
Pandas 是 Python 中用于高效处理数据的开源库,它的名字其实取自 Panel Data(面板数据),即多维数据的计量经济学。 在 Pandas 库出现以前,Python 也能用来处理数据,但其中对数据分析的支持相当有限。因此,Pandas 的出现弥补了原生 Python 的不足,促进了 Python 语言在装载、操作、准备、建模和分析数据上的能力。 由于 Pandas 建立于 NumPy 库之上,如果此前没有 NumPy 相关的基础知识,也欢迎先看看之前写过的 NumPy 教程文章: 【Python 核心库】Numpy 实景教程与练习
为什么使用 Pandas 处理数据?
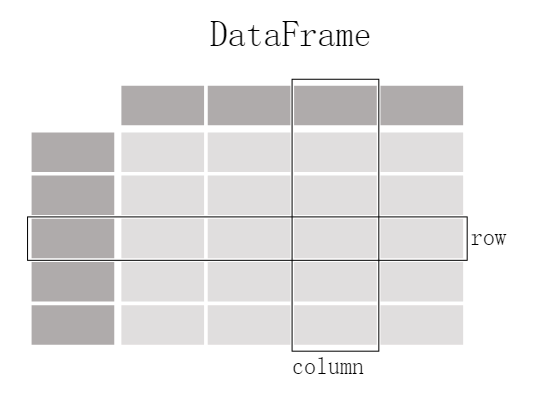
Pandas 之所以广泛应用于数据处理,是因为它的数据框架(DataFrame)和系列比其他的模块或框架拥有更具有可视性。Pandas 简明清晰的应用程序接口(API)也能让程序员更专注于代码的核心部分,使代码和数据都更简洁。
如何安装 Pandas?
使用 Pandas 进行编程首先需要在 Python 编辑器或 Python IDE 安装相应的模块。