Redis 缓存主要缓存穿透、缓存击穿与缓存雪崩异常场景,今天我们来讲讲缓存穿透。
1 场景描述缓存穿透是指客户端请求一个缓存和数据库中都不存在的 key。由于缓存中不存在,所以请求会透过缓存查询数据库;由于数据库中也不存在,所以也没办法更新缓存。因此下一次同样的请求还是会打在数据库上。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rTTMZouO-1658043901261)(https://p6-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/685dc92d1d694f18bd800fa5a9e54cc7~tplv-k3u1fbpfcp-watermark.image?)]](http://img.558idc.com/uploadfile/allimg/boke/ec01e6ae32f14eb9b58dc0da9e7b1226.png)
好像缓存被穿透了一样,缓存形如虚设。所有的压力都在数据库之上,如果请求量巨大,可能造成数据库崩溃。
2 解决方法缓存穿透有以下几种解决方法。
2.1 接口校验在请求入口进行校验,比如对用户进行鉴权、数据合法性检查等操作,这样可以减少缓存穿透发生的概率。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v0rijt3m-1658043946064)(https://p1-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/37f5d0d7ffc6440c800479677f03e1b2~tplv-k3u1fbpfcp-watermark.image?)]](http://img.558idc.com/uploadfile/allimg/boke/54ee357ecc5d4764ae8ec4ba9c5b0ea9.png)
这种方式减轻了对 Redis 以及数据库的压力,但是增加了客户端的编码与维护的工作量。如果请求的入口很多,那么工作量很大。
2.2 缓存空值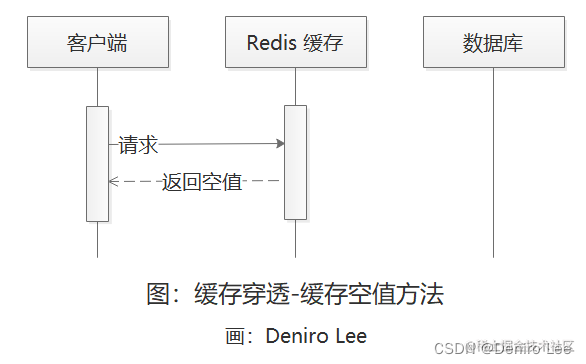
