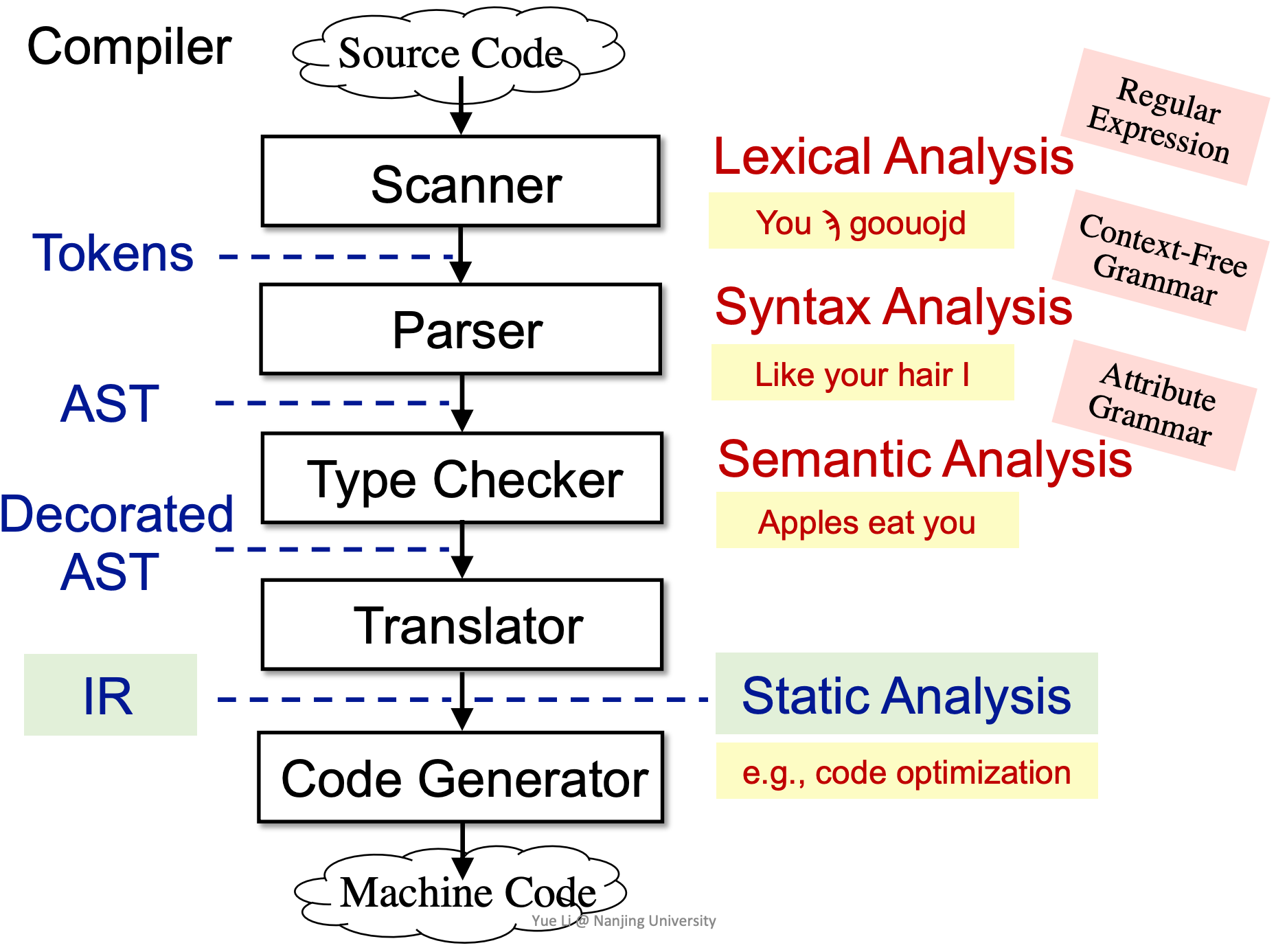
编译器将源代码(Source code) 转换为机器代码(Machine Code)。其中的流程框架是:
- 词法分析器(Scanner):通过词法分析(Lexical Analysis)将 source code 翻译为 token
- 分词(结合正则表达式)
- 判断词是否合法(是否符合编码规范)
- 语法分析器(Parser):通过语法分析(Syntax Analysis),将 token 解析为抽象语法树(Abstract Syntax Tree, AST)
- 结合上下文无关文法(Context-Free Grammar)进行分析,无关分析已经足够,不需要NLP处理上下文。例子:主谓宾都包含,但顺序不一定对。
- 语义分析器(Type Checker):通过语义分析(Semantic Analysis),将 AST 解析为 decorated AST
- 结合属性文法(Attribute Grammar)进行type checker
- Translator,将 decorated AST 翻译为生成三地址码这样的中间表示形式(Intermediate Representation, IR),并基于 IR 做静态分析(例如代码优化这样的工作)
- Code Generator,将 IR 转换为机器代码
为什么不直接拿 source code 做静态分析?
