在进行机器学习建模之前,首先要对数据中存在的异常点样本进行过滤,异常点,也叫做离群点,对数据的归一化,以及后续建模的准确性都会造成影响。因此,必须先去除异常点,常用的有以下3种策略
1. 基于统计学的方法
最简单的方法是箱线图的方式,基于百分位数来筛选异常值点。箱线图示例如下
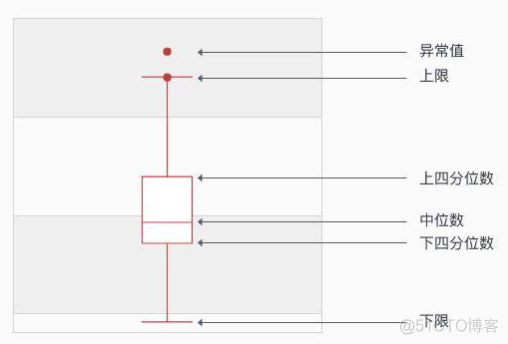
其中大于上限和小于下限的点都看做是离群值点。上限和下限的求解公式如下图所示
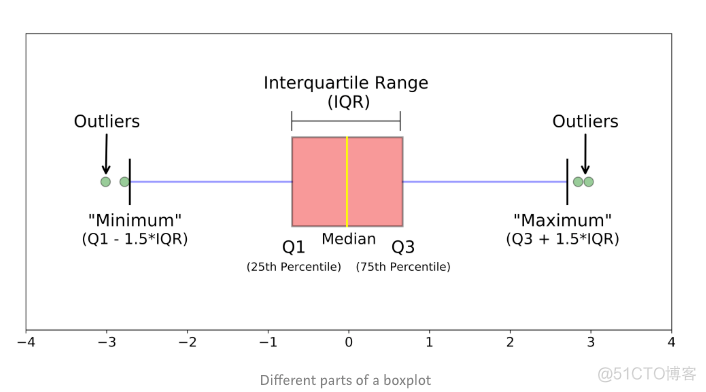
下四分位数称之为Q1, 上四分卫数称之为Q3, Q1和Q3的差值称之为IOR, 下限的值为Q1-1.5*IQR, 上限的值为Q3+1.5*IOR。这种方法适合在单一维度上识别异常值点。
除了箱体图外,还可以基于总体分来来计算概率的方法,比如基于正态分布,图示如下
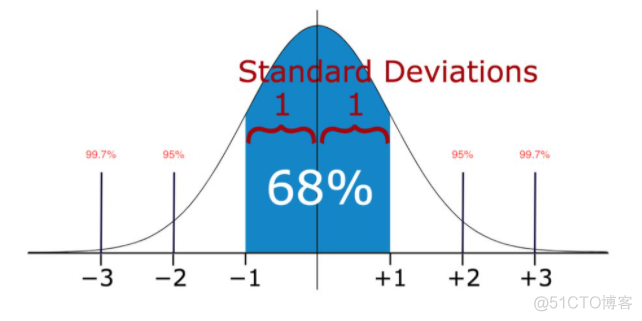
当取值偏离均值3个标准差的时候,概率较小,认为是异常值点。基于分布算概率的方法要求数据符合特定分布,有一点的局限性。
2. 基于聚类的方法
异常点在聚类中表现为单个聚类簇,明显与正常样本区分开。在聚类时同时考虑了多个维度的信息,更适用高纬度的数据。经典的BIRCH和DBSCAN算法都可以在聚类的同时,来识别异常点。DNSCAN算法中异常点示例如下
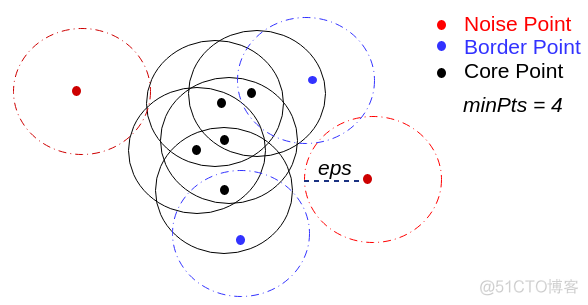
3. 专用的异常点检测算法
对于异常点检测而言,其本质是一个分类问题,将所有样本划分为正常样本和异常样本两类,但是不同于监督学习中的分类算法,这里的输入数据是没有标签的,所以是一种无监督学习的策略。经典的算法有以下两种
1. one class SVM
2. isolation Forest
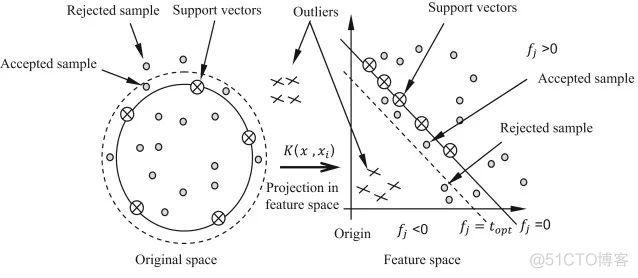
