近年来由于抓取数据而引起的纠纷越来越多,有的锒铛入狱,有的被处罚金,本人爬虫笔记学习提醒大家:爬虫有风险,采集需谨慎,写代码不能违法,写代码背后也有法律风险
1.1爬虫注意点 1.1.1遵守Robots协议Robots协议,也称为爬虫协议、机器人协议等,全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉爬虫哪些页面可以抓取,哪些页面不能抓取
如何查看网站的rebots协议?
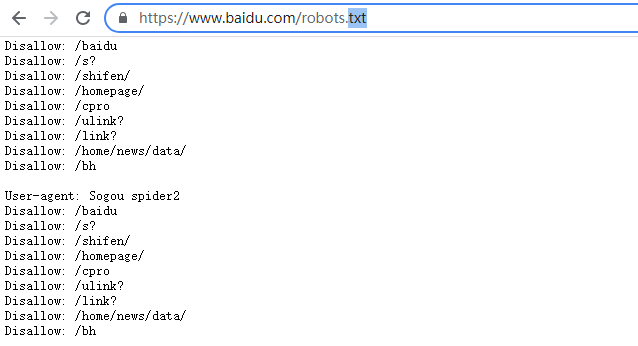
(1)打开浏览器,在地址栏中输入http://网站域名/robots.txt即可,以查询百度的robots协议为例;Disallow后边的目录是禁止所有搜索引擎搜索的
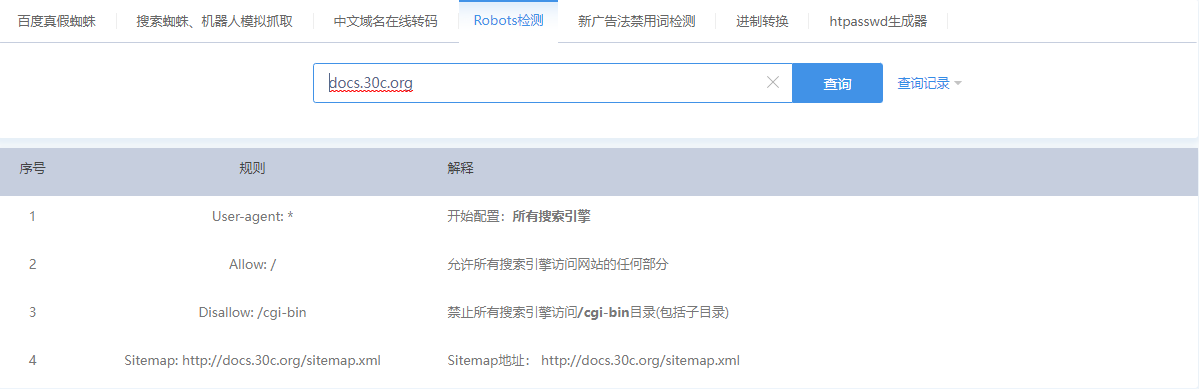
(2)或者借助相关网站进行查看,如站长工具等,浏览器打开http://s.tool.chinaz.com/robots,输入网站地址,点击查询即可
过度数据采集会对目标站点产生非常大的压力,可导致目标站点服务器瘫痪、不能访问等,相当于网络攻击。学习过程中抓取数据不可贪多,满足学习需求即可,损害他人权益的事不能做
1.1.3.不要采集隐私数据有选择的采集数据,别人不让看的数据不要爬,私人数据不要爬,如手机号、身份证号、住址、个人财产等不要抓取,受法律保护的特定类型的数据或信息不能抓取
1.1.4.网站有声明”禁止爬虫采集或转载商业化”当采集的站点有声明,禁止爬虫采集或转载商业化,请绕行,不让爬的数据不要爬
1.1.5.不得将抓取数据用于商业化使用恶意利用爬虫技术抓取数据,进行不正当竞争,甚至牟取不法利益,会触犯法律,数据采集不得伤害他人利益
1.2.爬虫与爬虫工程师
爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本,是搜索引擎的重要组成;爬虫可以用于以下场景:搜索引擎、数据分析、人工智能、薅羊毛、抢车票等
目前市面主流的爬虫产品有:神箭手、八爪鱼、造数、后羿采集器等
爬虫工程师简单点理解就是数据的搬运工
爬虫工程师技术储备
- python编程基础
- linux系统管理基础
- http协议
- 数据库增删改查基础
爬虫技术怎么学
- 首先要学会基础的Python语法知识
- 学习Python爬虫常用到的几个重要内置库Requests,用于请求网页
- 学习正则表达式re、Xpath(lxml)等网页解析工具
- 了解爬虫的一些反爬机制,header、robot、代理IP、验证码等
- 了解爬虫与数据库的结合,如何将爬取的数据进行存储
- 学习应用python的多线程、多进程进行爬取,提高爬虫效率
- 学习爬虫的框架scrapy
2.网络基础 2.1.网络协议 2.1.1什么是协议?