这是因为我们得先确保这是一份合格的代码,然后再进行分析。分析代码合不合格,这是 trivial 的事情,由前面的各种分析器去做就行了,我们要做的是 non-trivial 的事情。
二、AST vs. IR
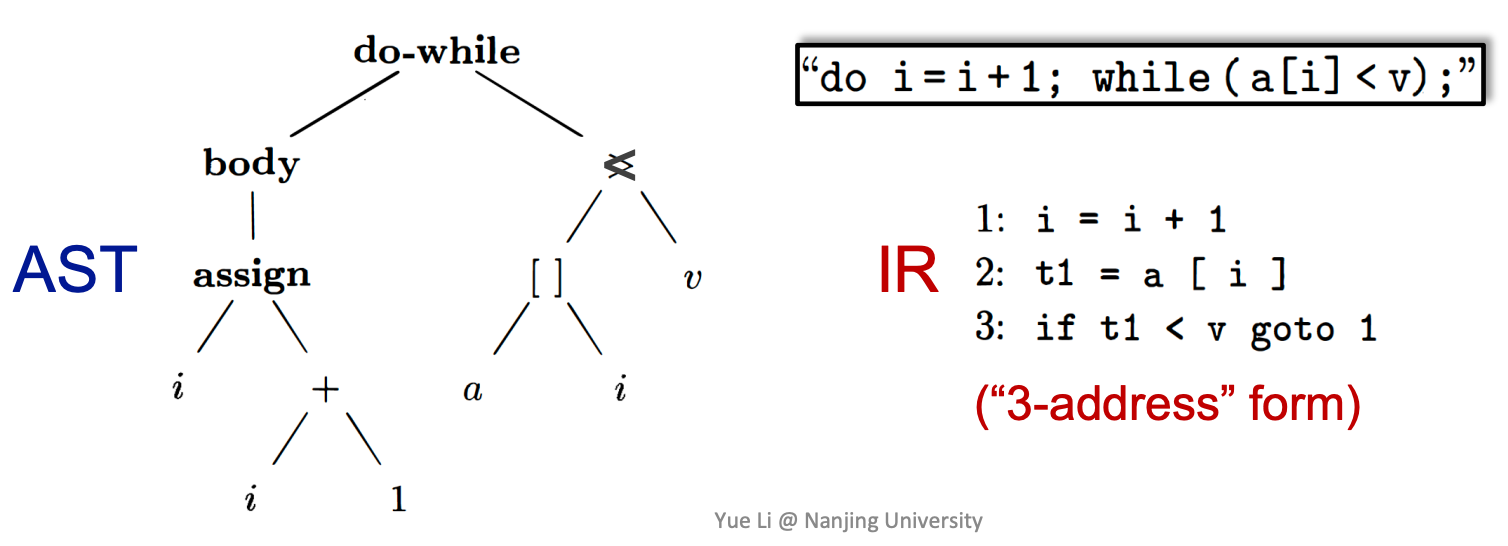
为什么在静态分析的时候,使用 IR 而非 AST 呢?
- AST
- AST 是 high-level 且接近语法结构的
- AST 是依赖于具体语言的
- AST 适合快速类型检查
- AST 缺少控制流信息
- IR
- IR 是 low-level 且接近机器代码的
- IR 通常是独立于语言的:三地址码会被分析器重点关注,因为可以将各种前端语言统一翻译成同一种 IR 再加以优化
- IR 的结构更加紧凑和统一:在 AST 中包含了很多非终结符所占用的结点(body,assign 等),而 IR 中不会需要到这些信息
- IR 包含了控制流信息:AST 中只是有结点表明了这是一个 do-while 结构,但是无法看出控制流信息;而 IR 中的 goto 等信息可以轻易看出控制流。因此 IR 更适合作为静态分析的基础。
三、IR: Three-Address Code (3AC)
IR: Three-Address Code通常没有统一的格式,每种语言的编译器都会有自己特定的三地址码格式。
所谓三地址码,最基本的特征就是:在每个指令的右边至多有一个操作符。

每个三地址码指令,都可以被分解为一个四元组(4-tuple)的形式:(运算符,操作数1,操作数2,结果),即一个运算符+3个「地址」,而一个「地址」可以是:
- 名称 Name: a, b
- 常量 Constant: 3
