除了统计图表外,seaborn也可以绘制热图,而且支持聚类树的绘制,绘制热图有以下两个函数 1. heatmap,绘制普通的热图 2. clustermap,绘制带聚类数的热图 1. heatmap 相比matplotlib的imshow功能,
除了统计图表外,seaborn也可以绘制热图,而且支持聚类树的绘制,绘制热图有以下两个函数
1. heatmap, 绘制普通的热图
2. clustermap,绘制带聚类数的热图
1. heatmap
相比matplotlib的imshow功能,该函数提供了更加简洁的接口,可以轻松实现文字注释的添加等功能,基本用法如下
>>> import numpy as np>>> data = np.random.rand(10, 10)
>>> sns.heatmap(data)
>>> plt.show()
输出结果如下
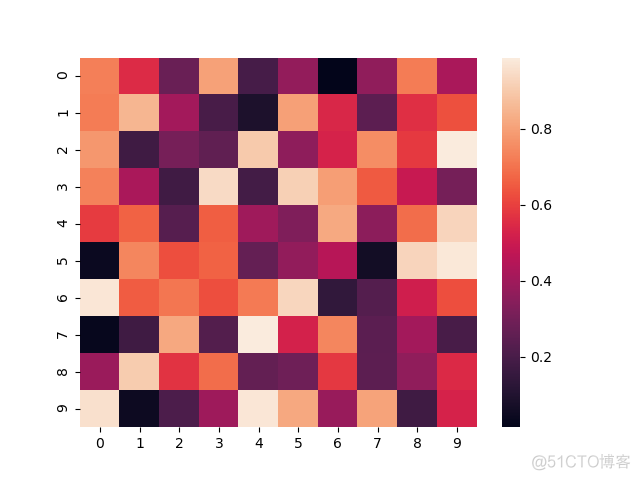
在imshow中的部分参数在该函数中也是可以使用的,比如vmin, vmax,cmap等参数。除了通用参数外,该函数有两个特色,第一就是可以方便的添加分割线,使图片更加的美观,使用linescolor和linewidth参数指定分割线的颜色和宽度,用法如下
>>> sns.heatmap(data, linewidth=1)>>> plt.show()
输出结果如下
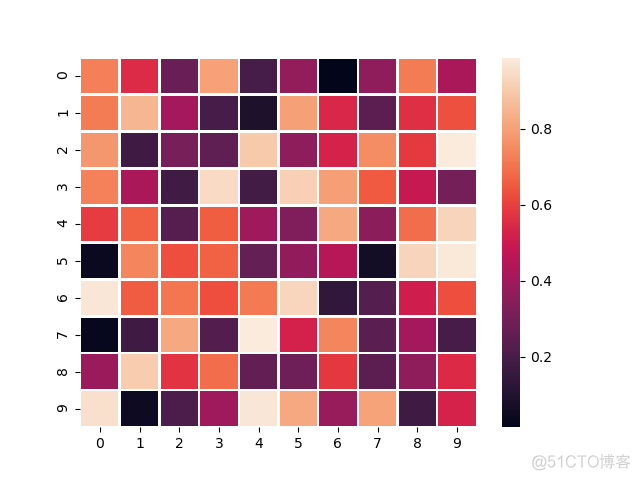
第二个特色是添加数字注释,在单元格上显示对应的数值,用法如下
>>> sns.heatmap(data, linewidth=1, annot=True)>>> plt.show()
输出结果如下
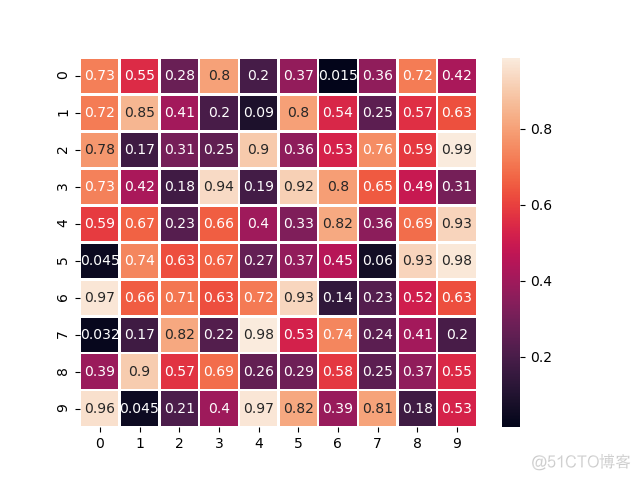
2. clustermap
clustermap绘制带聚类数的热图,基本用法如下