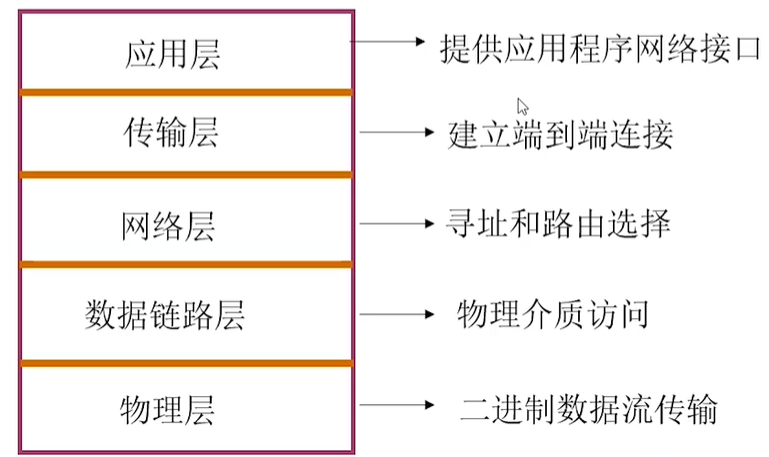
协议可以理解为“规则”,是数据传输和数据的解释规则,下图是简单图解

- 物理层:可以理解为我们的网线,进行比特流的传输
- 数据链路层:可以理解为我们电脑的网卡,网卡的驱动可以提供介质访问、链路管理等
- 网络层:网卡可以设置ip地址,进行网络寻址和路由选择
- 传输层:可以想象成电脑里面的应用,建立主机端到端连接
- 会话层:建立、维护和管理会话
- 表示层:处理数据格式、数据加密等
- 应用层:提供应用程序间通信
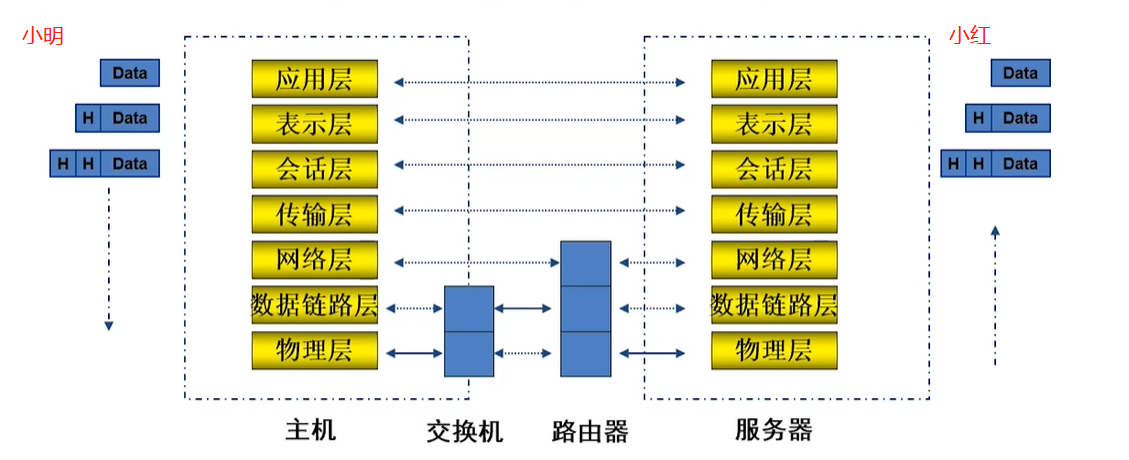
示例:以小明和小红利用qq软件发消息来再次讲解下osi7层模型
小明在qq软件里面给小红发了一个“hello”
数据封装
- 小明_应用层:对小明发送的hello数据,加上应用层的报头:应用层的数据协议单元
- 小明_表示层:并不关心上一层的数据格式,把应用层整体的数据进行一个封装,加上表示层的数据头
- 小明_会话层:对上一层数据加上会话层报头并进行封装
- 小明_传输层:对上一层数据加上传输层报头并进行封装
- 小明_网络层:对上一层数据加上网络层报头并进行封装
- 小明_数据链路层:对上一层数据加上数据链路层报头并进行封装;同时还要对网络层的数据加上数据链路层报尾,形成最终的传输数据
- 小明_物理层:发送给交换机
交换机:发送给路由器
路由器:发送给小红的物理层
数据解封装
- 小红_物理层:拦截小明的传输的数据,递交给数据链路层
- 小红_数据链路层:丢掉小明数据的数据帧的头部,进行数据校验,数据没有问题是给小红的并且数据是完整的,将数据递交给网络层
- 小红_网络层:同数据链路层,进行解封装,并传递给上一层
- 小红_传输层:同数据链路层,进行解封装,并传递给上一层
- 小红_会话层:同数据链路层,进行解封装,并传递给上一层