- 编译器生成的临时变量 Compiler-generated Temporary: t1, t2
常见的 3AC 包括:
- x = y bop z:双目运算并赋值,bop = binary operator
- x = uop z:单目运算并赋值,uop = unary operator
- x = y:直接赋值
- goto L:无条件跳转,L = label
- if x goto L:条件跳转
- if x rop y goto L:包含了关系运算的条件跳转,rop = relational operator
四、3AC in Real Static Analyzer
Soot 是 Java 的静态分析框架,其中的 IR 叫做 Jimple。
五、Static Single Assignment (SSA)
所谓静态单赋值(SSA),就是让每次对变量x赋值都重新使用一个新的变量xi,并在后续使用中选择最新的变量。
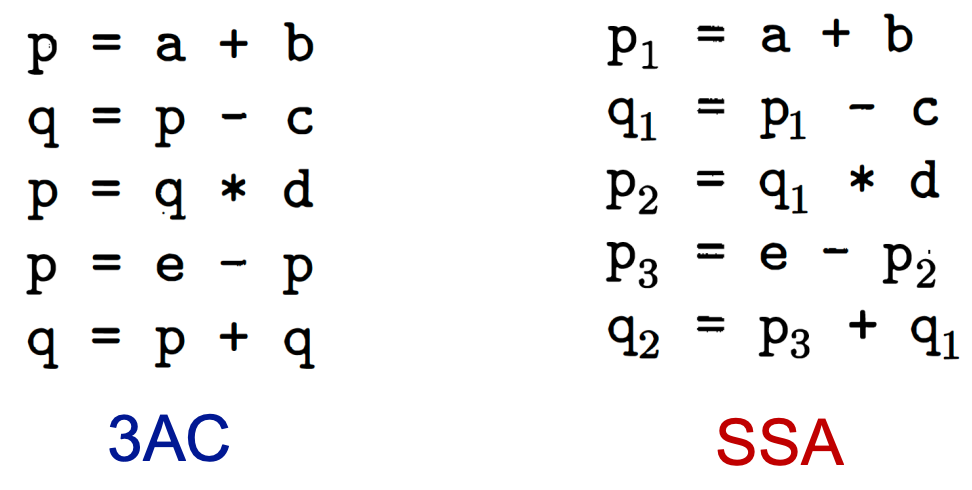
但是这样一来,肯定会因为不同控制流汇入到一个块,导致多个变量备选的问题:
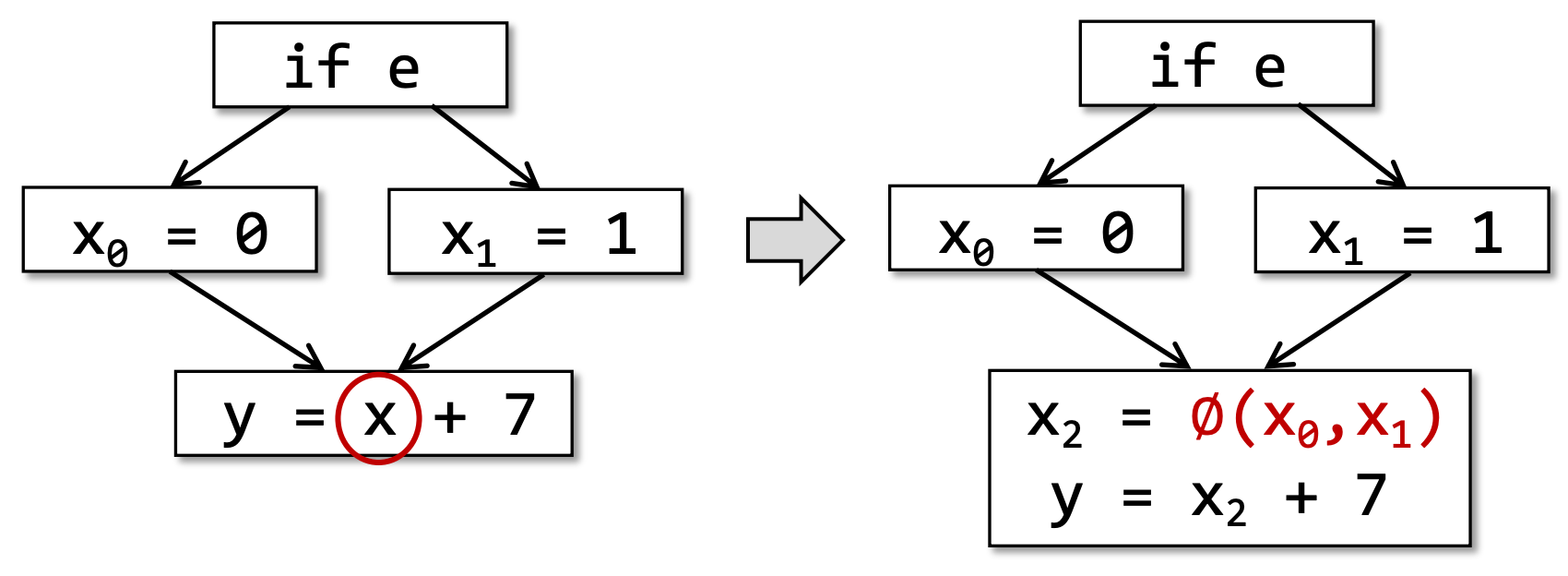
- A special merge operator, Ø(called phi-function), is introduced to select the values at merge nodes
- Ø(x0,x1)has the value x0 if the control flow passes through the true part of the conditional and the value x1 otherwise
为什么要用 SSA 呢?
