1 分析网站结构
新华网网址:新华网_让新闻离你更近 (news.cn)
新华网的首页是带有关键词搜索功能的,我们尝试在搜索栏随意搜索一个关键词

可以发现新华网一次最多可以爬取的数据是10000条,且其数据是通过分页显示的

2 分析网页具体组成
在搜索后的显示页面按下F12进入开发者页面,切换到NetWork(网络),然后按下Ctrl+R 刷新页面,可以看到网页的各种请求。
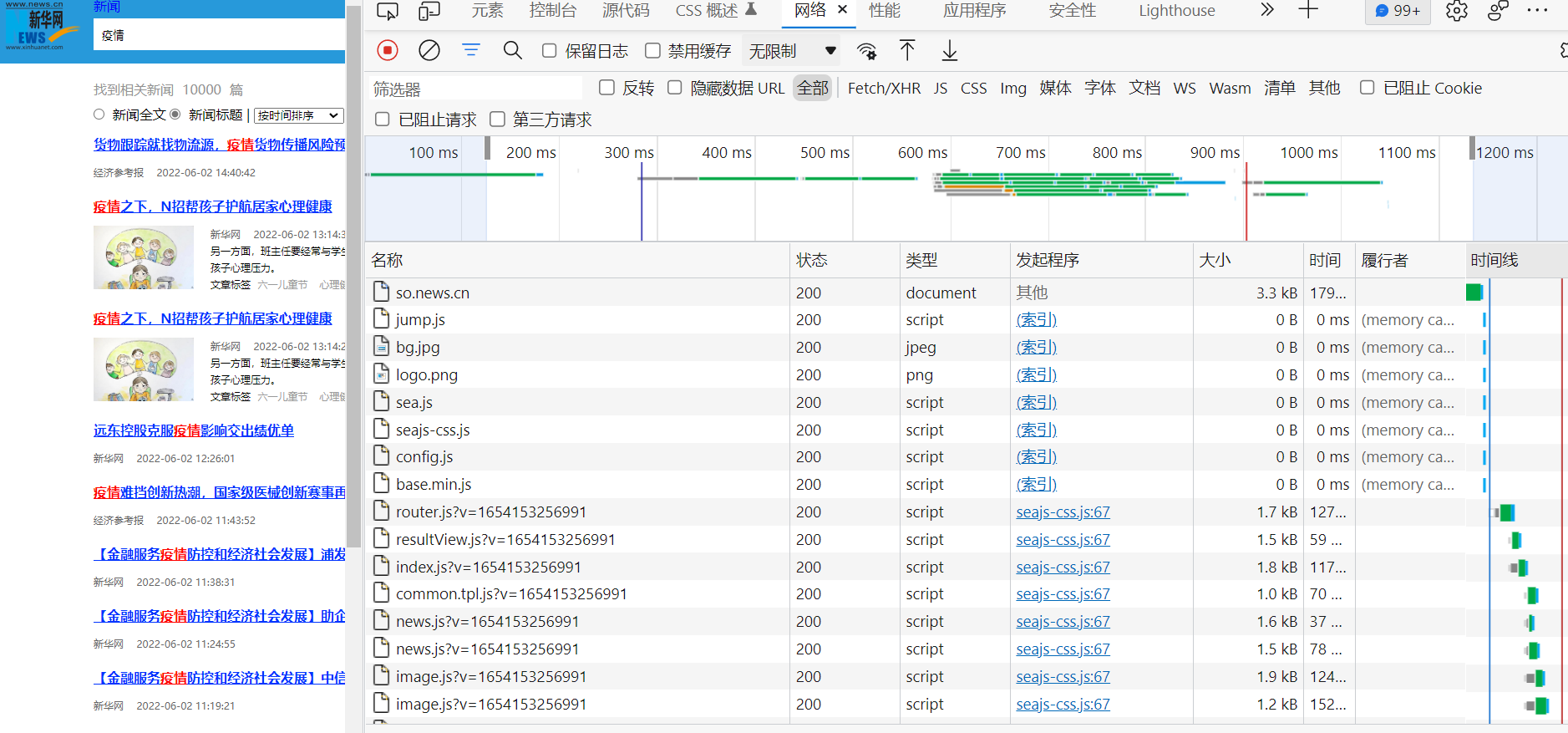
一般情况下服务器返回的数据有HTML和JSON格式的数据:
HTML:一般是选中筛选器中的(DOC)文档,然后点击其请求,最后点击Response(响应)。可以看到服务器的响应输出都是HTML格式的。