one class SVM, 从命名就可以看出,属于SVM家族。和经典的二分类SVM不同,这里采用了超球体来分隔数据,示意如下
isolation Forest, 属于随机森林家族,称之为孤立森林算法,算法过程示意如下
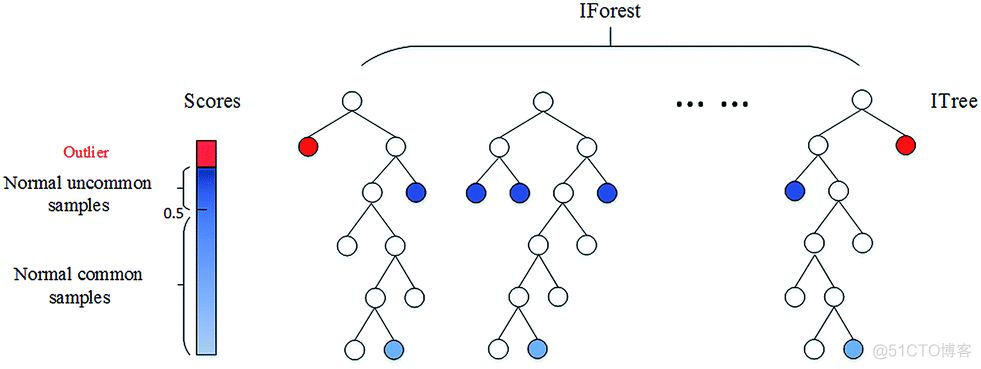
第一步是构建多颗独立的决策树,在该算法中每颗决策树所用样本数目不等,分裂时采用随机特征分裂,当只剩一个样本或者深度达到阈值时停止迭代;
第二步计算每颗决策树中样本点的高度平均值,离根节点越近,高度越小,离根节点越远,高度越大;
第三步判断是否为异常点,根据高度值构建一个打分系统,取值范围0-1,靠近1被认为是异常点;
sickit-learn中提供了多种异常点检测算法,上述两种异常点检测算法的用法如下
>>> from sklearn.svm import OneClassSVM>>> X = [[0], [0.44], [0.45], [0.46], [1]]
>>> clf = OneClassSVM(gamma='auto').fit(X)
>>> clf.predict(X)
array([-1, 1, 1, 1, -1], dtype=int32)
>>>
>>> from sklearn.ensemble import IsolationForest
>>> X = [[-1.1], [0.3], [0.5], [100]]
>>> clf = IsolationForest(random_state=0).fit(X)
>>> clf.predict([[0.1], [0], [90]])
array([ 1, 1, -1])
isolation Forest算法复杂度低,适用于大样本量的数据,但是对于特别高维的数据,算法可靠性会降低,此时可以考虑使用one class SVM。
·end·

一个只分享干货的
生信公众号