- 控制流信息间接地集成到了独特变量名中,如果有些对控制流不敏感的简化分析,就可以借助于 SSA
- 定义与使用是显式的,更有效率的数据存取与传播,有些优化在基于 SSA 时效果更好(例如条件常量传播,全局变量编号等)
为什么不用 SSA 呢?
- SSA 会引入过多的变量和 phi 函数
- 在转换成机器代码时会引入低效率的问题
fi函数实际上把条件分支等情况下的信息抹除了,这样并不能满足污点分析,SSA实际上是上下文无关的。
六、Basic Blocks (BB)
所谓基本块,就是满足以下性质的连续 3AC:
- 只能从块的第一条指令进入
- 只能从块的最后一条指令离开
- 最长3AC序列

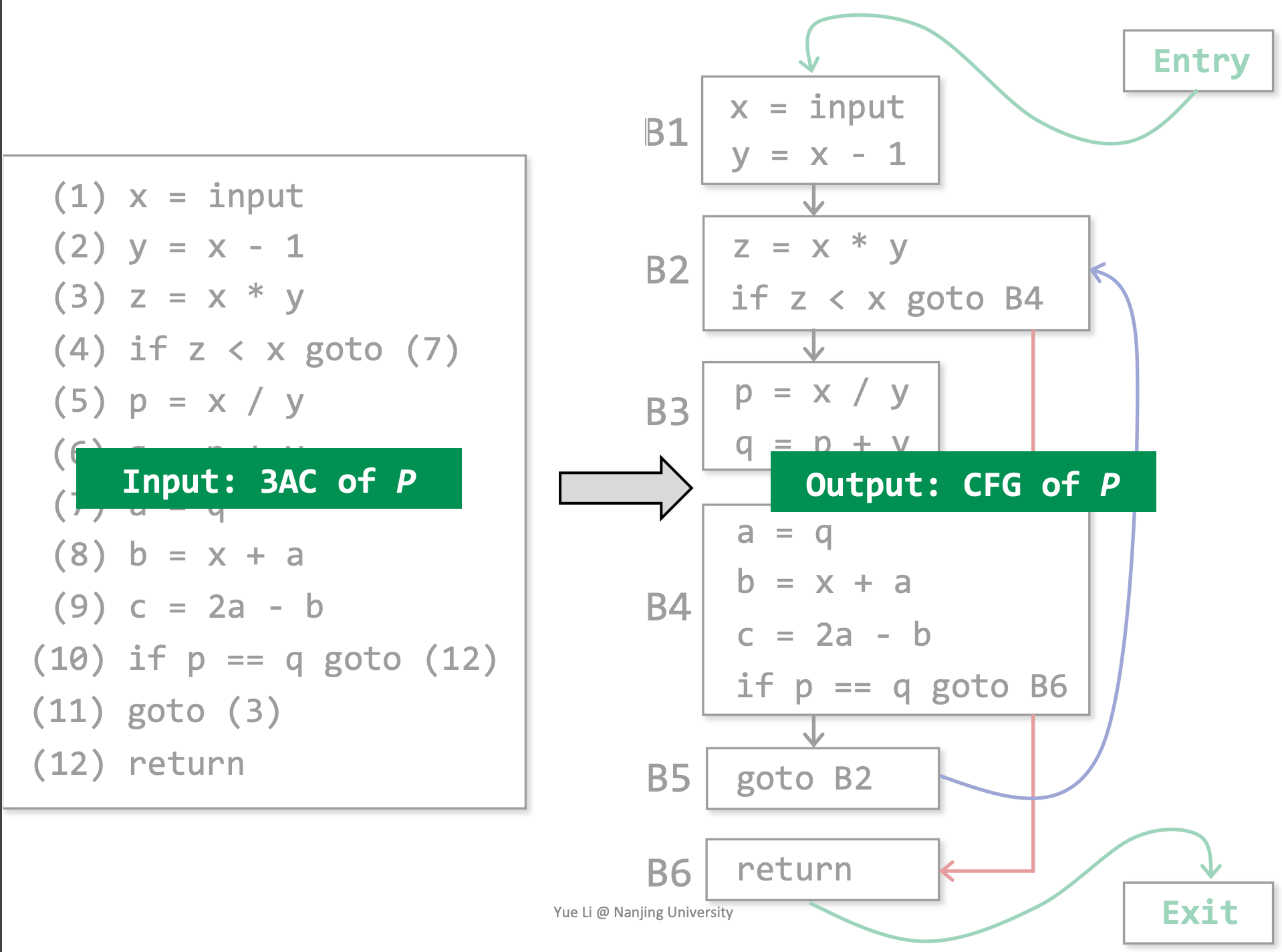
如何构建一个基本块呢?
