号序列\(y_t\)。\(y_t\)后续被用来回答VQA任务的问题。
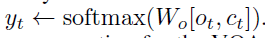
Task1:
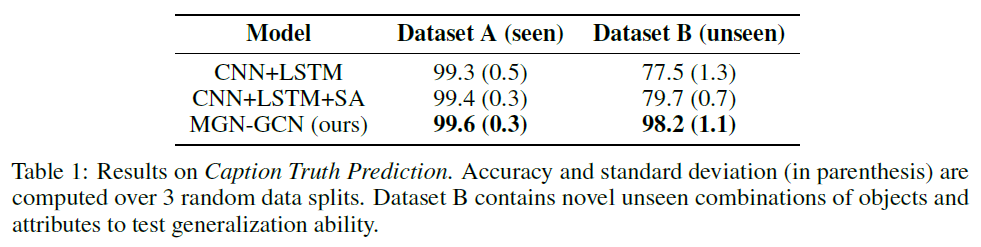
补充:数据集B包含新的看不见的对象和属性组合,以测试泛化能力。
Task2:
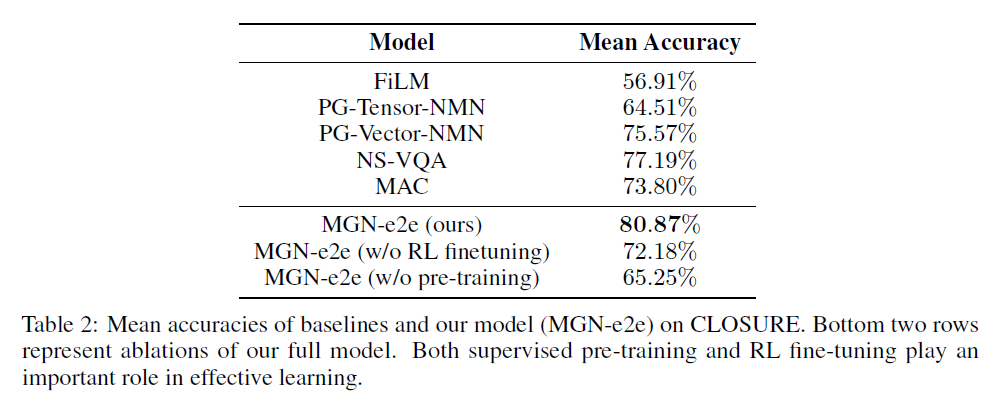
补充:有监督的预训练和微调在有效学习中都发挥着重要作用。
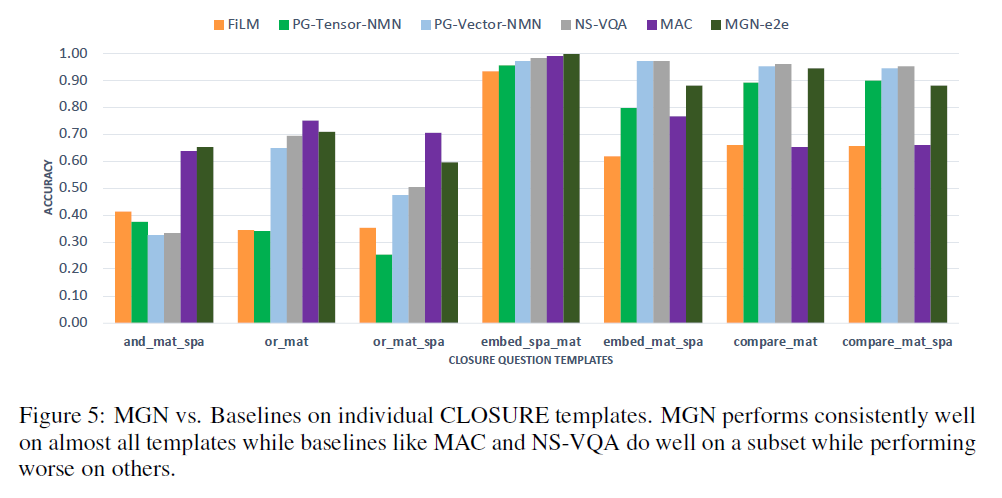
补充:MAC模型总体表现强劲,然而这些模型在逻辑关系上表现不佳(embed_mat_spa,compare _mat)。另一方面,MGN在所有7个模板中都表现良好。
四、存在的问题目前MGN模型主要训练的数据集还只是简单的图像组成的数据集,后续可以考虑如何扩展到更大更自然的图像数据集的挑战中。