>>> data = np.random.rand(10,5)>>> df = pd.DataFrame(data)
>>> df.columns = ['sampleA', 'sampleB', 'sampleC', 'sampleD', 'sampleE']
>>> sns.clustermap(df)
>>> plt.show()
输出结果如下
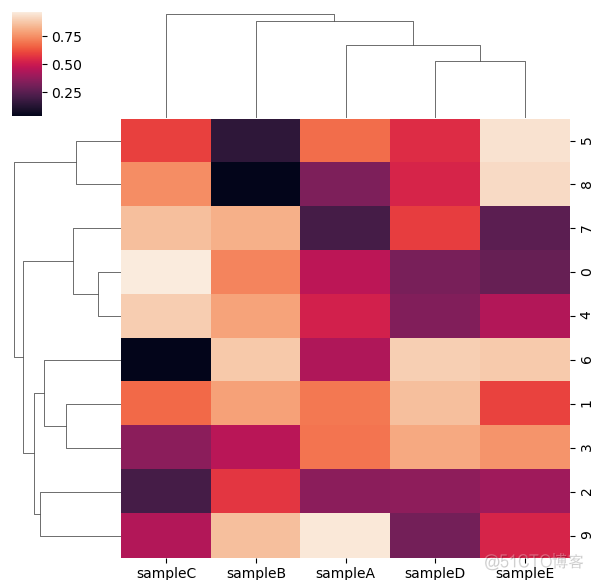
图中的聚类树是通过scipy模块中提供的距离矩阵和聚类算法实现的,通过method和metrix参数可以分别指定聚类算法和距离矩阵的算法。
对于可视化而言,我们常用的参数有以下3个,第一个standard_scale, 对数据进行标准化,比如按行进行标准化,用法如下
>>> sns.clustermap(df, standard_scale=0)>>> plt.show()
输出结果如下
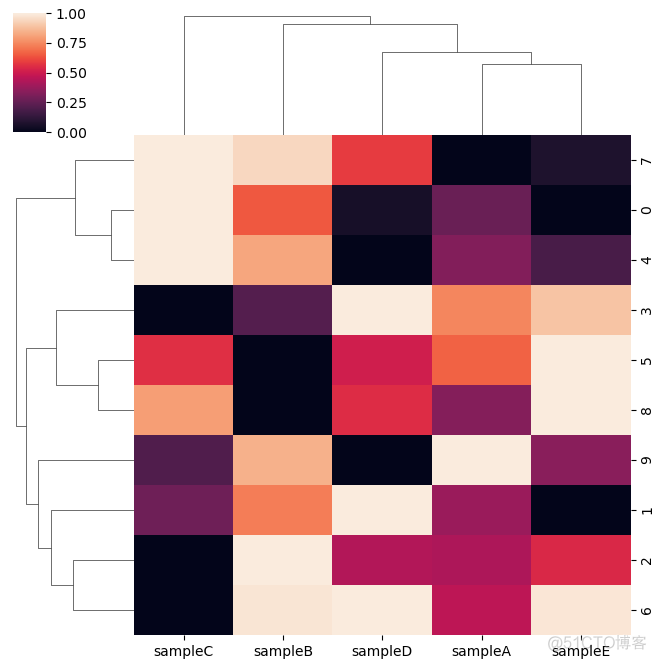
第二个参数为z_score, zscore也是数据标准化的一种手段,按照行列计算zscore的用法如下
>>> sns.clustermap(df, z_score=0)>>> plt.show()
输出结果如下
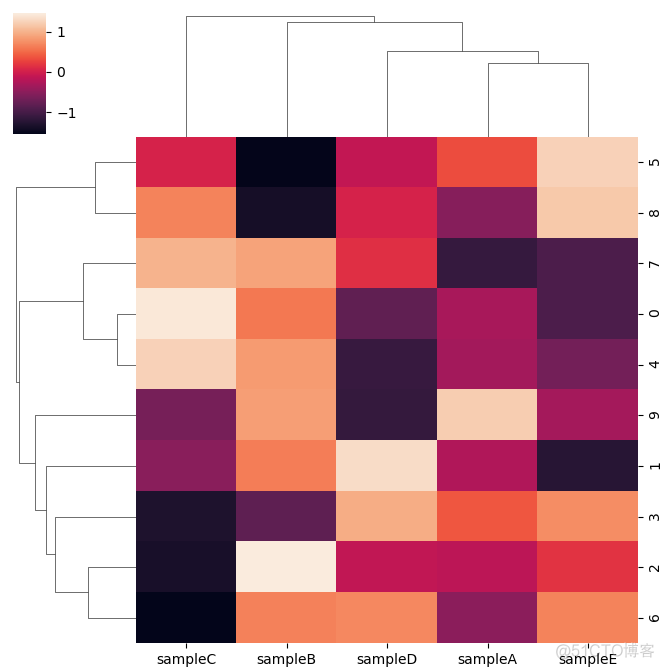
第三个参数为row_color/col_color. 用来对行标签和列标签进行注释,用法如下
>>> sns.clustermap(df, col_colors=['r','g','b','b','b'])>>> plt.show()
输出结果如下
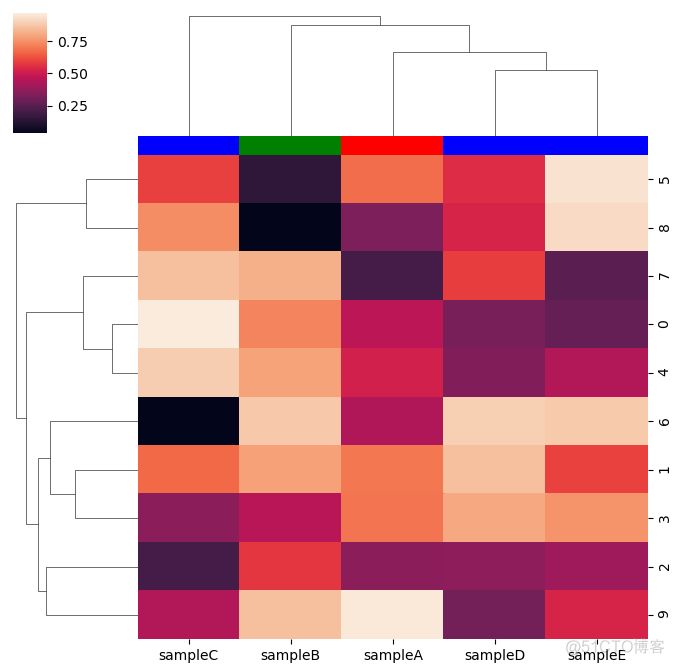
以上只是介绍了两个函数的基本用法和常用参数,其实具体的参数还要很多,可以通过官网的API文档来详细学习每个参数的用法。
·end·

一个只分享干货的
生信公众号