以教程中使用的 Lightly 为例,只需要在代码中直接写入 import pandas as pd,就可以通过 QuickFix 就可以一键安装。由于 Pandas 库经常需要运用 Numpy 相关的函数,引用 Pandas 的同时也可以一起通过 import numpy as np 引用 Numpy,更加方便。更多关于第三方模块的安装方式,可以查看如何手动下载和安装依赖。
Pandas 跟练项目:
在这篇 Pandas 跟练项目中,我们将制作一个简易的分数统计与查分程序。完成这个项目后,你可以学会如何:
- 将数据内容转换为表格
- 使用 Pandas 计算总分
- 顺序、逆序排列数据值
- 通过查找返回指定数据
- 删除及合并列表
完整学习此教程,可参考代码:https://d1590a0dfb-share.lightly.teamcode.com
将数据内容转换为表格
如果回看 Numpy 数组中的数据内容,我们其实可能会觉得这样的数据形式和惯用的行列式表格有所不同,观感上也没有那么清晰。
data = [[22053, '丁一', 1, 121, 132, 56, 167],
[22174, '刘二', 2, 150, 139, 115, 151],
[22124, '张三', 3, 74, 98, 68, 255],
[22021, '李四', 3, 105, 131, 137, 263],
[22006, '王五', 3, 70, 149, 84, 171],
[22271, '赵六', 2, 114, 96, 113, 284],
[22212, '孙七', 1, 146, 114, 149, 293],
[22070, '周八', 1, 122, 82, 118, 191],
[22288, '吴九', 2, 143, 111, 99, 258],
[22014, '郑十', 2, 110, 125, 104, 180]]
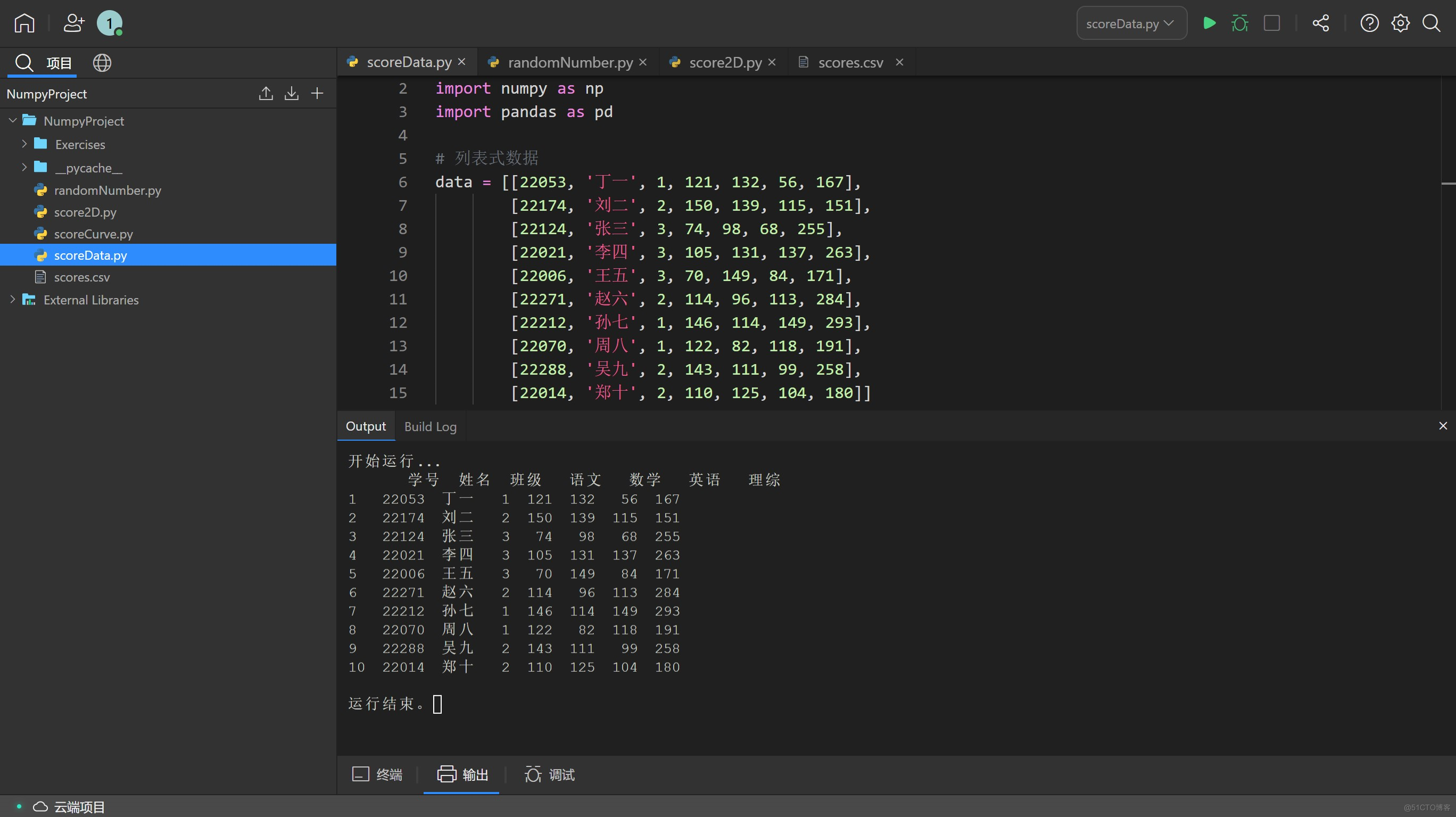
若用 Pandas 处理同一个或者更复杂的数据,那么他的输出效果便会更接近我们场景的表格,最终也能通过函数输出为 .csv 类型的表格文件,在 excel 等表格处理软件中打开。 按照以下代码添加列名和调整序列号,即可输出与表格十分相近的格式:
dataframe = pd.DataFrame(data, columns = ['学号', '姓名', '班级', '语文', '数学', '英语', '理综'])
dataframe.index += 1
print(dataframe)
