non-negative matrix factorization,简写为NMF, 翻译为非负矩阵分解,属于矩阵分解的一种算法。在特征分解,SVD等传统的矩阵分解技术中,分解后的矩阵会出现负值,但是负值在实际场景中
non-negative matrix factorization,简写为NMF, 翻译为非负矩阵分解,属于矩阵分解的一种算法。在特征分解,SVD等传统的矩阵分解技术中,分解后的矩阵会出现负值,但是负值在实际场景中是没有意义的,比如在图像处理领域,图像是由像素点构成的矩阵,每个像素点由红,绿,蓝的比例构成,这些数值都是非负数,在对分解处理得到的负值并没有实际意义。
基于非负数的约束,NMF矩阵分解算法应运而生。对于任意一个非负矩阵V,可以将该矩阵划分为两个非负矩阵的乘积,图示如下
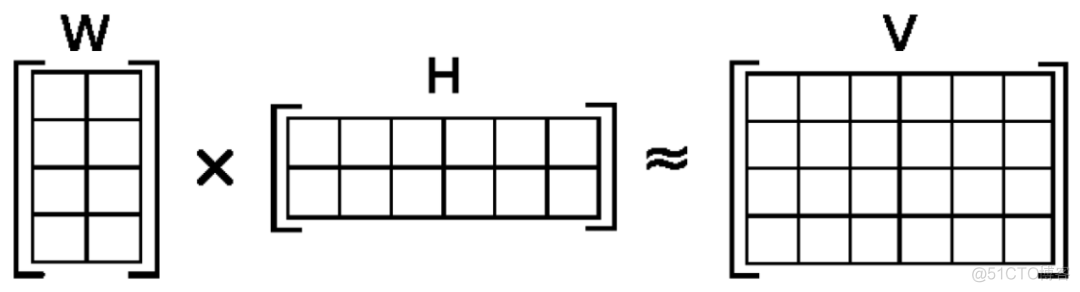
其中W称之为基矩阵,H称之为系数矩阵,根据矩阵乘法的定义,W中的每一个列向量乘以H矩阵对应的列向量,得到V矩阵中的一个列向量,其实就是一个线性组合
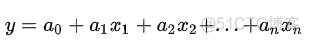
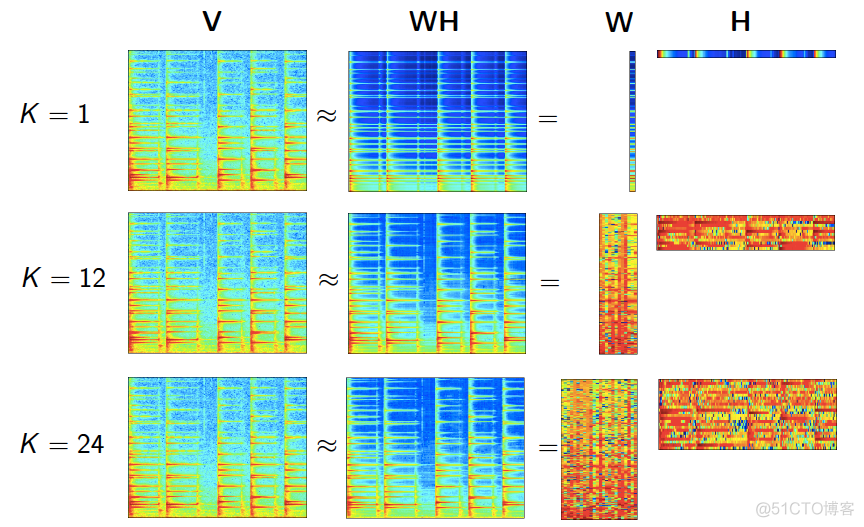
类似SVD, NMF算法将矩阵分解之后,也可以提取其中的主要部分来代表整体,从而达到降维的效果,图示如下
NMF的求解思想是使得W与H矩阵的乘积,与V矩阵的误差值最小,数学表达式如下
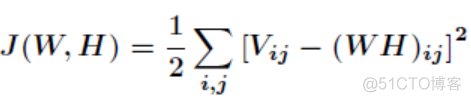
该损失函数从形式上看是一个L2范数,求解最小值时可以通过导数来操作,其中
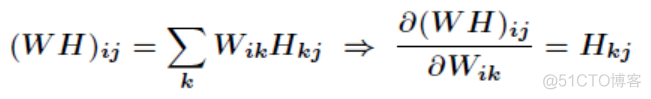
基于上述公式进行求导,可得
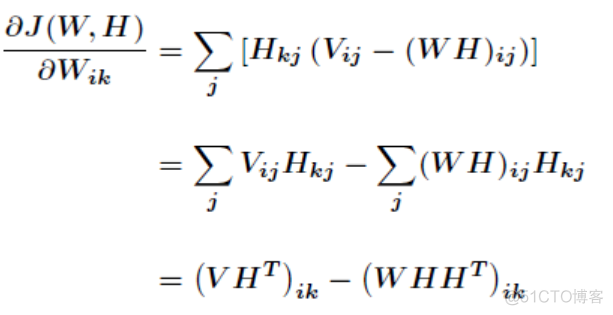
同理
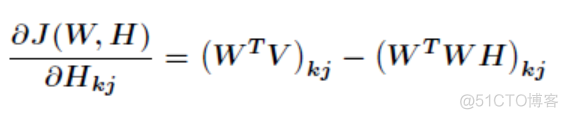
用梯度下降法进行迭代,公式如下
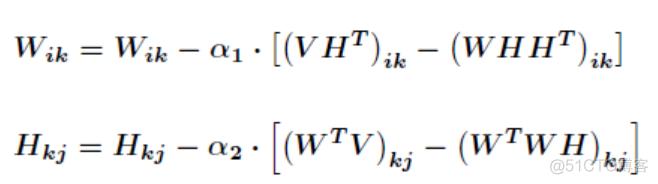
其中α1和α2为学习率,将其设置如下