- 小红_表示层:同数据链路层,进行解封装,并传递给上一层
- 小红_应用层:同数据链路层,进行解封装,小红看到“hello”
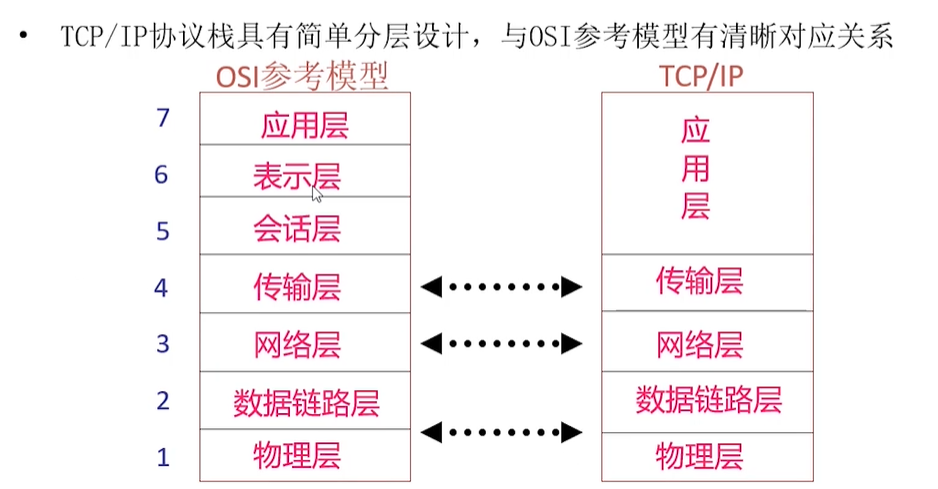
TCP/IP协议栈,TCP/IP协议继承ISO模型网上有的说是四层有的说是五层,四层的是将物理层没算进去,到底记哪一个,这个不冲突,都可以。
图示tcp/ip相比较iso少了表示层、会话层
TCP/IP各层实现的协议
- 应用层:
- HTTP:超文本传输协议,基于TCP,使用80号端口,是用于www服务器传输超文本到本地浏览器的传输协议
- SMTP:简单邮件传输协议,基于TCP,使用25号端口,是一组用于由源地址到目的地址传送邮件的规则,用来控制信件的发送、中转;比如QQ邮箱,用的就是这个协议
- FTP:文件传输协议,基于TCP,一般上传下载用FTP服务,数据端口是20号,控制端口是21号
- TELNET:远程登录协议,基于TCP,使用23号端口,是Internet远程登录服务的标准协议和主要方式。为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上上使用telnet程序连接到服务器。使用明码传送,保密性差、简单方便
- DNS:域名解析,基于UDP,使用53号端口,提供域名到IP地址之间的转换
- SSH:安全外壳协议,基于TCP,使用22号端口,为建立在应用层和传输层基础上的安全协议。SSH是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议
- 传输层:
- TCP:传输控制协议。一种面向连接的、可靠的、基于字节流的传输层协议
- UDP:用户数据报协议。一种面向无连接的通讯协议,不可靠的、基于报文的传输层通信协议
- SCTP:流量传输控制协议。一种面向连接的流传输协议;可以看成TCP的升级版
