目录 SQLAchemy 1、 ORM框架 2、 快速认识 2.1 运行流程 2.2 基本使用 2.3 连接数据库 2.4 执行原生的SQL语句 3、 创建多表 4、 增删改查 5、 常用操作 6、 创建连接的方式 SQLAchemy1、 ORM框架 什么
- SQLAchemy
- 1、 ORM框架
- 2、 快速认识
- 2.1 运行流程
- 2.2 基本使用
- 2.3 连接数据库
- 2.4 执行原生的SQL语句
- 3、 创建多表
- 4、 增删改查
- 5、 常用操作
- 6、 创建连接的方式
什么是ORM?
-
关系对象映射
类 -> 表 对象 -> 记录(一行数据) -
当有了对应关系之后,不再需要填写SQL语句,取而代之的是操作:类、对象
-
python下常见的ORM有django orm、SQLAlchemy和peewee
概念:
db first:根据数据库的表生成类code first:根据类创建数据库表
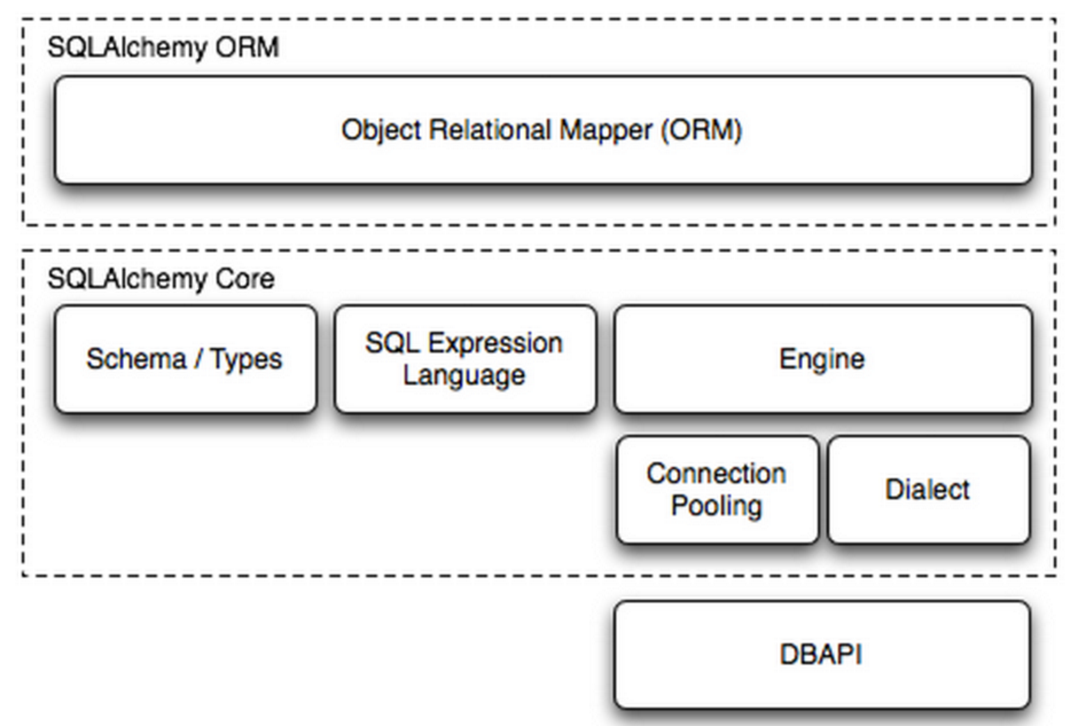 2.2 基本使用
2.2 基本使用
在models.py文件中
创建表和删除表
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# @author: A.L.Kun
# @file : models.py
# @time : 2022/6/8 0:00
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, Column, INTEGER, String
Base = declarative_base() # 创建一个基类
# 数据库连接
engine = create_engine(
"mysql+pymysql://root:qwe123@127.0.0.1:3306/flask1?charset=utf8", # 数据库url
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待时间,否则报错
pool_recycle=-1 # 多久之后线程池中的线程进行一次连接重置
) # 默认带了连接池
# 创建表
class Users(Base):
__tablename__ = "users1" # 设置表名
id = Column(INTEGER, primary_key=True, autoincrement=True)
name = Column(String(32))
extra = Column(String(32))
# # 创建表,如果表已经存在,则不会再创建
# Base.metadata.create_all(engine)
# # 删除表
# Base.metadata.drop_all(engine)
给表添加信息
在其他py文件中
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# @author: A.L.Kun
# @file : test.py
# @time : 2022/6/8 0:13
from sqlalchemy.orm import sessionmaker
import models
session = sessionmaker(bind=models.engine)() # 创建连接
obj = models.Users(name="kun", extra="hello")
session.add(obj) # 将数据添加到表中
session.commit() # 提交事务
SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>
pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>
cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
更多详见:http://docs.sqlalchemy.org/en/latest/dialects/index.html
# 数据库连接
engine = create_engine("mysql+pymysql://root:qwe123@127.0.0.1:3306/flask1?charset=utf8") # 默认带了连接池
cur = engine.execute("SELECT * FROM user1")
print(cur.fetchall())
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# @author: A.L.Kun
# @file : models.py
# @time : 2022/6/8 0:00
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import (
create_engine, Column, INTEGER, String,
DATETIME, # 创建存储时间的列
ForeignKey, # 外键约束
Index, # 创建索引
UniqueConstraint, # 创建联合唯一索引
)
import datetime
Base = declarative_base() # 创建一个基类
# 数据库连接
engine = create_engine(
"mysql+pymysql://root:qwe123@127.0.0.1:3306/flask1?charset=utf8", # 数据库url
) # 默认带了连接池
# 创建班级表
class Classes(Base):
__tablename__ = "classes" # 设置表名
id = Column(INTEGER, primary_key=True, autoincrement=True)
name = Column(String(32), nullable=False, unique=True)
# 学生表,其和班级表是一对多的关系
class Student(Base):
__tablename__ = "student"
id = Column(INTEGER, primary_key=True, autoincrement=True)
username = Column(String(32), nullable=False, unique=True)
