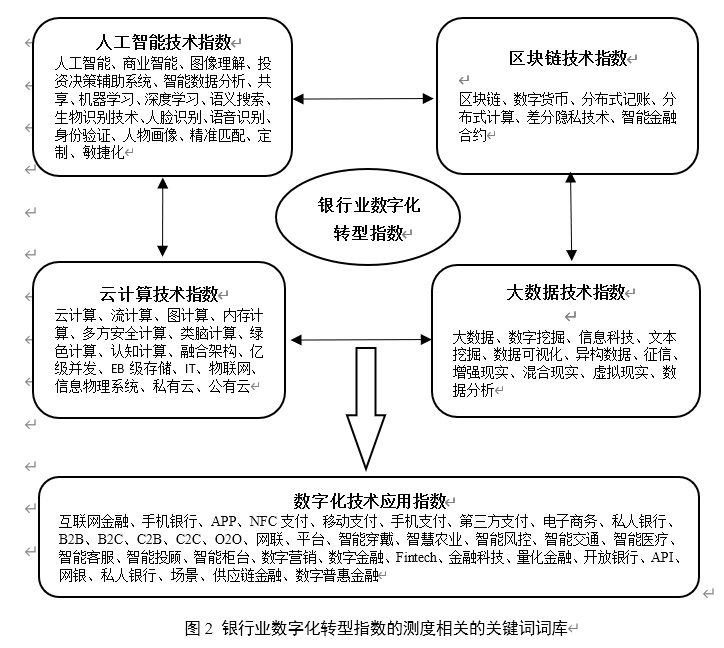
相关研究表明,银行等企业的数字化转型相关特征信息更容易体现在具有总结和指导性质的年度报表中(吴非,2021)。因此,通过统计银行年报中涉及“数字化转型”的词频来刻画其转型程度,具有可行性和科学性。具体而言,本文借助Python 爬虫功能对中国40家上市银行年度报表进行爬取,并采用Jieba分词模块对银行“数字化转型”相关的关键词进行分词与统计。使用Jieba的优势在于其能够精准地对中文文本进行识别与分词,同时支持用户自定义词典,可以有效提高分词的准确性。在词库方面,本文借鉴吴非(2021)的研究,将银行数字化转型细分为“底层技术”与“实践应用”两类,不仅包括了数字化转型的四种典型底层技术,即“ABCD”技术;同时也包含了这类技术在具体实践中的运用表现。此外,本文在已有研究的基础上对关键词词库进行有效补充。在此基础上,根据词库对上市银行年度报表进行匹配与词频汇总,同时剔除关键词前存在否定表达的词频后进行对数化得到银行业数字化转型指数。本文构建的与银行业数字化相关的关键词词库如图2所示:
二、过程 1、文件PDF转换
需要用到的库:
pip install pdfminer对pdfminer的简单介绍,官网翻译成中文的介绍如下:
PDFMiner是一个从PDF文档中提取信息的工具。与其他pdf相关的
工具不同,它完全专注于获取和分析文本数据。PDFMiner允许获取
页面中文本的确切位置,以及其他信息,比如字体或行。它包括一
个PDF转换器,可以将PDF文件转换成其他文本格式(如HTML)。
它有一个可扩展的PDF解析器,可以用于其他目的而不是文本分析。
由于PDF文件有如此大和复杂的结构,完整解析PDF文件很费时费力。然而在大多数PDF工作中,很多模块是不需要加进来的。因此 PDFMiner 采用了一个懒惰分析的策略,就是只分析所需要的部分。解析时候,至少需要2个核心类,PDFParser 和 PDFDocument。这两个模块配合其他模块来使用。
PDFParser 从文件中获取数据
PDFDocument 存储文档数据结构到内存中
PDFPageInterpreter 解析page内容
PDFDevice 把解析到的内容转化为你需要的东西
PDFResourceManager存储共享资源,例如字体或图片
源代码如下:
import pyocr
import importlib
import sys
import time
importlib.reload(sys)
time1 = time.time()
# print("初始时间为:",time1)
import os.path
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
text_paths = r'兴业银行2021 年 年 度 报 告'
def parse():
'''解析PDF文本,并保存到TXT文件中'''
print("------开始转换------")
text_path = f'银行\\兴业银行\\{text_paths}.pdf'
text_path2 = f'银行\\兴业银行\\TXT\\{text_paths}'
fp = open(text_path, 'rb')
# 用文件对象创建一个PDF文档分析器
parser = PDFParser(fp)
# 创建一个PDF文档
doc = PDFDocument()
# 连接分析器,与文档对象
parser.set_document(doc)
doc.set_parser(parser)
# 提供初始化密码,如果没有密码,就创建一个空的字符串
doc.initialize()
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 创建PDF,资源管理器,来共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释其对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
# 循环遍历列表,每次处理一个page内容
# doc.get_pages() 获取page列表
for page in doc.get_pages():
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
# 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象
# 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等
# 想要获取文本就获得对象的text属性,
for x in layout:
if (isinstance(x, LTTextBoxHorizontal)):
with open(f'{text_path2}.txt', 'a',encoding='utf-8') as f:
results = x.get_text()
print(results)
f.write(results + "\n")
f.close()
print("------转换完成------")
if __name__ == '__main__':
parse()
time2 = time.time()