- MPTCP:多路径传输控制协议。TCP的多路径版本。SCTP虽然在首发两端有多条路径,但实际只是使用一条路径传输,当该条路径出现故障时,不需要断开连接,而是转移到其他路径。MPTCP真正意义上实现了多路径并行传输,在连接建立阶段,建立多条路径,然后使用多条路径同时传输数据
- 网络层:
- IP:Internet协议。通过路由选择将下一条IP封装后交给接口层。IP数据报是无连接服务
- ICMP:Internet控制报文协议。是网络层的补充。用于在P主机、路由器之间传递控制消息,检测网络通不通、主机是否可达、路由是否可用等网络本身的消息;cmd窗口ping地址就是用的这个协议
- ARP:地址解析协议。通过目标设备的IP地址,查询目标设备的MAC地址,以保证通信的顺利进行;常见于交换机路由器
- RARP:反向地址解析协议
2.2.HTTP协议详解 2.2.1.HTTP
HTTP协议,又称之为超文本传输协议,是互联网上应用最为广泛的一种网络协议,它是基于TCP的应用层协议;
是客户端和服务端进行通信的一种规则,它的模式非常简单,就是客户端发起请求,服务端响应请求。
2.2.2.版本分布- HTTP最早于1991年发布,是0.9版,不过目前该版本已不再用
- HTTP/1.0,于1996年5月发布,引入了多种功能,至今仍在使用当中
- HTTP/1.1,于1997年1月发布,持久连接被默认采用,是目前最流行的版本
- HTTP/2,于2015年5月发布,引入了服务器推送等多种功能,是目前最新的版本
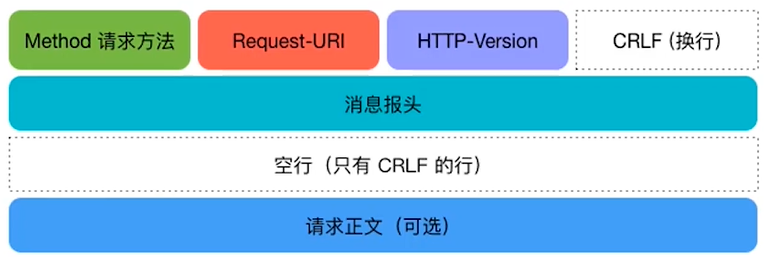
- 请求行:包含请求方法、请求地址和HTTP协议版本
- 消息报头:包含一系列的键值对
- 请求正文(可选):注意和消息报头之间有一个空行
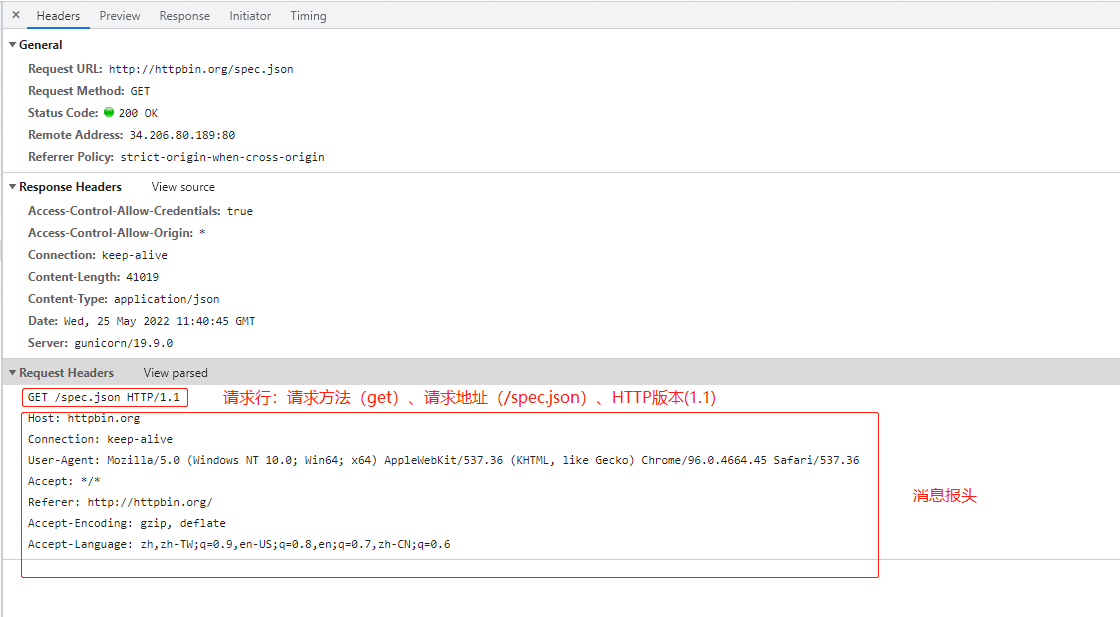