当缓存与数据库中都没有 key 时,就设置一个空值写入缓存,并同时设置一个比较短的过期时间。由于在缓存中设置空值,所以请求在缓存这一级别就返回,也就不会被穿透。这些所说的不会被穿透只是针对某个 key 而言的。其它没有设置空值的 key,仍然存在被穿透的可能。
该方法的问题是:由于不存在的 key 几乎是无限,不可被穷举的,所以不可能都设置到缓存中。而且大量这样的空值 key 设置到缓存,也会占用大量的内存空间。
解决:采用下面提到的布隆过滤器直接过滤掉不存在的 key。
2.3 布隆过滤器布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于判断一个元素是否在一个集合中2。
布隆过滤器的特点是判断为不存在的,则一定不存在;判断存在的,则大概率存在。
2.3.1 布隆过滤器原理布隆过滤器的原理是当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想3。
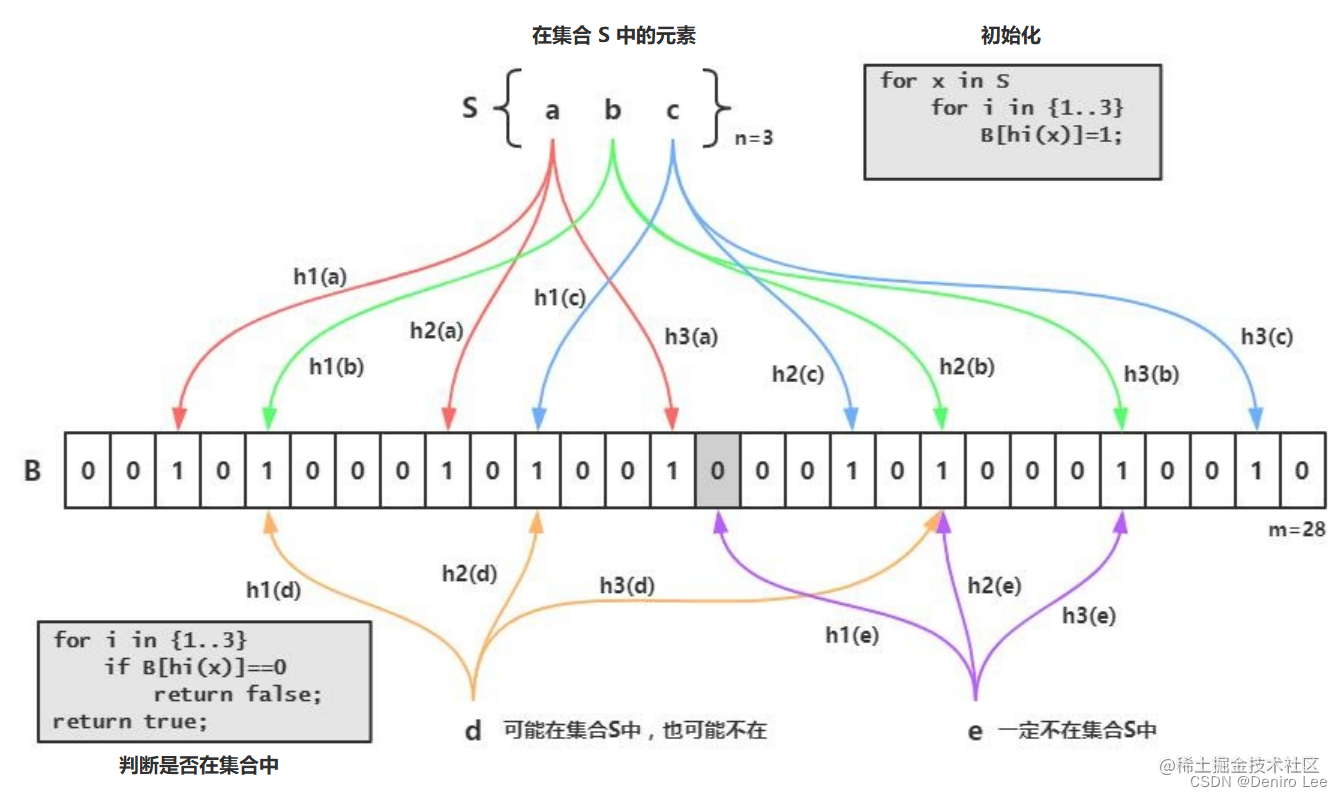
假设有这样一个集合 S,它包含 a b c 三个元素。那么布隆过滤器会利用多个哈希函数(图中是三个哈希函数 h1、h2、h3)来计算所在的位,然后将该位设置为 1。比如元素 a,经过三个哈希函数计算后,将相应的位设置为 1,也就是图中的红线。元素 b 和 c 也是按照相应的方法进行计算处理。这时布隆过滤器初始化完毕。
假设有一个元素 d,需要判断它是否在我们刚才所创建的布隆过滤器中(图中的黄色线条)。经过三个哈希函数 h1、h2、h3 计算后,发现相应的位都是 1,布隆过滤器会返回 true。也就是认为这个元素可能在,也可能不在集合中。看到这里,有同学就会问:“既然这个布隆过滤器都不知道这个元素是不是在集合中,对我们有什么用呢?”
布隆过滤器的强大之处是可以利用较小的缓存,就可以判断出某个元素是否不在集合中。比如又来了一个元素 e,经过三个哈希函数 h1、h2、h3 计算后,发现 h1(e) 所对应的位是 0。那么这个元素 e 肯定不在集合中。有同学又说了:“我用 HashMap 不是也能判断出某个元素在不在集合中呀?”