password = Column(String(64), unique=False)
ctime = Column(DATETIME, default=datetime.datetime.now) # 创建时间,注意now后面不需要加括号,不然只会记录初始化时间,而不是添加数据的时间
class_id = Column(INTEGER, ForeignKey("classes.id")) # 外键约束
# 学生的爱好
class Hobby(Base):
__tablename__ = "hobby"
id = Column(INTEGER, primary_key=True)
caption = Column(String(50), default="篮球")
from sqlalchemy.orm import relationship
cls = relationship("Classes", secondary="S_H", backref="stus") # 创建多表关联,通过cls键进行关联,secondary其为将两张表关联起来的表,backref,反向生成
# 多对多的表,即把学生和爱好连接起来
class S_H(Base):
__tablename__ = "s2h"
id = Column(INTEGER, primary_key=True, autoincrement=True)
stu_id = Column(INTEGER, ForeignKey("student.id"))
hob_id = Column(INTEGER, ForeignKey("hobby.id"))
__table_args__ = (
UniqueConstraint("stu_id", "hob_id", name="uin_stu_hob"), # 给两列创建联合唯一索引
# Index("in_stu_hob", "stu_id", "extra") # 创建一个索引
)
if __name__ == '__main__':
# 创建表,如果表已经存在,则不会再创建
Base.metadata.create_all(engine)
# # 删除表
# Base.metadata.drop_all(engine)
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# @author: A.L.Kun
# @file : test.py
# @time : 2022/6/8 0:13
from sqlalchemy.orm import sessionmaker
import models
from sqlalchemy import text
session = sessionmaker(bind=models.engine)() # 连接数据库
def add_data():
"""添加数据"""
# 单条增加
cls = models.Classes(name='1班')
session.add(cls)
# 多条增加
objs = [
models.Classes(name='2班'),
models.Classes(name='3班')
]
session.add_all(objs)
def del_data():
"""删除数据"""
session.query(models.Classes).filter(models.Classes.id > 2).delete() # 指定条件删除数据
def find_data():
"""查询数据"""
ret = session.query(models.Classes).all() # 获取全部数据
ret1 = session.query(models.Classes.name).all() # 获取名字数据
ret2 = session.query(models.Classes).filter(models.Classes.name == "2班009009").all() # 获取2班的数据
ret3 = session.query(models.Classes).filter_by(name="2班009009").first() # 获取二班的数据
ret4 = session.query(models.Classes).filter(text("id<:value and name=:name")).params(
# :value 和 :name 为一个占位符,使用order_by进行排序作用
value=224,
name="field"
).order_by(models.Classes.id)
ret5 = session.query(models.Classes).from_statement(text("SELECT * FROM classes WHERE name=:name")).params(
name="ed" # 构造SQL语句
)
print(ret5)
# 使用子查询
ret6 = session.query(models.Classes).filter(models.Classes.id.in_(
session.query(models.Classes.id).filter_by(name="eee") # 其为子查询
)).all()
ret7 = session.query()
print(ret)
"""联表操作"""
# 获取学生信息,以及其班级信息
# 方法一
objs = session.query(models.Student.id, models.Student.username, models.Classes.name).join(models.Classes, isouter=True).all()
# 方法二
objs1 = session.query(models.Student).all()
"""
# 在models.Student 末尾添加这两行代码,进行内部自动根据外键关联数据库
from sqlalchemy.orm import relationship
cls = relationship("Classes", backref="stus") # backref 其为反向生成,即等于是在 Classes 中添加 stus = relationship("Student")
"""
for item in objs1:
print(
item.id,
item.username,
item.cls, # 这个为关联的数据库,可以访问其内部的内容