- GET:从服务器获取指定(请求地址)的资源的信息,它通常只用于读取数据,就像数据库查询一样,不会对资源进行修改
- POST:向指定资源提交数据(比如提交表单,上传文件),请求服务器进行处理。数据被包含在请求正文中,这个请求可能会创建新的资源或更新现有的资源
- PUT:通过指定资源的唯一标识(在服务器上的具体存放位置),请求服务器创建或更新资源
- DELETE:请求服务器删除指定资源
- HEAD:与GET方法类似,从服务器获取资源信息,和GET方法不同的是,HEAD不含有呈现数据,仅仅是HTTP头信息。HEAD的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获得资源的元信息(或元数据)
- OPTIONS:该方法可使服务器传回资源所支持的所有HTTP请求方法;简单理解就是查看服务器支持哪些HTTP请求方法
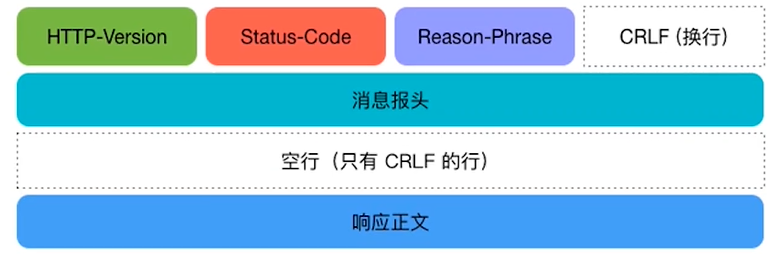
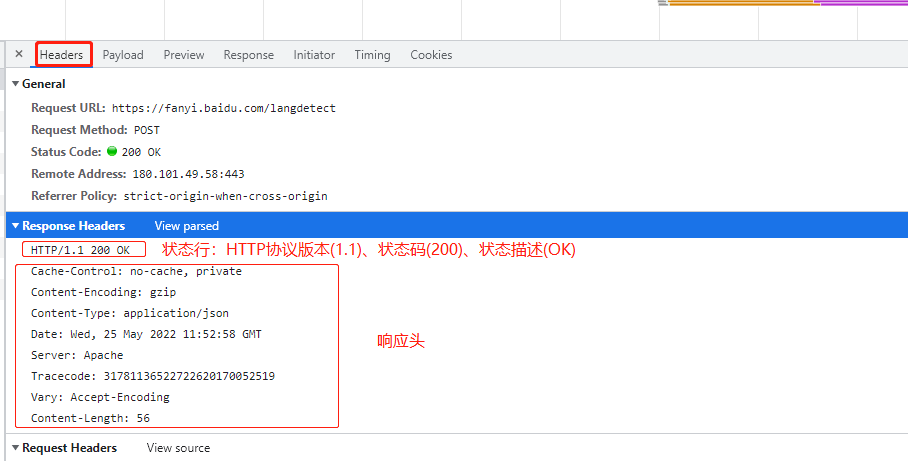
- 状态行:包含HTTP协议版本、状态码和状态描述,以空格分隔
- 响应头:即消息报头,包含一系列的键值对
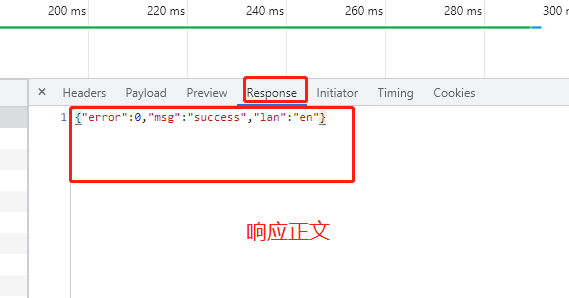
- 响应正文:返回内容,注意和响应头之间有一个空行
- 1XX 消息:请求已被服务接收,继续处理
- 2XX 成功:请求已成功被服务器接收、理解、并接受
- 200:OK
- 201:Created 已创建
- 202:Accepted 接收
- 203:Non-Authoritative Information 非认证信息
- 204:No Content 无内容
- 3XX 重定向:需要后续操作才能完成这一请求
- 301:Moved Permanently 请求永久重定向