HashMap 是可以判断,但需要存储集合中所有的元素。如果集合中有上亿个元素,那么就会占用大量的内存。内存空间毕竟是有限,可能还不一定放的下这么多的元素。与 HashMap 相比, 布隆过滤器占用的空间很小,所以很适合判断大集合中某个元素是否不存在。
之前的示例中可以看出,布隆过滤器判断为不存在的元素,则一定不存在;而判断存在的元素,则大概率存在。也就是说,有的元素可能并不在集合中,但是布隆过滤器会认为它存在。这就涉及到一个概念:误识别率。误识别率指的错误判断一个元素在集合中的概率。
假设布隆过滤器有 m bit 大小,需要放入 n 个元素,每个元素使用 k 个哈希函数,那么它的误识别率如下表所示4。
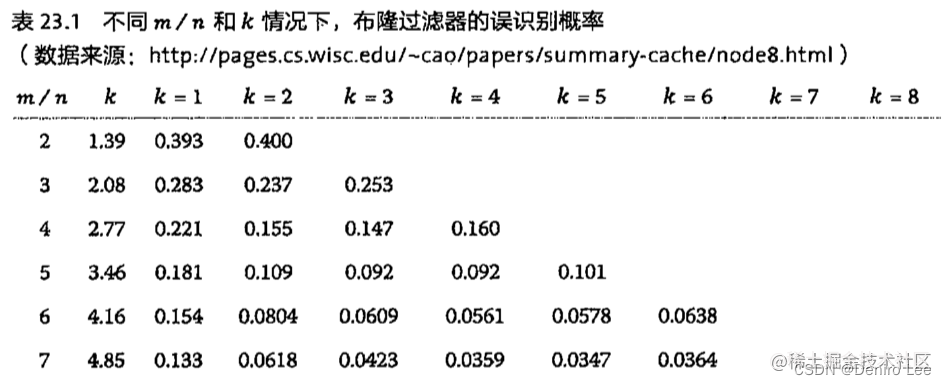
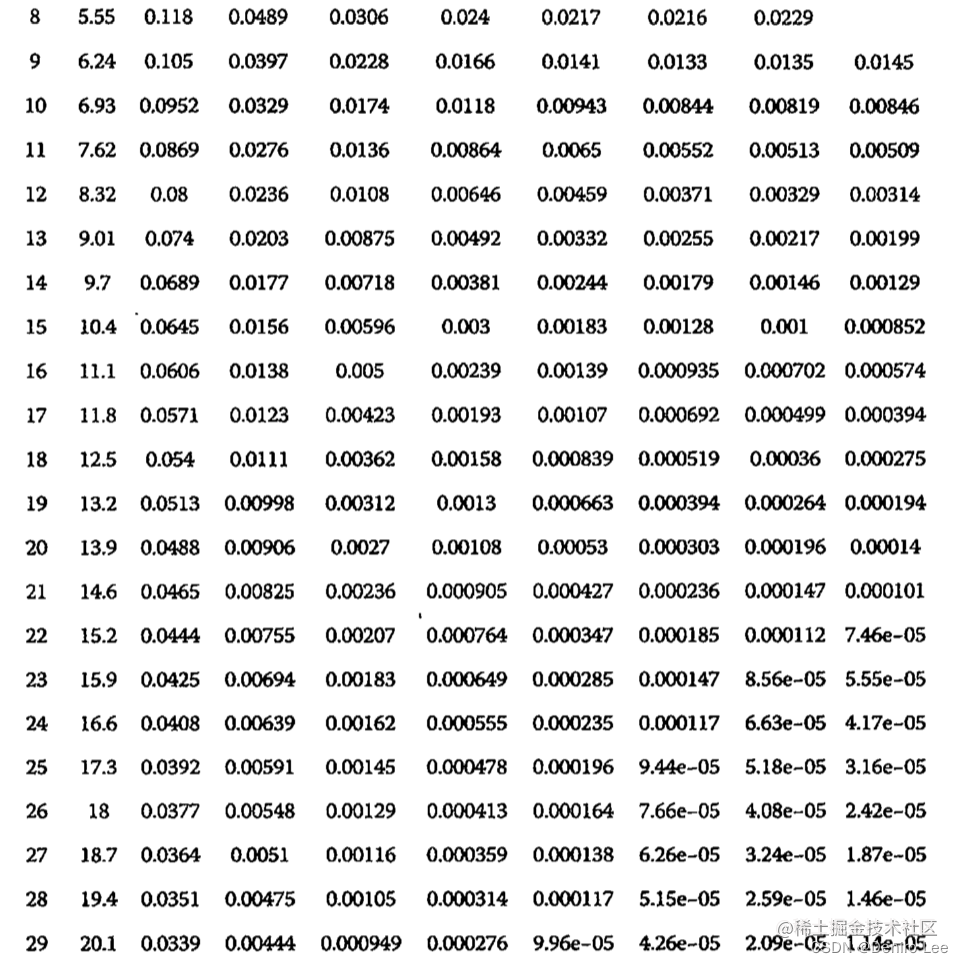
Google 的 Guava 库提供了使用布隆过滤器的 API 类(BloomFilter.class),它是线程安全的。
首先创建布隆过滤器:
//创建存储整型的布隆过滤器
bloomFilter =
BloomFilter.create(Funnels.integerFunnel(), expectedInsertions, fpp);
创建布隆过滤器的方法有以下几个入参:
Funnel 类定义了如何把一个具体的对象类型分解为原生字段值,从而将值分解为 Byte 以供后面 BloomFilter 进行 hash 运算5。也就是说 Guava 的布隆过滤器会根据Funnel 类的定义,计算一个对象的哈希值,放入过滤器。
Guava 官方提供了这样一个创建可插入自定义类的布隆过滤器示例。
首先创建一个 Person 类:
@Data
@AllArgsConstructor
public class Person {
private String firstName;
private String lastName;
private int age;
}
然后创建一个 PersonFunnel 类,它实现了 Funnel 类中的 funnel(Person from, PrimitiveSink into) 方法:
public class PersonFunnel implements Funnel<Person> {
@Override
