1 简介 随着互联网和物联网技术的发展,数据的收集变得越发容易.但是,高维数据中包含了很多冗余和不相关的特征,直接使用会徒增模型的计算量,甚至会降低模型的表现性能,故很有必要
1 简介
随着互联网和物联网技术的发展,数据的收集变得越发容易.但是,高维数据中包含了很多冗余和不相关的特征,直接使用会徒增模型的计算量,甚至会降低模型的表现性能,故很有必要对高维数据进行降维处理.特征选择可以通过减少特征维度来降低计算开销和去除冗余特征,以提高机器学习模型的性能,并保留了数据的原始特征,具有良好的可解释性.特征选择已经成为机器学习领域中重要的数据预处理步骤之一.针对上述问题,文中提出了一种基于鲸鱼优化算法的特征选择方法,通过不断迭代找到可接受的近似最优特征子集.在UCI数据集上的实验结果表明,当以支持向量机为评价所用的分类器时,文中提出的算法能找到具有较少信息损失的特征子集,且具有较高的分类精度.因此,所提算法在特征选择方面具有一定的优势.




2 部分代码
function Acc = jKNN(feat,label,HO)%---// Parameter setting for k-value of KNN //
k=5;
xtrain = feat(HO.training==1,:); ytrain = label(HO.training==1);
xvalid = feat(HO.test==1,:); yvalid = label(HO.test==1);
Model = fitcknn(xtrain,ytrain,'NumNeighbors',k);
ypred = predict(Model,xvalid);
num_valid = length(yvalid);
correct = 0;
for i = 1:num_valid
if isequal(yvalid(i),ypred(i))
correct = correct + 1;
end
end
Acc = 100 * (correct / num_valid);
end
3 仿真结果
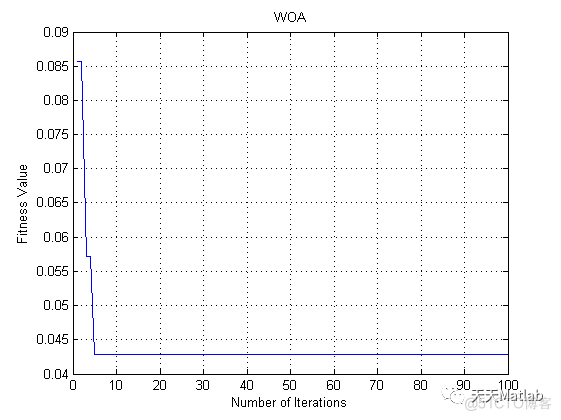
4 参考文献
[1]王生武, 陈红梅. 基于粗糙集和改进鲸鱼优化算法的特征选择方法[J]. 计算机科学, 2020(2):44-50.
博主简介:擅长智能优化算法、神经网络预测、信号处理、元胞自动机、图像处理、路径规划、无人机等多种领域的Matlab仿真,相关matlab代码问题可私信交流。
部分理论引用网络文献,若有侵权联系博主删除。