- 302:Moved Temorarily 请求临时重定向
- 304:Not Modified 文件未修改,可以直接使用缓存的文件
- 305:Use Proxy 使用代理
- 4XX 请求错误:请求含有此法错误或者无法被执行
- 400:Bad Request 由于客户端请求有语法错误,不能被服务器所理解
- 401:Unauthorized 请求未经授权。这个状态代码必须和WWW-Authenticate报头域一起使用
- 403:Forbidden 服务器收到请求,但是拒绝提供服务。服务器通常会在响应正文中给出不提供服务的原因
- 404:Not Found 请求的资源不存在,例如,输入错误的URL
- 5XX 服务器错误:服务器在处理某个正确请求时发生错误
- 500:Internal Server Error 服务器发生不可预期的错误,导致无法完成客户端的请求
- 503:Service Unavailable 服务器当前不能够处理客户端的请求,在一段时间之后,服务器肯能会恢复正常
- 504:Gateway Time-out 网关超时
2.3.解析HTTP数据流的传输过程
以一个经典面试题作为缩影进行讲解:
请简述:从客户端打开浏览器到服务器返回网页,中间的过程
2.3.1.宏观解析
1)在一个客户端上,打开浏览器,在浏览器的地址栏中,输入www.baidu.com,访问百度
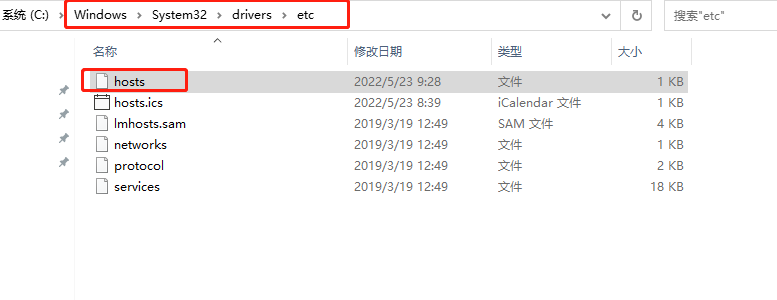
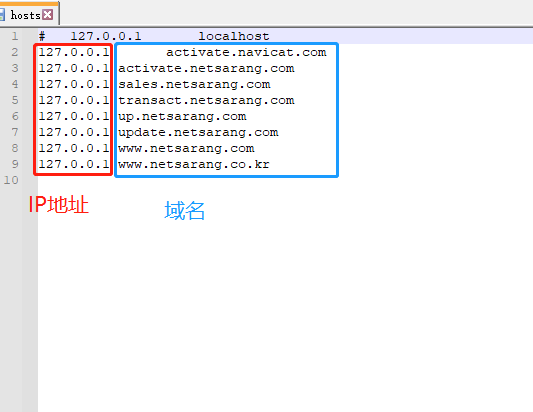
2)在你敲入网址并按下回车之后,将会发生以下的事情:浏览器先尝试从Host文件中获取http://www.baidu.com/对应的IP地址,如果能获取到则直接使用hosts文件的解析结果;host文件在本地的C:\Windows\System32\drivers\etc目录下
