代码笔记,仅供参考,有错必纠,别买谢谢 限免:6小时 文章目录 任务 python代码 mysql数据库 任务 现在要对一堆PDF文档里的数据进行数据提取,规整并整理成
代码笔记,仅供参考,有错必纠,别买谢谢
限免:6小时
文章目录
- 任务
- python代码
- mysql数据库
任务
现在要对一堆PDF文档里的数据进行数据提取,规整并整理成一个完整的数据表。
PDF里的数据的格式是这样的(由于数据不可外泄,所以我进行马赛克处理,只保留部分数据):
 )
)
上面显示的表格是我们需要的数据,当然,这个PDF文档中还有很多我们不需要的干扰数据,所以,我用正则表达式去匹配我需要的数据,并添加了一些条件,禁止干扰数据进入我们最后的数据表中。
这些PDF文档的名字很规整,方便我们处理,我们可以利用PDF名称的信息对从提取到的数据进行归类:
 )
)
这些PDF文件里的数据分别在2011年、2013年、2015年、2017年和2019年记录的,所以分别放在下面这5个文件夹里:
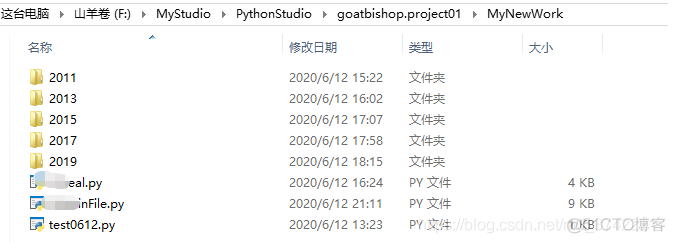 )
)
因为我现在还真不知道有什么直接读PDF的手段,也不会把PDF转成txt或者其他格式的技术,所以这里自己手动复制到Excel中,再转成csv文件了,转成csv方便我们读取(之前倒是试了试用CAJViewer把PDF转成txt,但是效果不是我想要的那样):
 )
)
最后,我们需要提取到PDF中result, reaction,DATE of BIRTH,Fn四个变量,并且将数据记录的年份(比如2019年)和数据分类信息记录在同一个表中,并导入mysql中,由此,我创建了一个mysql数据表:
CREATE TABLE RunData(id int(11) primary key auto_increment,PersonDATE date,
RESULT float(4,2),
REACTION float(4,3),
FN int,
CompetitionType varchar(20),
ProjectClass varchar(20),
RunYear YEAR);
python代码
下面是python代码:
# -*- coding: utf-8 -*-import re
import datetime
import os
from pandas import DataFrame
import pandas as pd
import pymysql
class EiDealData:
def __init__(self):
self.path = r"F:\MyStudio\PythonStudio\goatbishop.project01\MyNewWork"
self.RunData = {}
self.countFileNun = 0
self.count1 = 0
self.count2 = 0
self.filter1 = 0
self.filter2 = 0
self.db = pymysql.connect(host = '127.0.0.1',
port = 3306,
user = 'root',
password = '19970928',
database = 'datacup',
charset = 'utf8')
self.cur = self.db.cursor()
def GetFile(self):
fileName = os.listdir(self.path)
self.GetFormatData(fileName)
def GetFormatData(self, fileName):
for item in fileName:
if os.path.isdir(item):
path = self.path + "\\" + item
fileName2 = os.listdir(path)
for file in fileName2:
if file.endswith(".csv"):
self.countFileNun +=1
#print(file)
#判断后缀
fNameDeal = re.split("\W+", file)
#print(fNameDeal)
sonDictName = "R_"+ "".join(fNameDeal[0:(len(fNameDeal)- 1)])
self.RunData[sonDictName] = {}
self.RunData[sonDictName]["REACTION"] = []
self.RunData[sonDictName]["RESULT"] = []
self.RunData[sonDictName]["DATE"] = []
self.RunData[sonDictName]["FN"] = [] #0为没有犯规,1为犯规
ReadFilePath = path + "\\" + file
with open(ReadFilePath, 'r') as f:
data = f.readline()
#print(data)
while (data):
start_char = data[0]
#flag1 = re.findall(r"\+|\(|\)", data)
#print(flag1)
flag2 = len(re.split("\W", data))
#print(flag2)
if ((ord(start_char) >= 49) & (ord(start_char) <= 57)
& (len(data) >= 16) & (flag2 >= 9)):
self.count1 +=1
#ord("a")为计算"a"的ASCII码值
pattern0 = r"\b\d{1,2}\.\d{2}\b"
pattern1 = r"\b\d\.\d{3}\b"
pattern2 = r"\d{1,2} [A-Z][a-zA-Z]{2} \d{2}\b"
result = re.findall(pattern0, data)
reaction = re.findall(pattern1, data)
if result:
result = float(result[0])