print("总共消耗时间为:", time2 - time1)Jieba "结巴"中文分词:做最好的Python中文分词组件 "Jieba"
支持三种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- 支持繁体分词
- 支持自定义词典
这里我使用Jieba对转换好的txt文档读取分词,在此基础上,根据词库对上市银行年度报表进行匹配与词频汇总,同时剔除关键词前存在否定表达的词频后进行对数化得到银行业数字化转型指数。
源代码如下:
# 导入依赖
import jieba
import numpy as np
text_paths = r'兴业银行2021 年 年 度 报 告'
# text_path = f'银行\\兴业银行\\{text_paths}.pdf'
text_path2 = f'银行\\兴业银行\\TXT\\{text_paths}'
def fun():
# 读取文本
txt = open(f"{text_path2}.txt", "r", encoding='utf-8').read()
# 使用精确模式对文本进行分词
words = jieba.lcut(txt)
# 通过键值对的形式存储词语及其出现的次数
counts = {}
for word in words:
# 去掉词语中的空格
word = word.replace(' ', '')
# 如果词语长度为1,则忽略统计
if len(word) == 1:
continue
# 进行累计
else:
counts[word] = counts.get(word, 0) + 1
# # 将字典转为列表
# items = list(counts.items())
# # 根据词语出现的次数进行从大到小排序
# items.sort(key=lambda x: x[1], reverse=True)
# 查找指数词(自定义词库)
cKu = ["人工智能","网联","平台","智能穿戴","智慧农业","智能风控","智能交通","智能医疗","智能客服","智能投顾","智能柜台","数字营销","数字金融","Fintech","金融科技","量化金融","开放银行","API","网银","私人银行","场景","供应链金融","数字普惠金融","互联网金融","手机银行","APP","NFC支付","移动支付","手机支付","第三方支付","电子商务","私人银行","B2B","B2C","C2B","C2C","O2O","大数据","数字挖掘","信息科技","文本挖掘","数据可视化","异构数据","征信","增强现实","混合现实","虚拟现实","数据分析","IT","物联网","信息物理系统","私有云","公有云","云计算","流计算","图计算","内存计算","多方安全计算","类脑计算","绿色计算","认知计算","融合架构","亿级并发","EB级存储","区块链","数字货币","分布式记账","分布式计算","差分隐私技术","智能金融合约","商业智能","图像理解","投资决策辅助系统","智能数据分析","共享","机器学习","语义搜索","生物识别技术","人脸识别","语音识别","身份验证","人物画像","精准匹配","定制","敏捷化"]
nums = 0
for wd in cKu:
for word,val in counts.items():
# print(f"{word} = {val}")
if wd == word:
nums += val
print(f"词频数: {nums}")
print("取对数后: {:.4f}".format(np.log(nums)))
# 结尾保留了4位小数
# 主函数
if __name__ == '__main__':
fun()三、终制版代码
要实现需求就需要对上述两种操作分别先后进行,比较不便,为了更加方便大量统计、计算并使用,将上述两模块结合在一起,就是终制版
源代码如下:
import pyocr
import importlib
import sys
import time
import jieba
import numpy as np
importlib.reload(sys)
time1 = time.time()
# print("初始时间为:",time1)
import os.path
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
text_paths = r'南京2020 年年度报告'
text_path = f'银行\\南京银行\\{text_paths}.pdf'
text_path2 = f'银行\\南京银行\\TXT\\{text_paths}'
def parse():
'''解析PDF文本,并保存到TXT文件中'''
print("------开始转换------")
fp = open(text_path, 'rb')
# 用文件对象创建一个PDF文档分析器
parser = PDFParser(fp)
# 创建一个PDF文档
doc = PDFDocument()
# 连接分析器,与文档对象
parser.set_document(doc)
doc.set_parser(parser)
# 提供初始化密码,如果没有密码,就创建一个空的字符串
doc.initialize()