3)如果Host文件中找不到,就会使用DNS协议来获取IP。在DNS协议中,PC会向你本地DNS求助,请求DNS服务器之后,得到百度的IP

4)接下来浏览器会请求获得的Ip地址对应的Web服务器,Web服务器接收到客户的请求并响应处理,将客户请求的内容返回给客户端浏览器
5)如果服务器正常则给你回个“OK”,状态码为200并将你要的数据传给你。你收到服务器的回复,是HTML形式的文本。浏览器必须能够理解文本的内容,并快速的渲染到屏幕上,渲染出来后,你就能看到百度的首页了
2.3.2.微观解析
1)域名解析:同宏观解析,通过本地host文件查找;找不到,PC请求本地DNS帮忙;最后得到域名的IP
2)建立连接:
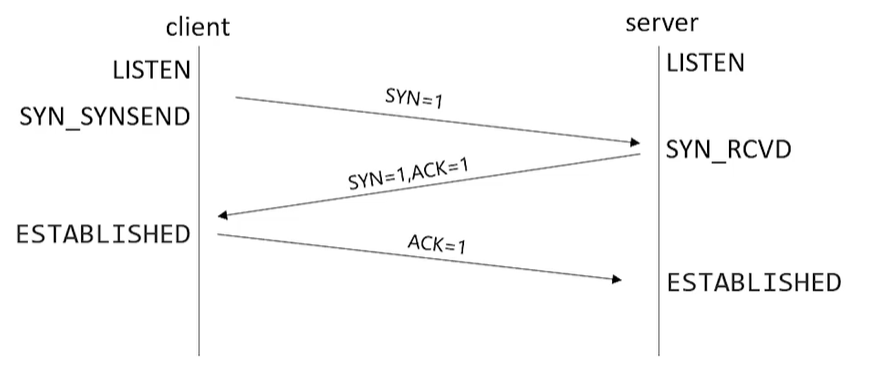
TCP三次握手:双向连接确认过程
- step-1 监听:首先client客户端和server服务端都处于LISTEN监听状态
- step-2 第一次握手(客户端):
- 客户端告诉服务端我要访问你,完成第一次握手;
- 详解为:客户端会发送一个TCP的SYN,并且标志位为1的这样一个数据包;同时指明客户端要连接服务器的端口;发送完毕后,客户端进入SYN_SYNSEND的状态;并完成第一次握手
- step-3 第二次握手(服务端):
- 服务端告诉客户端我收到了你的SYN数据包,你的内容为SYN=1,并且返回一个ACK=1的数据包,和客户端的SYN=1一并打包发给客户端;
- 同时服务端由LISTEN状态变成SYN_RCVD状态;完成第二次握手
- step-4 客户端发送ACK给服务端:
- 客户端再次访问服务端,并发送ACK=1确认数据包,跟服务端确认是否一致
- 发送完毕后客户端进入ESTABLISHED状态
- step-5 第三次握手(服务端):
- 服务端收到客户端发过来的ACK=1数据包,确认无误后,同样进入ESTABLISHED状态;