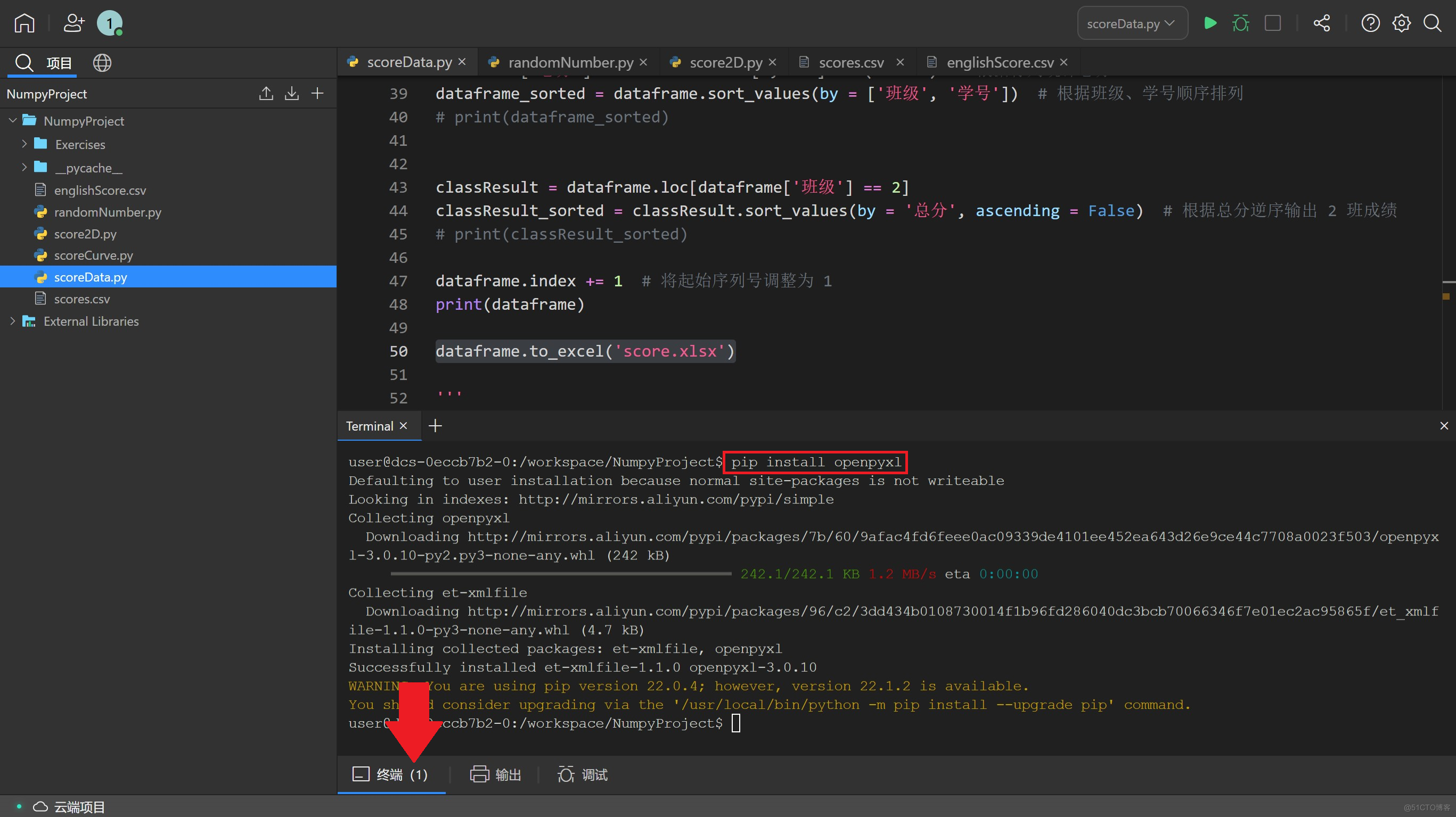
甚至在 pandas 中,只需要通过简单的一行代码即可输出为 .xlsx 格式的文件,直接在 Excel 中打开:dataframe.to_excel('score.xlsx')
如果运行后返回错误 no module named 'openpyxl',只需在终端通过 pip install openpyxl 安装相应的模块,重新运行即可。完成后的文件会出现在左侧的文件栏中,下载到本地即可通过 Excel 或其他表格软件打开。
Excel 中打开的效果:
使用 Pandas 计算总分
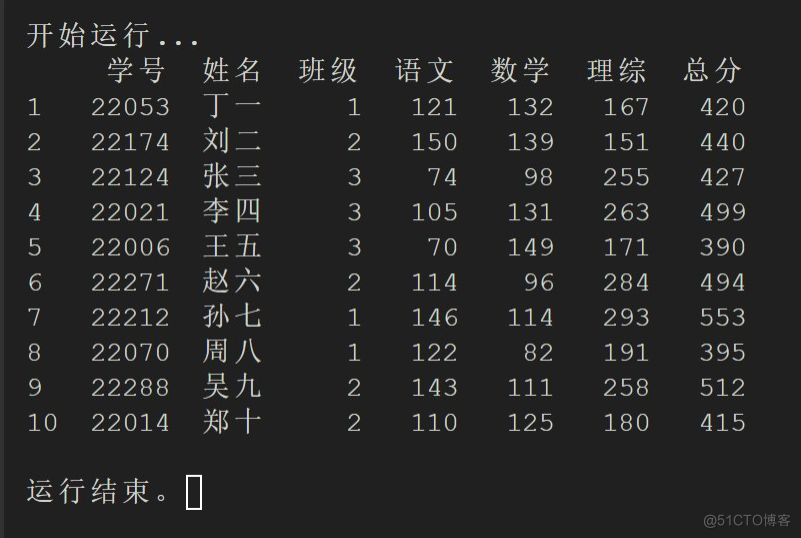
在原始的成绩数据中,我们只有语数英和理综的成绩,而还没有计算总分。虽然我们可以在已导出的 CSV 文件中,另外在 Excel 新添一栏计算总分,但 Python 中同样可以将这一程序以简单的一段代码完成:dataframe['总分'] = dataframe.iloc[:, 3:7].sum(axis=1)
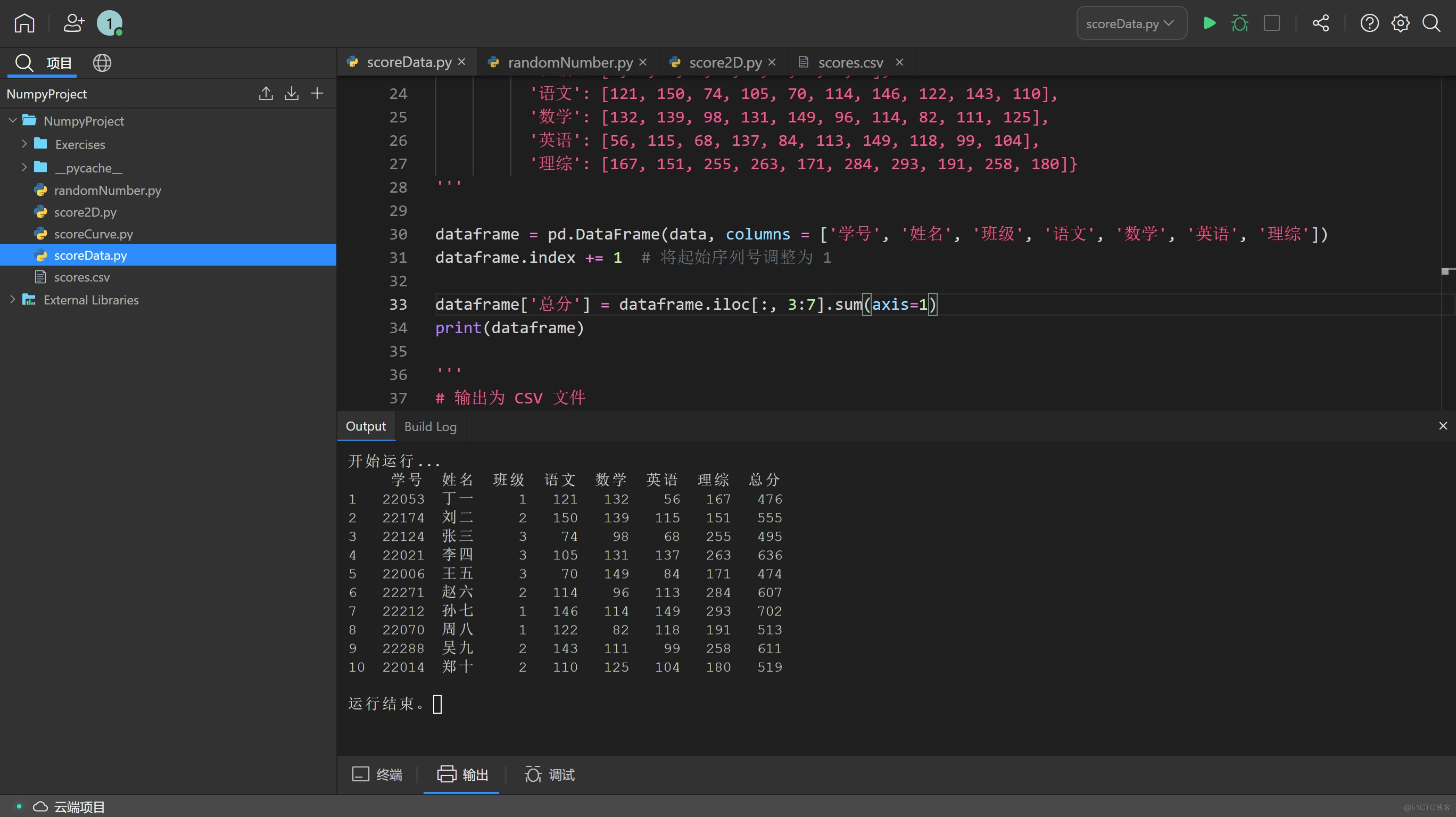