public void funnel(Person from, PrimitiveSink into) {
into.putUnencodedChars(from.getFirstName()).putUnencodedChars(from.getLastName()).putInt(from.getAge());
}
}
这个方法主要是把 Person 类中的各个属性(名字、年龄)写入 PrimitiveSink 对象。 PrimitiveSink 提供了支持各种写入类型的方法:
接着把元素放入布隆过滤器:
bloomFilter.put(new Person("deniro","lee",20));
bloomFilter.put(new Person("lily","lee",16));
最后就是判断某个元素是否在布隆过滤器中:
Assert.assertFalse(bloomFilter.mightContain(new Person("jack","lee",20)));
Assert.assertTrue(bloomFilter.mightContain(new Person("deniro","lee",20)));
Funnels 是个工具类,内置了一些创建基本类型的 Funnel:
我们可以利用这些 Funnel,来创建包含基本类型元素的布隆过滤器,比如创建一个包含整型元素的布隆过滤器:
BloomFilter<Integer> bloomFilter =
BloomFilter.create(Funnels.integerFunnel(), size, fpp);
最后,让我们总结一波。
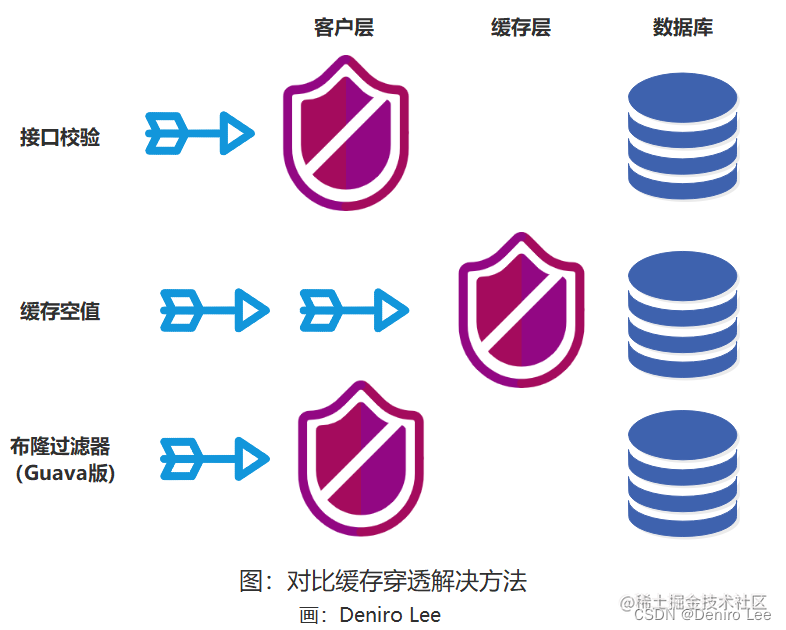
可以看到接口校验方法与 Guava 版的布隆过滤器方法都是在客户侧进行处理。布隆过滤器也可以在缓存层进行处理。相对来说,布隆过滤器方法比接口校验方法少了很多代码量与维护成本。缓存空值不可取,毕竟内存空间是有限的。
利用布隆过滤器,我们可以拦截绝大多数不存在的 key,因此很适合解决 Redis 缓存穿透问题。
参考资料:
- 缓存穿透、缓存击穿、缓存雪崩解决方案
- 布隆过滤器
- 大数据量下的集合过滤—Bloom Filter
- 吴军. 数学之美.第2版[M]. 人民邮电出版社, 2014. p208-209.
- 结合Guava源码解读布隆过滤器