- 输入:程序 P 的一系列 3AC
- 输出:程序 P 的基本块
- 方法
- 1、决定 P 的 leaders
- P 的第一条指令就是一个 leader
- 跳转的目标指令是一个 leader
- 跳转指令的后一条指令,也是一个 leader
- 2、构建 P 的基本块
- 一个基本块就是一个 leader 及其后续直到下一个 leader 前的所有指令。
- 1、决定 P 的 leaders


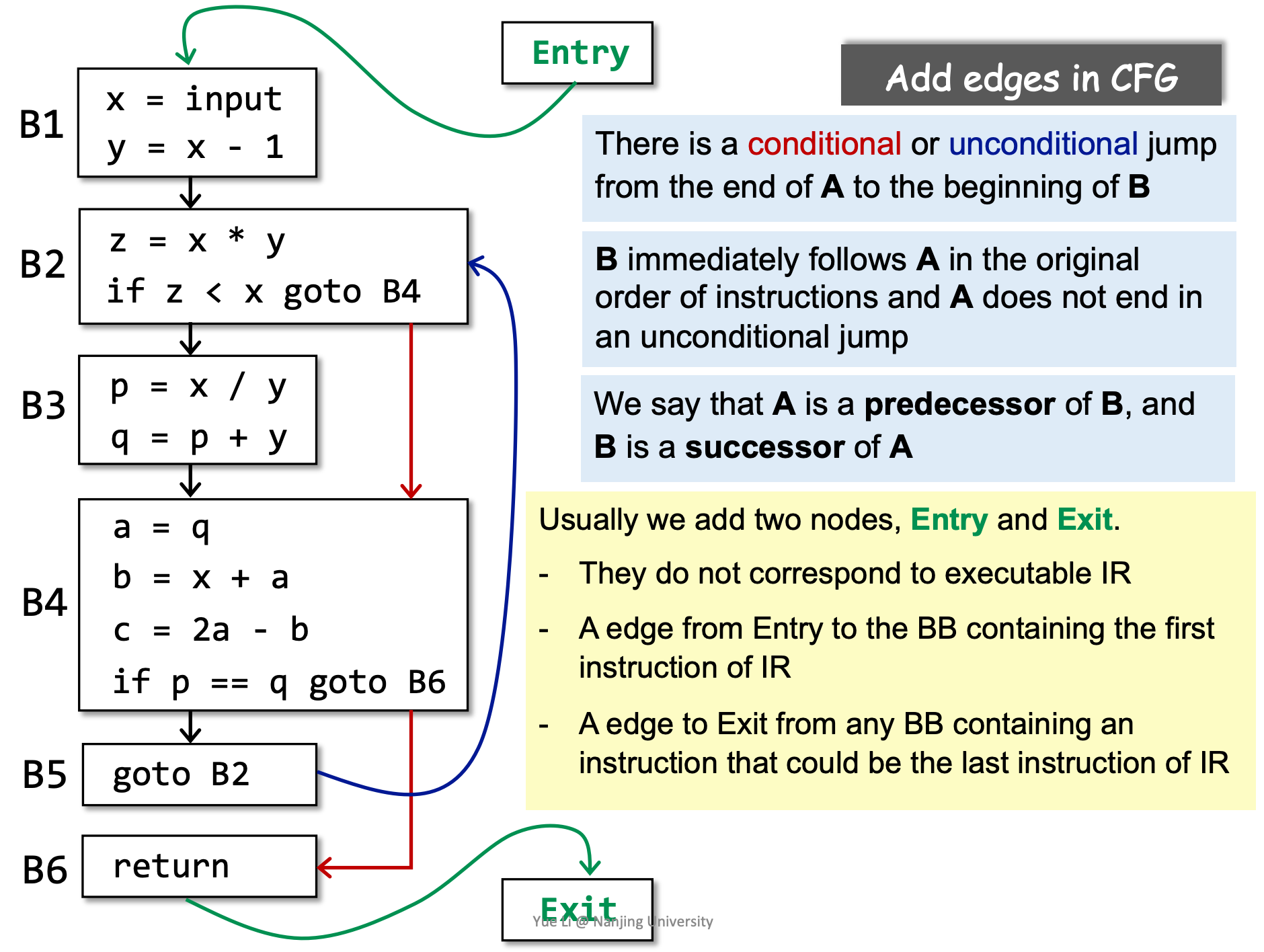