输出的中文数据不对齐,怎么办? 由于 Pandas 的初始字符宽度默认为英文,DataFrame 列名含有中文时,Pandas 就会出现列名和内容没有对齐的情况。我们只要把 Pandas 的两项默认设置为 True 即可:
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
根据学号顺序排列
在原始的成绩数据中,我们可以发现学号其实是乱序的,这或许不一定符合学校的格式要求。如果需要将成绩数据根据学号进行顺序排列,同样也只需要一行代码即可解决:dataframe_sorted = dataframe.sort_values(by = ['学号'])
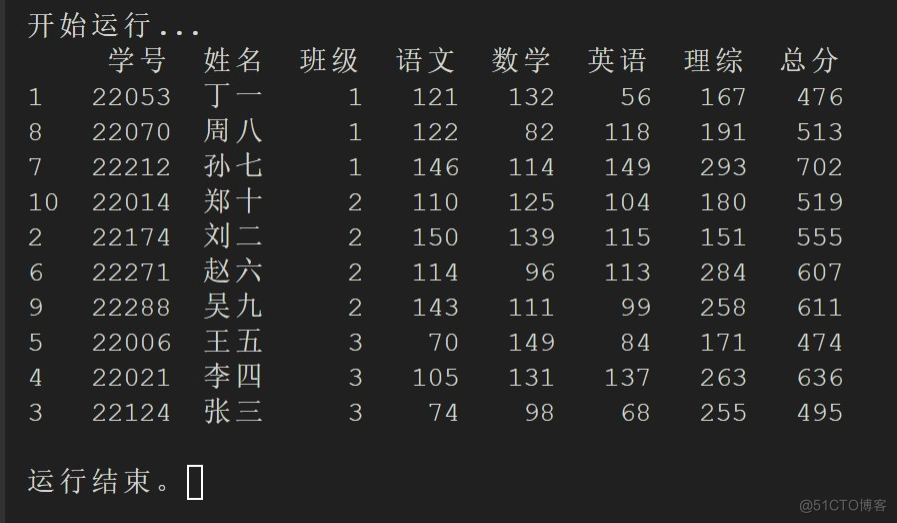
【小作业】尝试根据 dataframe.sort_values(),输出上图的排序效果。打开 scoreData.py 查看参考答案:https://d1590a0dfb-share.lightly.teamcode.com
返回个别班级的所有学生成绩
为了更方便地查看各班级的成绩,我们其实还可以通过dataframe.loc[] 函数查找并返回特定值的内容。以 2 班的成绩为例,我们只需要输入 classResult = dataframe.loc[dataframe['班级'] == 2] 即可返回仅有 2 班成绩的表格:
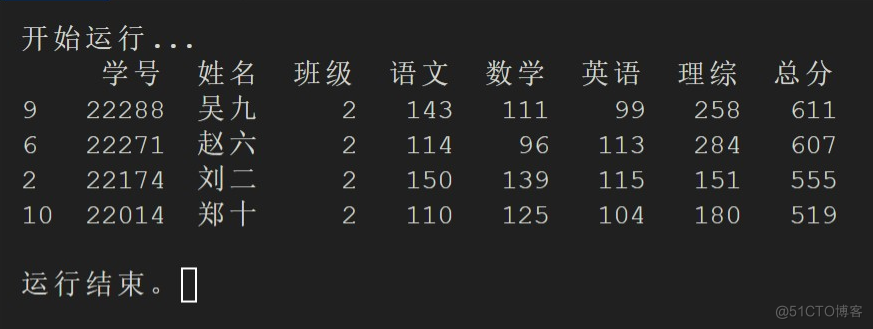
【小作业】尝试根据所学的内容,输出上图的以总分逆序排列的 2 班成绩。打开 scoreData.py 查看参考答案:https://d1590a0dfb-share.lightly.teamcode.com
删除和合并列表
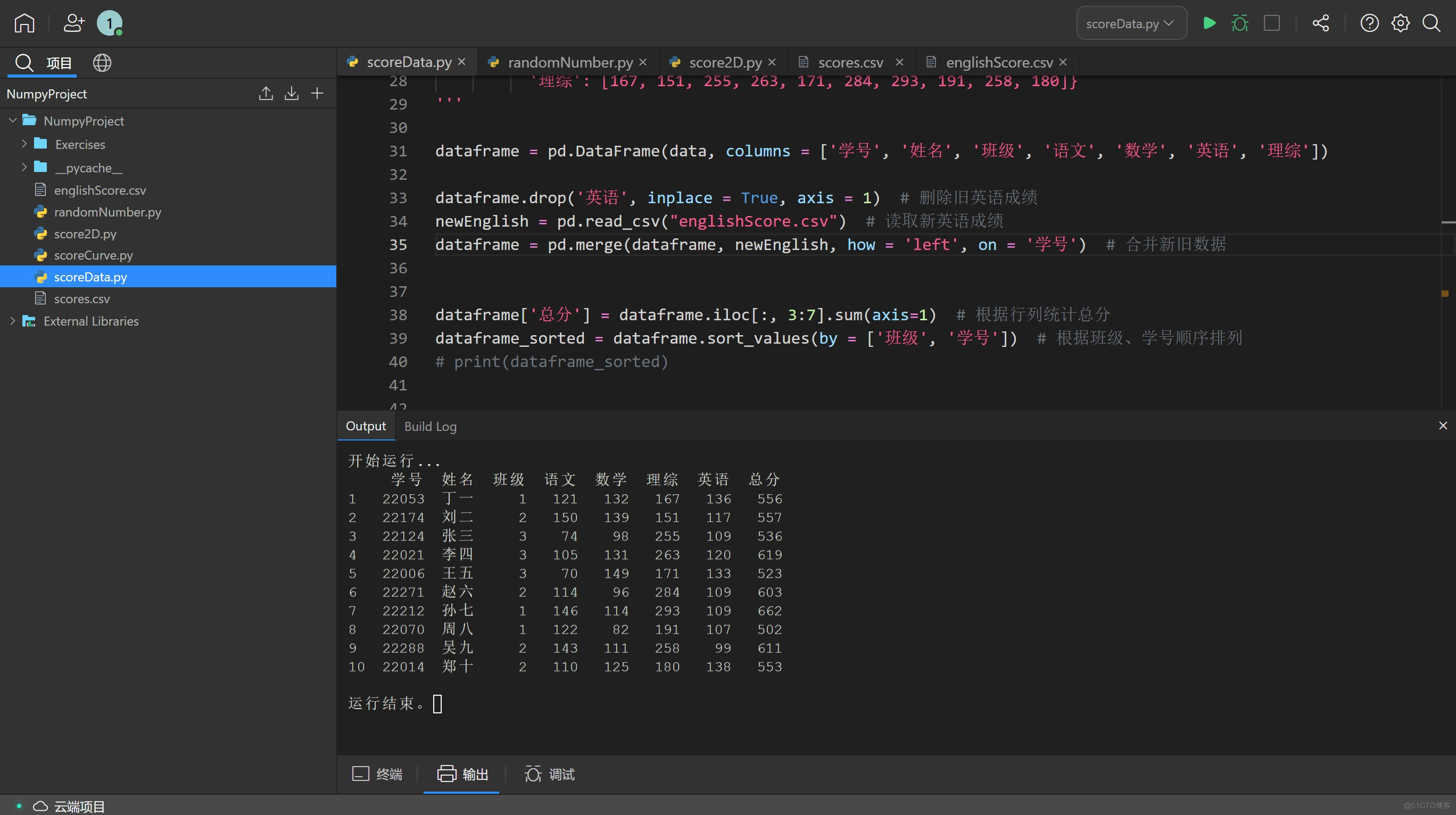
假设英语老师发现不小心给错了另一个年级的分数,希望将英语分数删掉再重新输入,应该怎么办呢?Pandas 中可以通过 pd.drop() 和 pd.merge() 两个函数删除和合并数据。
首先,使用 pd.drop() 将错误的行列删掉:df.drop('英语', inplace=True, axis=1)【注意】需要把这行代码放在总分 dataframe.iloc 函数前,否则总分依旧包含英语成绩。
英语老师随后给了新的分数,因为分数是根据学号盲改的,所以英语老师也给了含学号和学生成绩的 Excel 文件。上传后,我们可以通过以下代码读取并合并新旧数据:
newEnglish = pd.read_excel('englishScore.xlsx') # 读取新英语成绩
dataframe = pd.merge(dataframe, newEnglish, how = 'left', on = '学号') # 合并新旧数据
扩展作业
尝试结合 Python 编程的基本 input() 函数以及文章中的各个知识点,制作一个可以通过学号查找学生各学科成绩以及总分的简易程序。打开 scoreData.py 查看参考答案:https://d1590a0dfb-share.lightly.teamcode.com
恭喜你来到文章的尾声!在学习使用 Python 处理数据的时候,我其实思考过:明明已经有了现成的 Excel 办公软件,我们究竟为什么需要学习 Python 甚至编程?然而,在我学习 Python 的过程中,我发现:与广泛使用的第三方软件相比,我们可以通过编程定制更符合自身需求的程序,同时去掉不必要的繁琐内容,甚至还不必担心第三方软件随着时间的流逝,逐渐停运或无法满足我的特定需求。 随着编程越来越普及化,未来的计算机必备技能除了 Office 三件套甚至 PS、视频剪辑外,相信编程也会逐渐加入队列。对许多人而言,学习编程也许并非易事,但这种技能终究会像语文、数学、英语等过去我们曾学习的基础科目一样,成为我们的知识基础,帮助我们更好的理解现代科技的运作。