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 创建PDF,资源管理器,来共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释其对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
# 循环遍历列表,每次处理一个page内容
# doc.get_pages() 获取page列表
for page in doc.get_pages():
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
# 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象
# 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等
# 想要获取文本就获得对象的text属性,
for x in layout:
if (isinstance(x, LTTextBoxHorizontal)):
with open(f'{text_path2}.txt', 'a',encoding='utf-8') as f:
results = x.get_text()
print(results)
f.write(results + "\n")
f.close()
print("------转换完成------")
# ------------------二---------------
def fun():
# 读取文本
txt = open(f"{text_path2}.txt", "r", encoding='utf-8').read()
# 使用精确模式对文本进行分词
words = jieba.lcut(txt)
# 通过键值对的形式存储词语及其出现的次数
counts = {}
for word in words:
# 去掉词语中的空格
word = word.replace(' ', '')
# 如果词语长度为1,则忽略统计
if len(word) == 1:
continue
# 进行累计
else:
counts[word] = counts.get(word, 0) + 1
# # 将字典转为列表
# items = list(counts.items())
# # 根据词语出现的次数进行从大到小排序
# items.sort(key=lambda x: x[1], reverse=True)
# 查找指数词(自定义词库)
cKu = ["人工智能","网联","平台","智能穿戴","智慧农业","智能风控","智能交通","智能医疗","智能客服","智能投顾","智能柜台","数字营销","数字金融","Fintech","金融科技","量化金融","开放银行","API","网银","私人银行","场景","供应链金融","数字普惠金融","互联网金融","手机银行","APP","NFC支付","移动支付","手机支付","第三方支付","电子商务","私人银行","B2B","B2C","C2B","C2C","O2O","大数据","数字挖掘","信息科技","文本挖掘","数据可视化","异构数据","征信","增强现实","混合现实","虚拟现实","数据分析","IT","物联网","信息物理系统","私有云","公有云","云计算","流计算","图计算","内存计算","多方安全计算","类脑计算","绿色计算","认知计算","融合架构","亿级并发","EB级存储","区块链","数字货币","分布式记账","分布式计算","差分隐私技术","智能金融合约","商业智能","图像理解","投资决策辅助系统","智能数据分析","共享","机器学习","语义搜索","生物识别技术","人脸识别","语音识别","身份验证","人物画像","精准匹配","定制","敏捷化"]
nums = 0
for wd in cKu:
for word,val in counts.items():
# print(f"{word} = {val}")
if wd == word:
nums += val
print(f"词频数: {nums}")
print("取对数后: {:.4f}".format(np.log(nums)))
if __name__ == '__main__':
parse()
time2 = time.time()
print("总共消耗时间为:", time2 - time1)
fun()当然,在读取操作目标名字方法main仍有诸多不便,因此可以加上读取文件夹下所有文件名,再使用列表将其循环遍历操作便可解决这个问题,后续有时间可以再写一写
读取指定路径下所有文件:
import os
filePath = 'D:\\pythonProject\\数据分析\\银行\\兴业银行'
# 文件路径
fileNames = os.listdir(filePath)
# 获取的路径下文件名称列表形式存到fileNames
print(fileNames)
# 打印
print('---------')
for name in fileNames:
print(name)以上
Love for Ever Day