- 完成第三次握手
3)发送HTTP请求:同宏观解析,客户端发送get或post请求;服务器正常给你返回200,OK,以及返回你要的html文本;客户端对服务端给的heml文本进行解析、渲染、展示
4)断开连接:
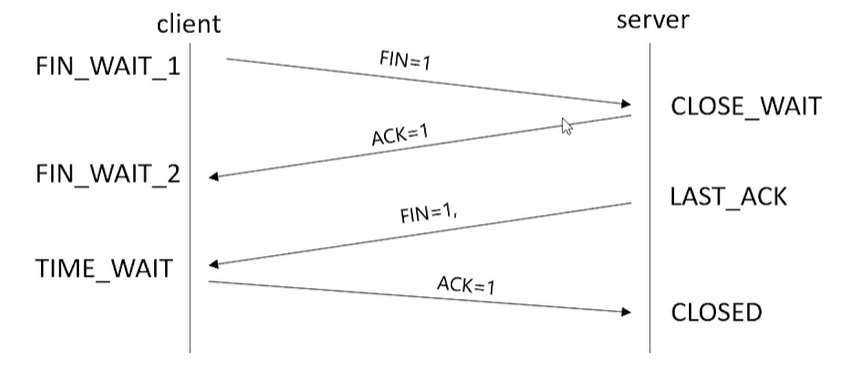
TCP四次挥手:双向断开确认
- step-1 第一次挥手(客户端):
- 客户端告诉服务端请求我已经发送完毕了,我想要跟你断开连接了,没有数据可以发送了,但是呢服务端你还能向我发送数据,我还能接收数据;
- 详解为:客户端会发送一个TCP的FIN,并且标志位为1的这样一个数据包;告诉服务端我已经没有数据可以发送了,但是我还能接收数据;发送完毕后,客户端进入FIN_WAIT_1的状态;并完成第一次挥手
- step-2 第二次挥手(服务端):
- 服务端确认了客户端的FIN数据包,并回一个ACK=1的数据包,表明我接收到了客户端关闭连接的请求,但是我这边还没有准备好关闭整个连接;
- 同时服务端由进入CLOSE_WAIT状态;完成第二次握手
- step-3 客户端接收ACK等待服务端关闭连接:
- 客户端接收到服务端发过来的ACK=1数据包,客户端状态变更为FIN_WAIT_2状态;并等待服务端关闭连接
- step-4 第三次挥手(服务端):
- 服务端向客户端发送一个FIN=1的数据包,表明我可以关闭连接了,响应数据已经都发完了。
- 服务端状态变更为LAST_ACK;等待客户端发送ACK确认包
- step-5 第四次挥手(客户端):
- 客户端收到服务端可以关闭的FIN数据包后,发送ACK=1包给服务端;告诉服务端,我这边没有问题,你关闭连接吧
- 客户端状态变更为TIME_WAIT;
- step-6 服务端关闭连接 :
- 服务端接收到客户端发送的ACK=1确认包后,关闭连接;服务端状态变更为CLOSED