LDSC全称如下
linkage disequilibrium score regression
简称LDSR或者LDSC, 在维基百科中,对该技术进行了简单介绍。通过GWAS分析可以识别到与表型相关的SNP位点,然而严格来讲这个结果并不一定真实客观的描述遗传因素对表型的效应,因为其结果是由以下两个因素共同构成的
尽管我们在GWAS分析中,可以通过协变量来校正群落分层等因素,但是混淆因素是无法完全消除的。为了保证分析结果的准确性,我们就需要评估GWAS分析结果中以上两个因素的占比,只有当混淆因素占比很低时,才能说明我们的分析结果是可靠的,此时我们就可以通过LDSC来探究这个混淆因素的占比。
LDSC本质是一个线性回归,其输入数据为GWAS的分析结果,回归的自变量为SNP位点的LD score值,因变量是该算法的核心,自定义的一个符合卡方分布的统计量,通过线性回归拟合LD score和卡方统计量的关系,从而判断GWAS分析结果中是否存在混淆因素。
首先来看下自变量LD score, 对于一个SNP位点,其LD score定义该位点与其邻近位点的连锁不平衡R2的总和,公式如下
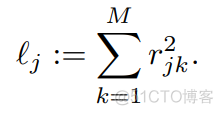
对于一个SNP位点j, 取其邻近位点,通常是指定一个固定窗口,比如1CM遗传距离,计算该窗口内的其他位点与该位点的连锁不平衡情况下,用R2相加即得到了该位点的LD score。然后再来看下因变量,公式如下
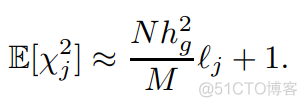
其中N为样本总数,M为窗口内的其他SNP位点数,h²是遗传力,这几个值为常数,从公式可以看出,卡方统计量和LD score之间是一个线性关系,而且对应到图像上,其截距为1。上述公式是只考虑遗传效应的前提下得到,如果存在混淆因素,那么最后的截距就不是1了。
通过LDSC回归分析的截距,可以判断GWAS结果中是否存在混淆因素。如果截距在1附近,说明没有混淆因素,如果解决超过这个范围,说明有混淆因素的存在。同时公式中涉及到了遗传力,通过LDSC也可以评估遗传力的大小。
在下面这篇文章中,对LDSC进行了详细介绍
https://www.nature.com/articles/ng.3211

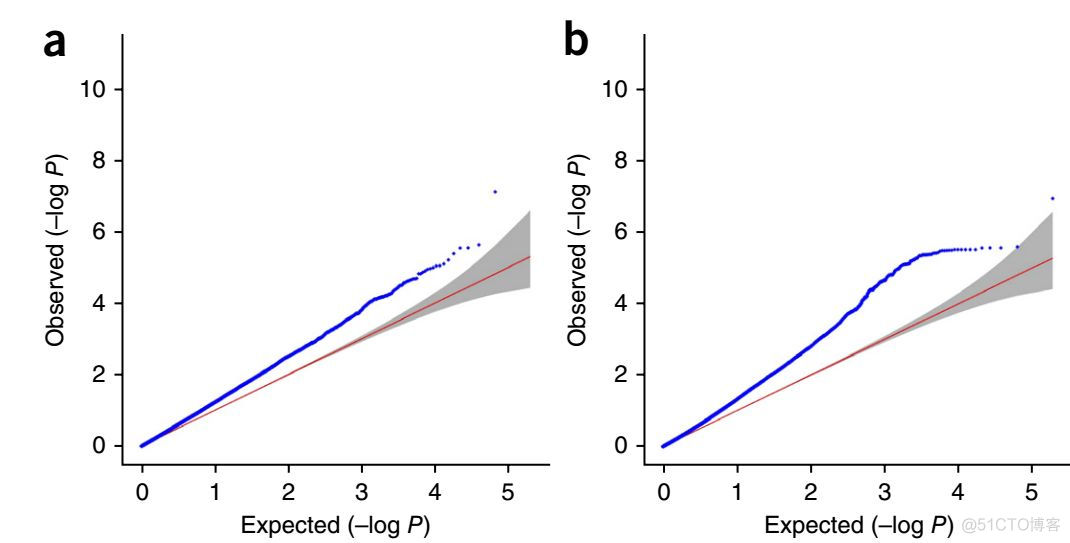
文章中通过模拟数据演示了LDSC的作用,如下图所示,左侧为存在群体分层时的QQ图,右侧为不存在混淆因素的QQ图
对于这两个GWAS结果,分别进行LDSC回归分析,结果如下
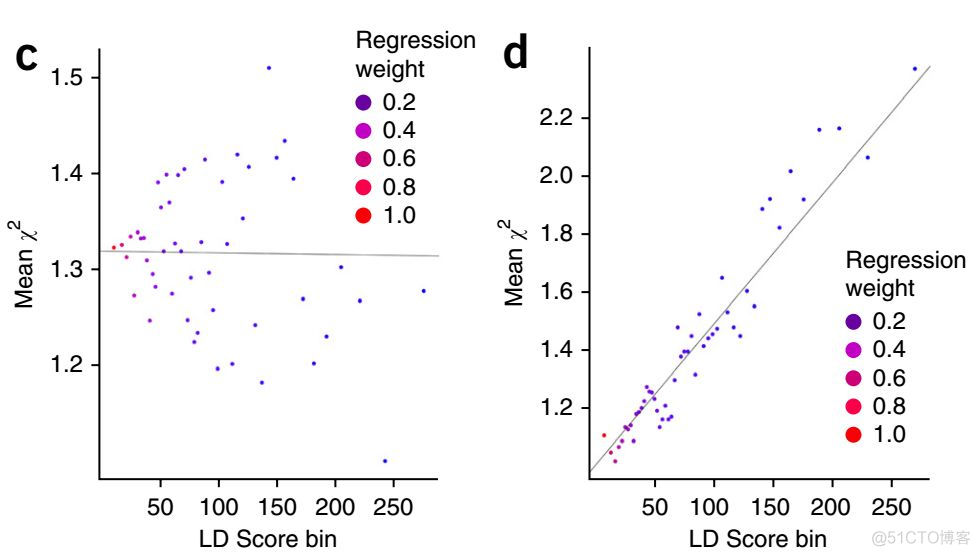
可以看到,存在混淆因素时,截距在1.3左右,而不存在时的,截距在1左右。
针对单个表型的GWAS分析,LDSC可以鉴定是否存在混淆因素,估计遗传力的大小;对于多个表型,则可以根据对应的卡方统计量,计算表型间的遗传相似度。
关于LDSC的分析,有一个同名软件,网址如下
https://github.com/bulik/ldsc
后续会详细介绍其用法。
·end·

生物信息入门
只差这一个
公众号