else:
temp = re.findall(r"DNF|DQ|DNS", data)
if temp:
if temp[0] == "DNF":
result = -1
elif temp[0] == "DQ":
result = -2
elif temp[0] == "DNS":
result = -3
else:
#print(temp)
#print(data)
result = -4
if reaction:
reaction = float(reaction[0])
else:
data = f.readline()
self.filter1 +=1
continue
try:
date = re.findall(pattern2, data)[0]
except Exception as e:
print("匹配异常,可能是原始数据不规整")
deal_date = "2020-01-01"
else:
deal_date = datetime.datetime.strptime(date,'%d %b %y').strftime('%Y-%m-%d')
#print(date)
fn = re.findall(r"\bF\b|\bF1\b", data)
#print(fn)
if fn:
fn = 1
else:
fn = 0
self.RunData[sonDictName]["RESULT"].append(result)
self.RunData[sonDictName]["REACTION"].append(reaction)
self.RunData[sonDictName]["DATE"].append(deal_date)
self.RunData[sonDictName]["FN"].append(fn)
data = f.readline()
print(item, self.countFileNun)
self.countFileNun = 0
self.writeMysql(item)
self.RunData = {}
def writeCsv(self):
pass
def writeMysql(self, RunYear):
dataDealed = self.RunData
for key in dataDealed:
#print(key)
CompetitionType = re.findall(r"n(Final)|(Round1)|(SemiFinal)|(Preliminary)", key)[0]
CompetitionType = "".join(CompetitionType)
ProjectClass = re.findall(r"\d{3}|hurdles", key)
ProjectClass = "".join(ProjectClass)
#print(len(dataDealed[key]["DATE"]))
self.count2 += len(dataDealed[key]["DATE"])
ProjectClassL = [ProjectClass]*len(dataDealed[key]["DATE"])
#CompetitionType = "".join(cp_list)
#print(CompetitionType)
CompetitionTypeL = [CompetitionType]*len(dataDealed[key]["DATE"])
RunYearL = [RunYear]*len(dataDealed[key]["DATE"])
tempData = zip(dataDealed[key]["DATE"], dataDealed[key]["RESULT"],
dataDealed[key]["REACTION"], dataDealed[key]["FN"],
CompetitionTypeL,ProjectClassL,RunYearL)
for item in tempData:
#print(item)
try:
sql = 'insert into RunData(PersonDATE,RESULT,REACTION,FN,CompetitionType,ProjectClass,RunYear) \
values(%s, %s, %s, %s, %s, %s, %s);'
self.cur.execute(sql, item)
self.db.commit()
print("提交成功...")
except Exception as e:
self.db.rollback()
print("错误信息:", e)
def main(self):
self.GetFile()
#self.writeMysql()
self.cur.close()
self.db.close()
if __name__ == "__main__":
eiDeal = EiDealData()
eiDeal.main()
print("进入规则内个数:",eiDeal.count1)
print("实际导入sql个数",eiDeal.count2)
print("过滤掉数据个数:",eiDeal.filter1)
部分输出:
提交成功...提交成功...
提交成功...
进入规则内个数: 4051
实际导入sql个数 2463
过滤掉数据个数: 1588
mysql数据库
现在,我们看看mysql中是否导入2463条数据。
sql语言:
select * from RunData limit 3000;输出:
18:17:36 select * from RunData limit 3000 2463 row(s) returned 0.000 sec / 0.015 sec可以看到,我们已经收集到了2363条数据,现在我们查询result=-2的记录:
SELECT * FROM RunData WHERE result=-2;输出:
21:31:00 SELECT * FROM RunData WHERE result=-2 LIMIT 0, 1000 19 row(s) returned 0.000 sec / 0.000 sec可以看到查询到19条记录。