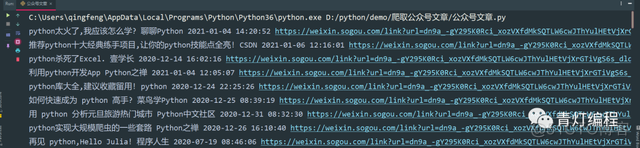
前言 本文的文字及图片过滤网络,可以学习,交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。 基本开发环境 Python 3.6 皮查姆 爬取两个公众号的文章: 1,爬取青
前言
本文的文字及图片过滤网络,可以学习,交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
基本开发环境
- Python 3.6
- 皮查姆
爬取两个公众号的文章:
1,爬取青灯编程公众号所有的文章
2,爬取所有关于python的公众号文章
爬取青灯编程公众号所有的文章
1,登陆公众号之后点击图文
2,打开开发者工具
3,点击超链接
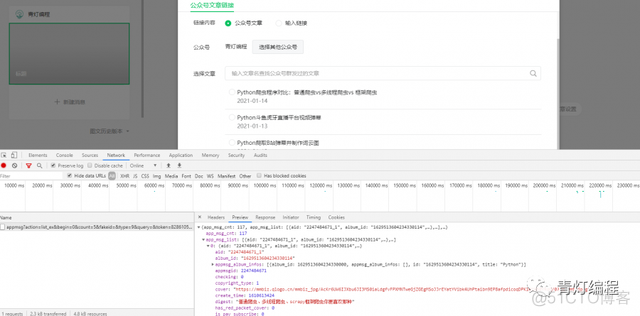
相关的数据加载出来,就有关于数据包,包含了文章标题,链接,摘要,发布时间等等,也可以选择其他的公众号也可以爬取的,但是这需要你有一个微信公众号。
要加cookie
import pprintimport time
import requests
import csv
f = open('青灯公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(0, 40, 5):
url = f'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={page}&count=5&fakeid=&type=9&query=&token=1252678642&lang=zh_CN&f=json&ajax=1'
headers = {
'cookie': '加cookie',
'referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&createType=0&token=1252678642&lang=zh_CN',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = response.json()
pprint.pprint(response.json())
lis = html_data['app_msg_list']
for li in lis:
title = li['title']
link_url = li['link']
update_time = li['update_time']
timeArray = time.localtime(int(update_time))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title,
'文章发布时间': otherStyleTime,
'文章地址': link_url,
}
csv_writer.writerow(dit)
print(dit)
爬取所有关于python的公众号文章
1,搜狗搜索python选择微信
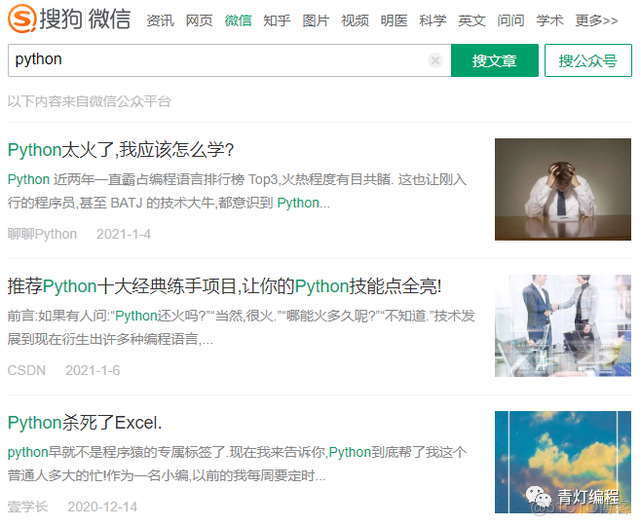
注意:如果不登陆只能爬取前十页数据,登陆之后可以爬取2W多篇文章。
2,爬取标题,公众号,文章地址,发布时间静态网页直接爬取即可
import timeimport requests
import parsel
import csv
f = open('公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '公众号', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(1, 2447):
url = f'https://weixin.sogou.com/weixin?query=python&_sug_type_=&s_from=input&_sug_=n&type=2&page={page}&ie=utf8'
headers = {
'Cookie': '自己的cookie',
'Host': 'weixin.sogou.com',
'Referer': 'https://www.sogou.com/web?query=python&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=1396&sst0=1610779538290&lkt=0%2C0%2C0&sugsuv=1590216228113568&sugtime=1610779538290',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
lis = selector.css('.news-list li')
for li in lis:
title_list = li.css('.txt-box h3 a::text').getall()
num = len(title_list)
if num == 1:
title_str = 'python' + title_list[0]
else:
title_str = 'python'.join(title_list)
href = li.css('.txt-box h3 a::attr(href)').get()
article_url = 'https://weixin.sogou.com' + href
name = li.css('.s-p a::text').get()
date = li.css('.s-p::attr(t)').get()
timeArray = time.localtime(int(date))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title_str,
'公众号': name,
'文章发布时间': otherStyleTime,
'文章地址': article_url,
}
csv_writer.writerow(dit)
print(title_str, name, otherStyleTime, article_url)