首先要回答一个问题,为何要使用HBase? 随着业务不断发展、数据量不断增大,MySQL数据库存在这些问题: MySQL支持的数据量为TB级,不能一直保留历史数据。而HBase支持的数据量为PB级
首先要回答一个问题,为何要使用HBase?
随着业务不断发展、数据量不断增大,MySQL数据库存在这些问题:
- MySQL支持的数据量为TB级,不能一直保留历史数据。而HBase支持的数据量为PB级,适合存储久远的历史冷数据
- 新增列的代价较高,数据量越大耗费时间越长。而HBase可以随意增加列,空列不占据空间,业务模型可以灵活变化
要使用HBase,最重要的一点是rowkey行键设计,如果设计不妥,后续要改的代价非常大。
HBase行键设计原则下面列几个HBase rowkey设计的原则:
- 组合键:组合键是指拼接多个业务字段,如需查询,则业务字段必须作为rowKey的一部分
- 字段顺序:一对多,则一应该放在前面,以便能够scan得到结果,如用户id:订单id,如果反过来则无法得到用户下的所有订单
- 业务字段对齐长度:因为rowKey是按字典序排列的,所以需要对齐长度,比如id取12位,9位id前补齐3个0,否则就会出现123456789比654321比排在前面的问题。对齐长度后,000000654321排在000123456789之前,符合预期
- 打散以避免热点:id与时间有关,随时间递增,如果不做处理可能导致部分节点有读写热点,加上前缀可以打散,如取 业务id的后几位 % region个数 作为rowKey的前缀
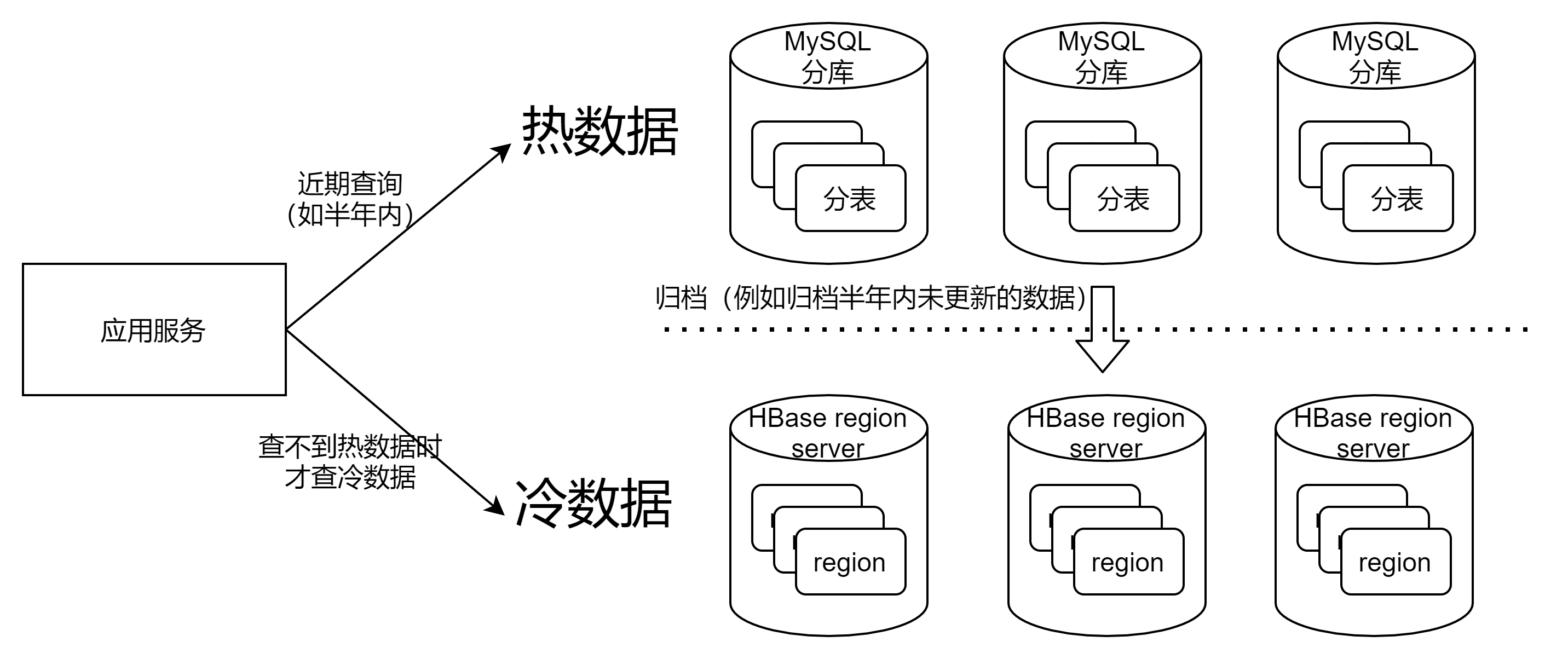
- HBase适合作为冷数据存储,存储和查询海量历史数据
- MySQL适合作为热存储存储,支持数据读写、事务操作
- 归档近期未更新的历史数据,新增数据至HBase,再删除MySQL记录
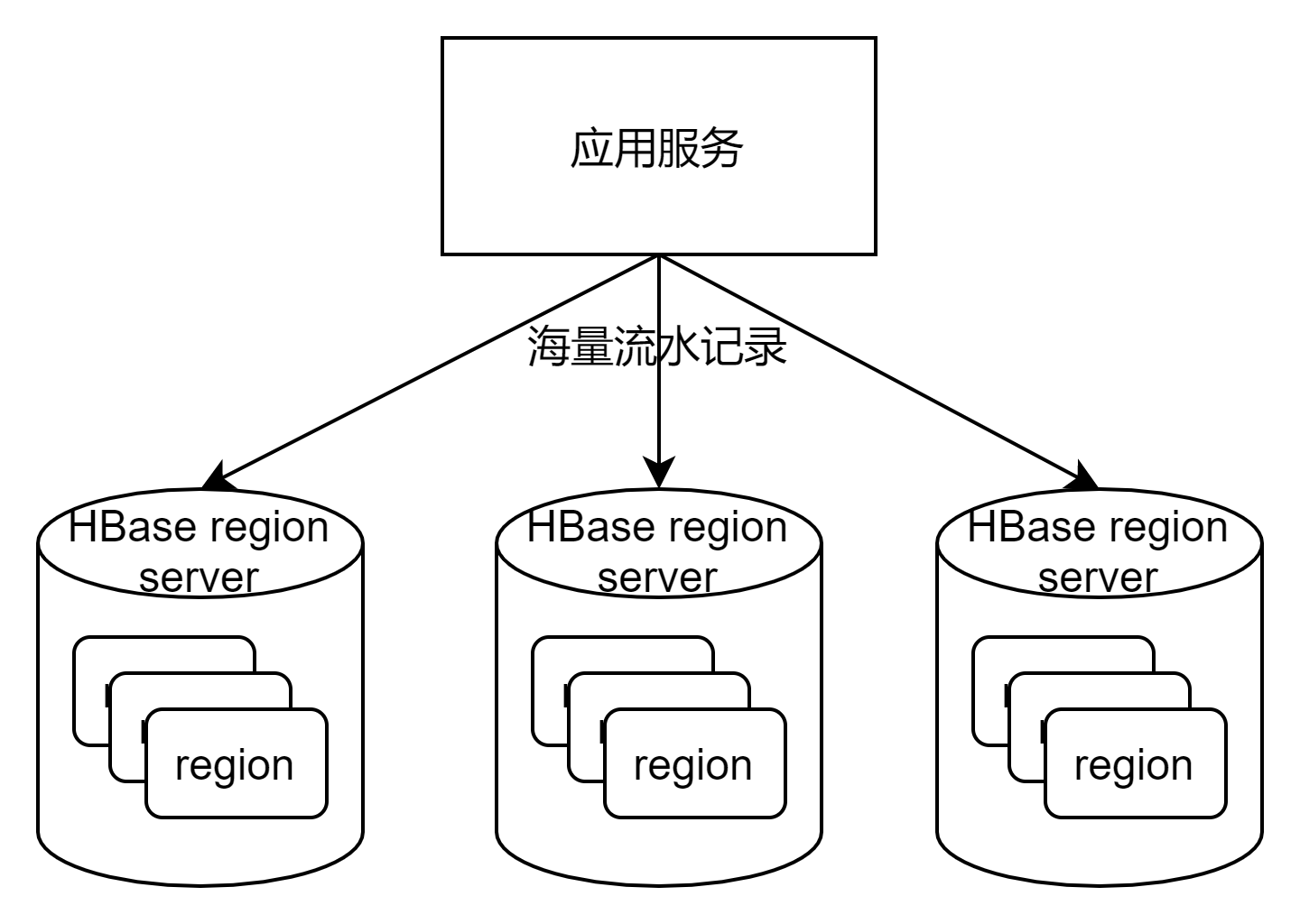
- 流水记录可随时新增字段
- 适合存储海量流水记录
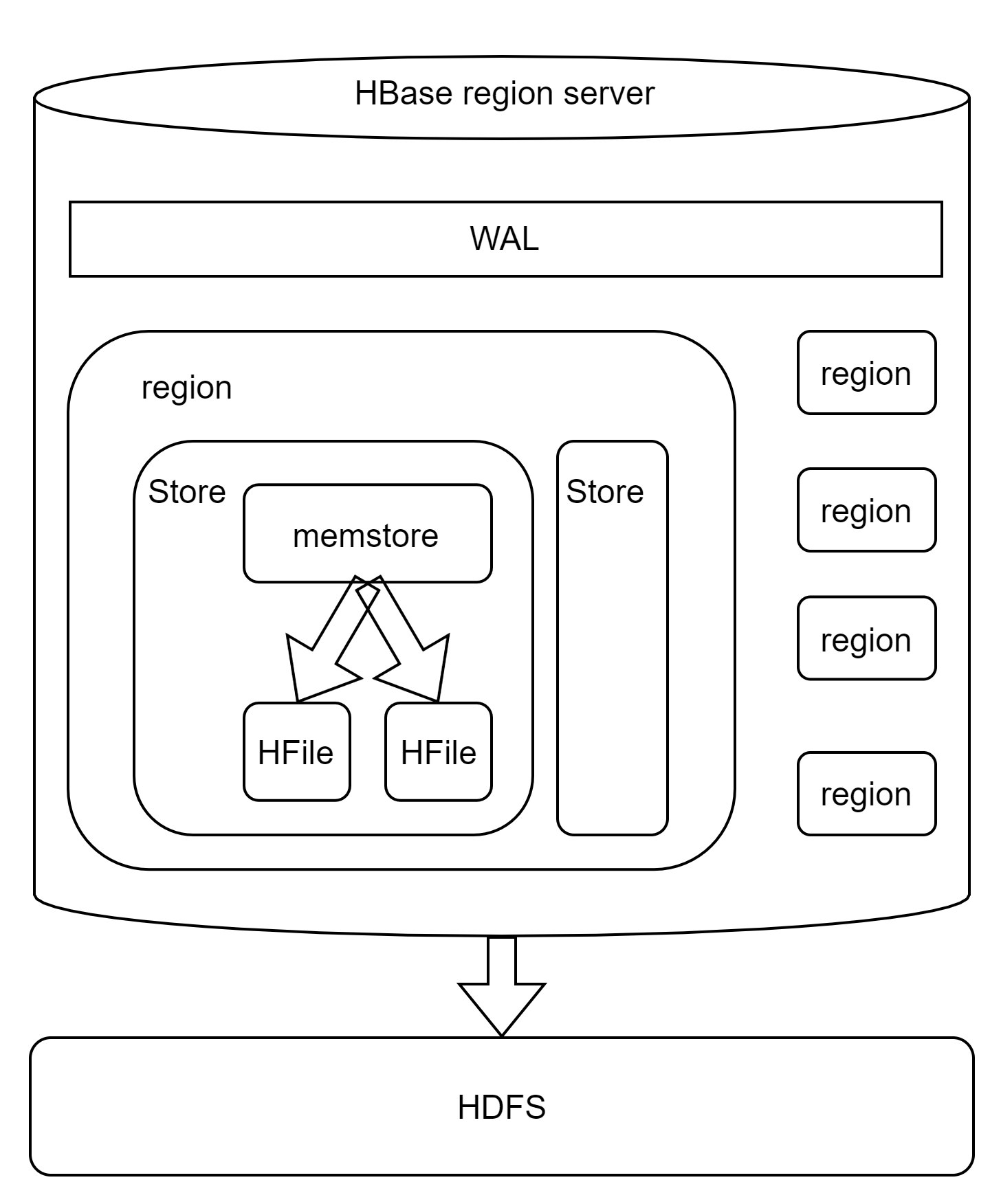
- region:所有行按rowkey字典序排列,region是其中一部分,相当于分片,每个region只能在一个region server上
- region server:可以包含一到多个region,调用HDFS的客户端接口对region所有数据进行读写操作
- WAL:预写日志,WAL是Write-Ahead Log的缩写。预先写入,WAL是一个保险机制,数据在写到Memstore之前,先被写到WAL了。这样当故障恢复的时候可以从WAL中恢复数据
- store:一个列族对应一个store,因此为了提高性能,不建议使用超过2个列族。一个store包含一个memstore和多个HFile
- memstore:数据写入WAL之后就会被放入memstore,主要用于在内存中对行做排序,排序完成后再写入HFile
- HFile:数据的存储实体,memstore写满后就会写入HFile
- region自动分片(split)、合并(merge):region大小达到阈值后,会自动分区,反之会做合并region的操作
- HFile合并(compaction):删除数据后会导致HFile变小,需要合并以减少HFile的数量,即减少碎片文件数量,提高寻址效率