)
def up_data():
"""修改数据"""
session.query(models.Classes).filter(models.Classes.id >= 1).update({
models.Classes.name: models.Classes.name + "009",
# 也可以 "name": models.Classes.name + "009",
},
synchronize_session=False # 在内部不进行运算,而是直接拼接,如果值为 "evaluate" 的话,就会进行运算
)
# add_data()
# del_data()
# find_data()
# up_data()
session.commit() # 提交事务
session.close()
# 条件
# 通过一个条件来查询
ret = session.query(Users).filter_by(name='alex').all()
# id > 1 && name == "eric"
ret = session.query(Users).filter(Users.id > 1, Users.name == 'eric').all()
# 1 <= id <= 3 && name == "eric"
ret = session.query(Users).filter(Users.id.between(1, 3), Users.name == 'eric').all()
# id in (1, 3, 4)
ret = session.query(Users).filter(Users.id.in_([1,3,4])).all()
# id not in (1, 3, 4)
ret = session.query(Users).filter(~Users.id.in_([1,3,4])).all()
# SELECT * FROM USERS WHERE id IN (SELECT id FROM USERS WHERE name = "eric")
ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name='eric'))).all()
from sqlalchemy import and_, or_
# id > 3 && name == "eric"
ret = session.query(Users).filter(and_(Users.id > 3, Users.name == 'eric')).all()
# id < 2 || name == "eric"
ret = session.query(Users).filter(or_(Users.id < 2, Users.name == 'eric')).all()
# id < 2 || (name == "eric" && id > 3) || extra
ret = session.query(Users).filter(
or_(
Users.id < 2,
and_(Users.name == 'eric', Users.id > 3),
Users.extra != ""
)).all()
# 通配符
ret = session.query(Users).filter(Users.name.like('e%')).all()
ret = session.query(Users).filter(~Users.name.like('e%')).all()
# 限制
ret = session.query(Users)[1:2]
# 排序
ret = session.query(Users).order_by(Users.name.desc()).all()
ret = session.query(Users).order_by(
Users.name.desc(),
Users.id.asc() #
).all()
# 分组
from sqlalchemy.sql import func
ret = session.query(Users).group_by(Users.extra).all()
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).all()
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all()
# 连表
ret = session.query(Users, Favor).filter(Users.id == Favor.nid).all()
ret = session.query(Person).join(Favor).all()
ret = session.query(Person).join(Favor, isouter=True).all()
# 组合
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union(q2).all()
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union_all(q2).all()
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# @author: A.L.Kun
# @file : test.py
# @time : 2022/6/8 0:13
from sqlalchemy.orm import sessionmaker
from . import models
# 创建session的方式
session = sessionmaker(bind=models.engine)() # 连接数据库
# 第一种
def task():
session_ = session()
...
session_.close()
"""但是这种方式发送的请求过多时会造成阻塞,同时,其必须在每个线程内部创建连接"""
# 第二种
from sqlalchemy.orm import scoped_session
session_ = scoped_session(session)
def task():
...
session_.remove() # 移除连接,但是不关闭连接,同时在以后使用的时候可以不需要创建,直接调用即可
"""此方式是基于ThreadLocal对象来实现的,其可以使用线程把每一个session进行线程隔离"""