七、Control Flow Graphs (CFG) 控制流分析(Control Flow Analysis)通常指的是构建控制流图(Control Flow Graph, CFG),并以 CFG 作为基础结构进行静态分析的过程。
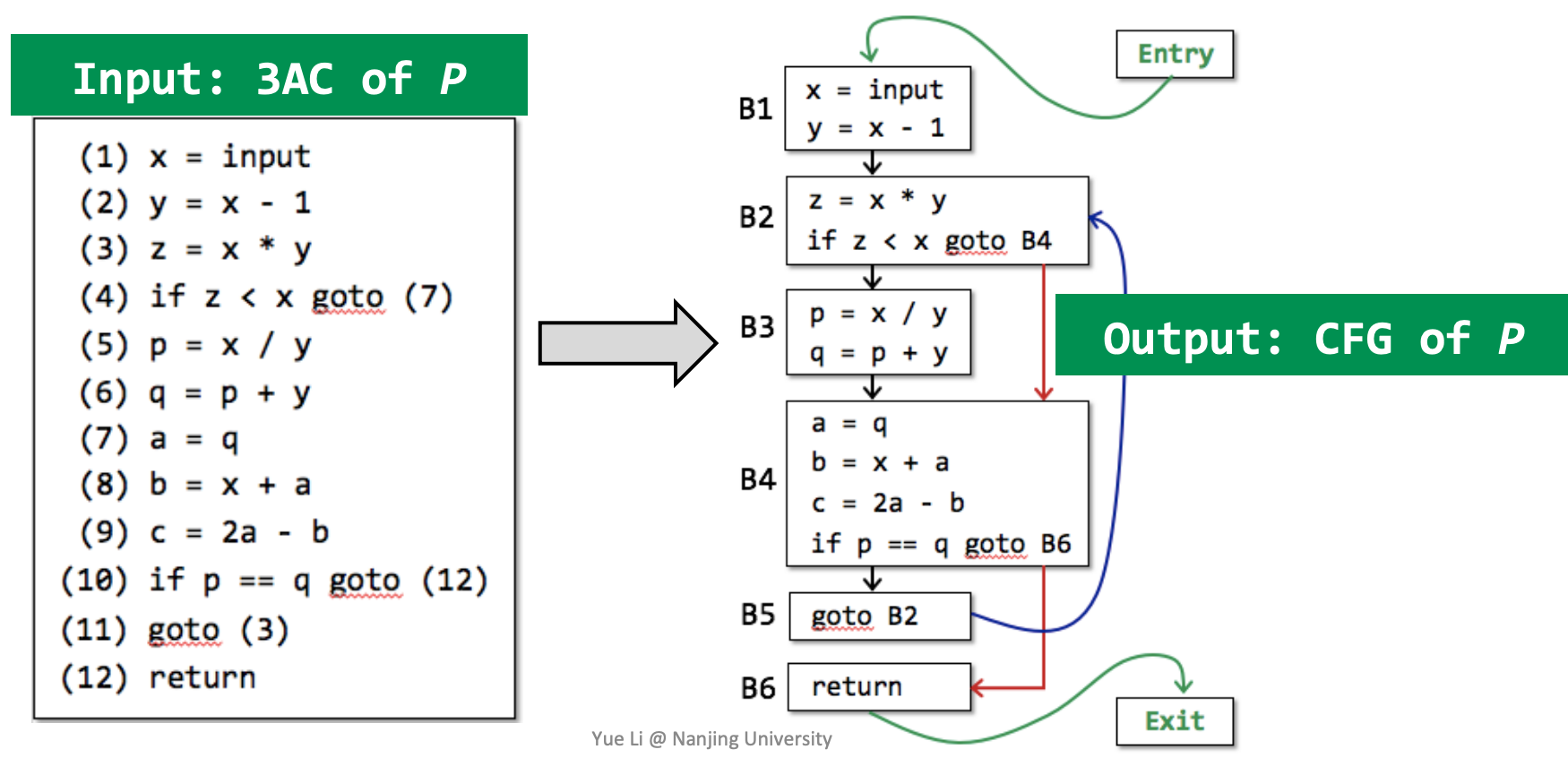 CFG 的一个结点可以是一条单独的 3AC,但是更常见的是一个基本块(Basic Block)。
CFG 的一个结点可以是一条单独的 3AC,但是更常见的是一个基本块(Basic Block)。
除了基本块,CFG 中还会有块到块的边。块 A 和块 B 之间有一条边,当且仅当:
- A 的末尾有一条指向了 B 开头的跳转指令