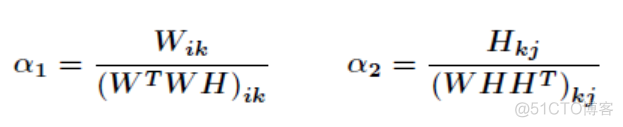
则可以得到最终的迭代公式
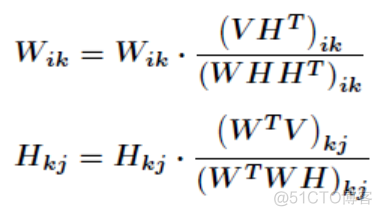
在scikit-learn中,使用NMF的代码如下
>>> import numpy as np>>> X = np.array([[1, 1], [2, 1], [3, 1.2], [4, 1], [5, 0.8], [6, 1]])
>>> from sklearn.decomposition import NMF
>>> model = NMF(n_components=2, init='random', random_state=0)
>>> W = model.fit_transform(X)
>>> W
array([[0. , 0.46880684],
[0.55699523, 0.3894146 ],
[1.00331638, 0.41925352],
[1.6733999 , 0.22926926],
[2.34349311, 0.03927954],
[2.78981512, 0.06911798]])
>>> H = model.components_
>>> H
array([[2.09783018, 0.30560234],
[2.13443044, 2.13171694]])
>>> X
array([[1. , 1. ],
[2. , 1. ],
[3. , 1.2],
[4. , 1. ],
[5. , 0.8],
[6. , 1. ]])
>>> np.dot(W, H)
array([[1.00063558, 0.99936347],
[1.99965977, 1.00034074],
[2.99965485, 1.20034566],
[3.9998681 , 1.0001321 ],
[5.00009002, 0.79990984],
[6.00008587, 0.999914 ]])
NMF的非负约束使得其分解后的子矩阵更加具有实际意义,在模式识别,生物医药,计算机视觉与图像处理等领域都有广泛应用。
·end·

一个只分享干货的
生信公众号