- A 的末尾紧接着 B 的开头,且 A 的末尾不是一条无条件跳转指令
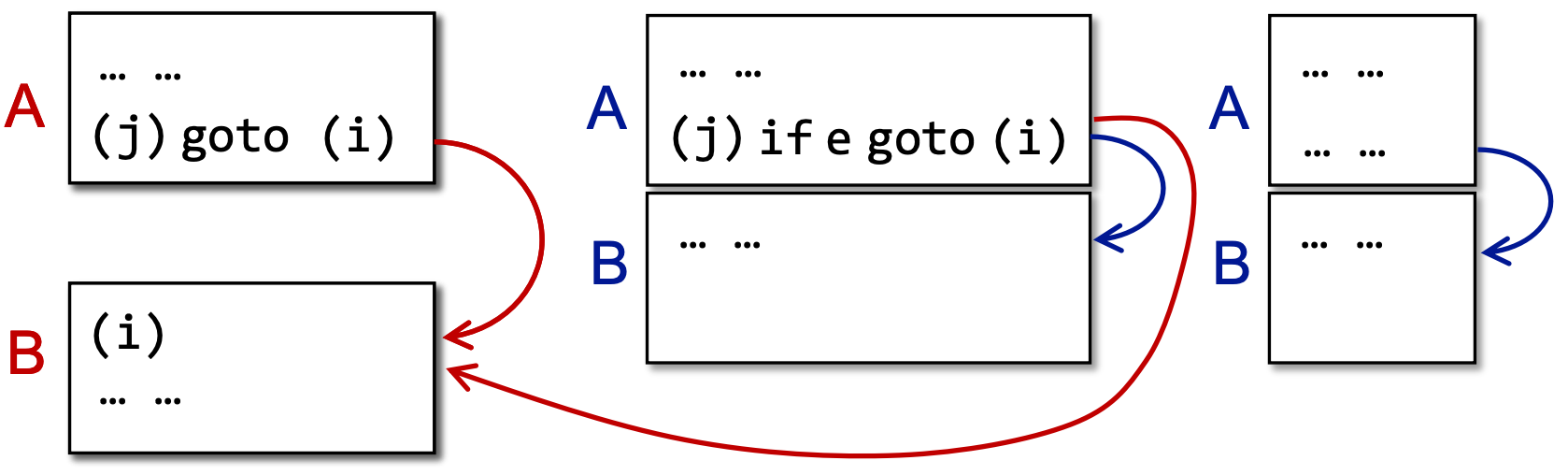
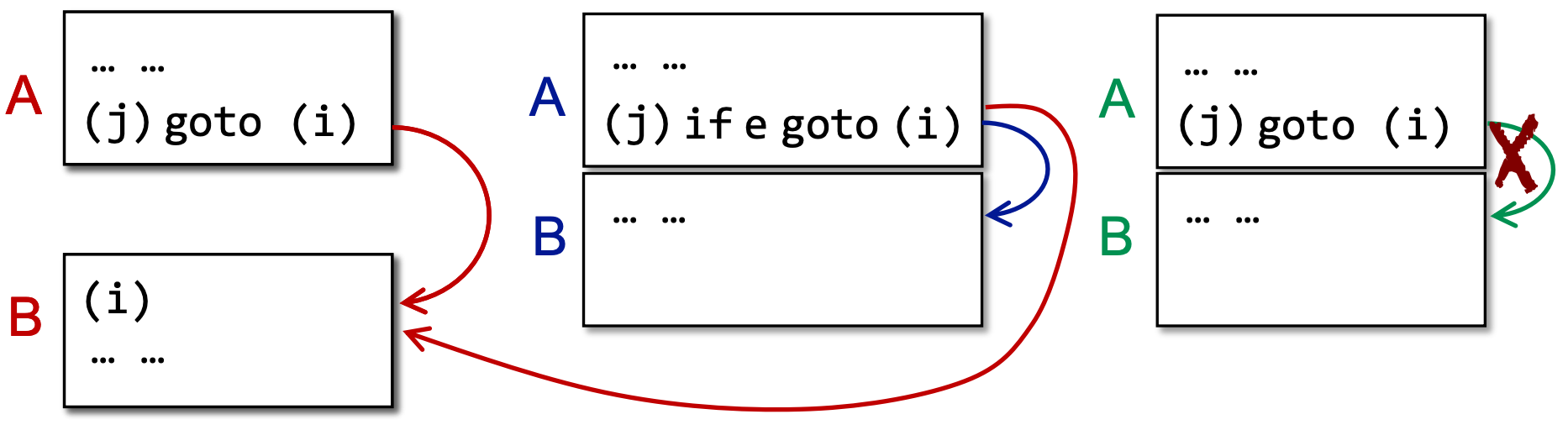
基本块的入口(leader):
- 整个程序的第一个指令是入口
- 有条件或无条件跳转指令的跳转目标指令是入口
- 紧接着有条件或无条件跳转的下一条指令是入口
接着,向下取最大的序列作为基本块。
基本块的出口:
- 可由入口决定
注意到每个基本块和开头指令的标号唯一对应,因此很自然地,我们可以将跳转指令的目标改为基本块的标号而非指令标号:

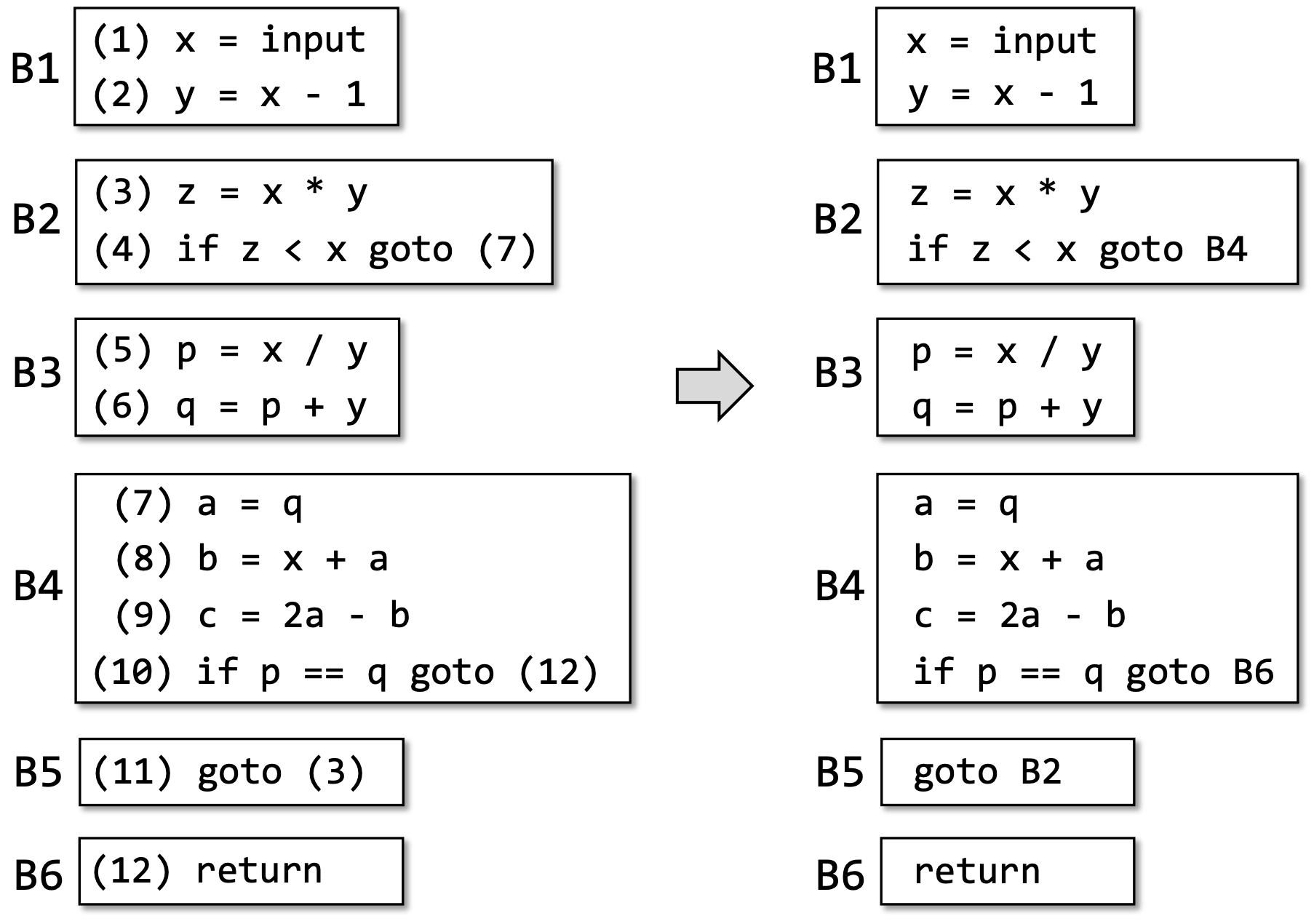
有了基本块,接下来我们讨论基本块之间的连接,
- 由有条件或无条件跳转指令连接,则构成一条边
- 两个基本块直接相连并且第一个块的末尾不是无条件跳转时构成一条边
- 最后,习惯性的加上Entry和Exit块
- 这两种块不代表具体的可执行指令
- 包含整个程序的第一条指令的基本块之前加上Entry
- 可以作为最后一条指令的块后加Exit(一个程序可以有多个出口)
另外,
- 若 A -> B,则我们说 A 是 B 的前驱(predecessor),B 是 A 的后继(successor)