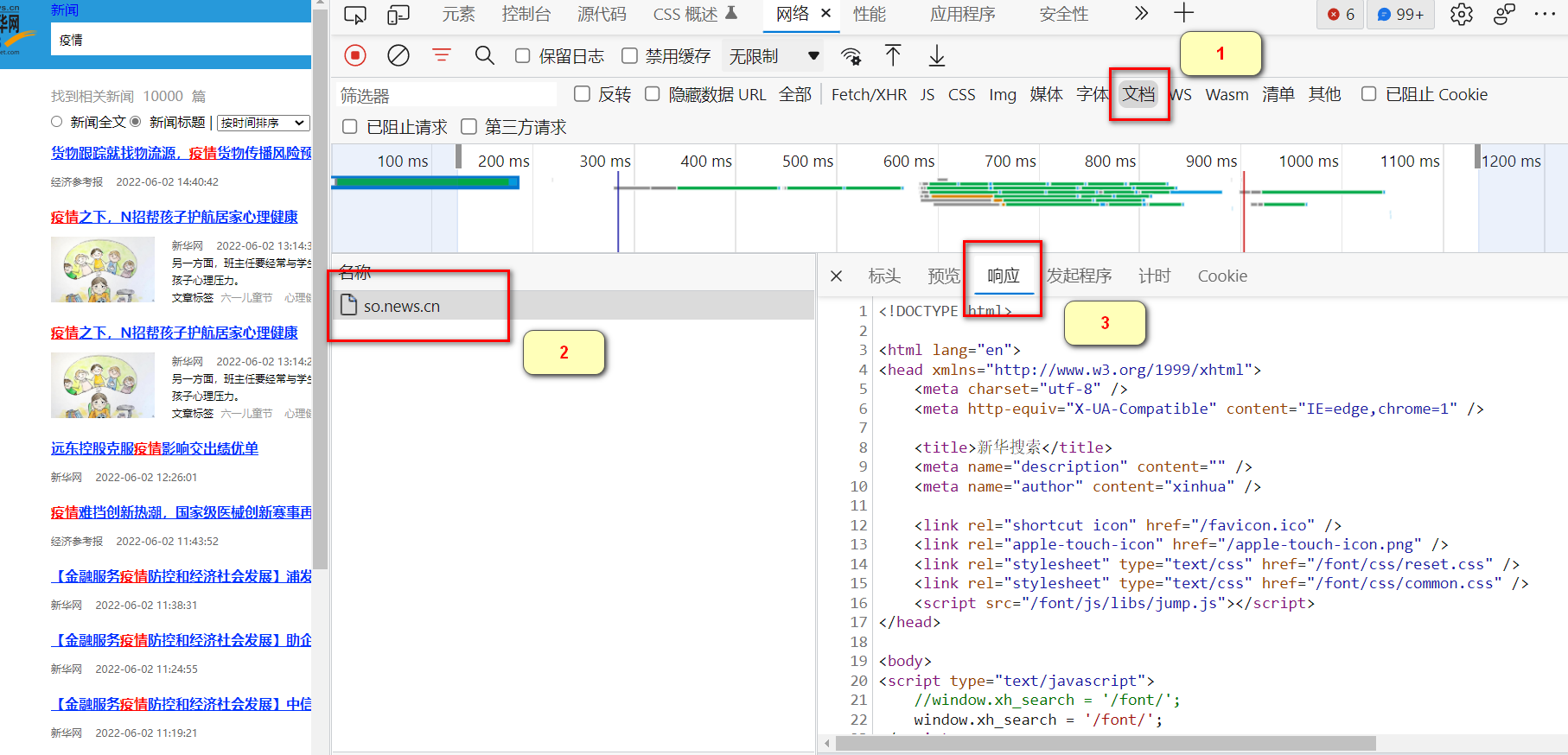
对于这种的爬取可以先定位需要的数据的位置(用左上角的小箭头),然后使用正则表达式 ,BeautifulSoup , xpath 等等把需要的数据解析出来。
本次使用的是下面一种响应的数据格式。
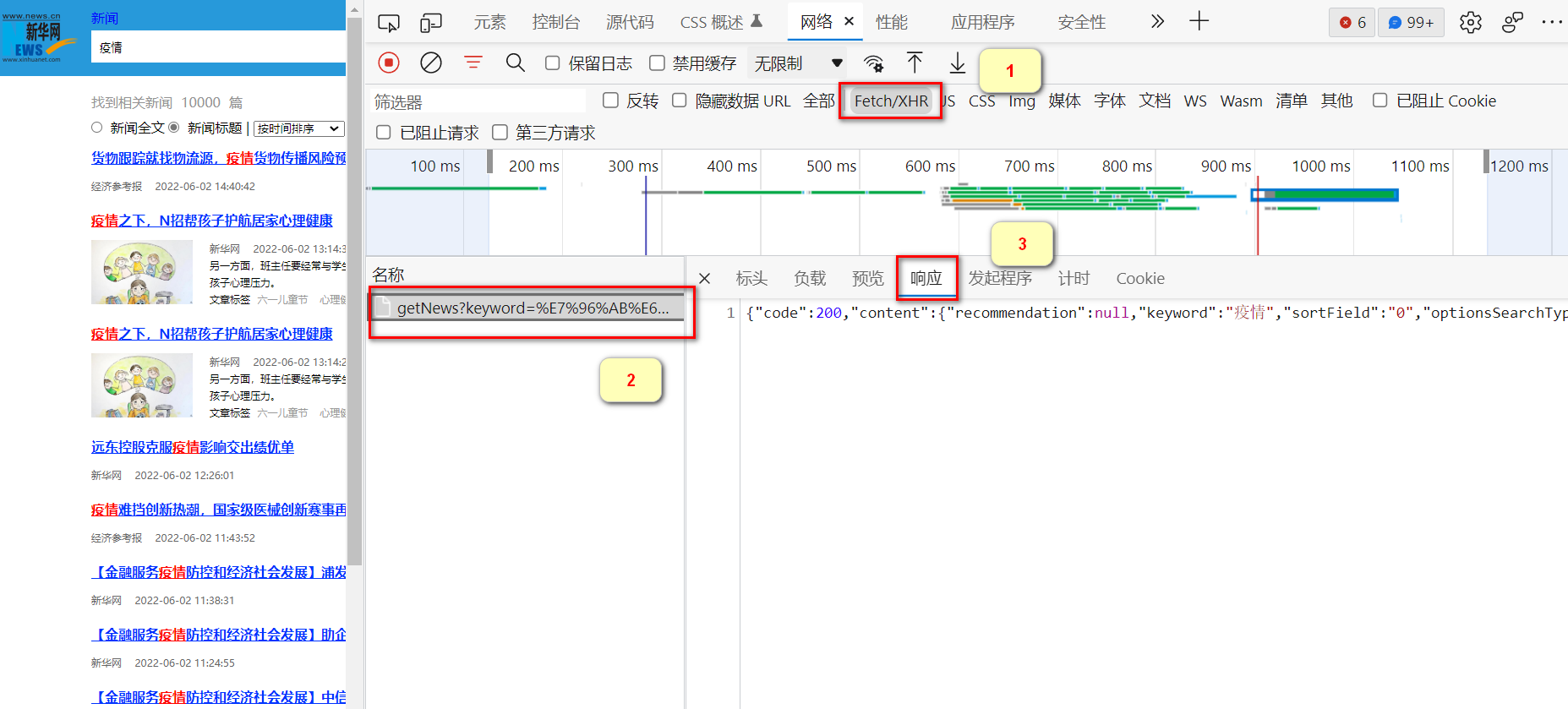
JSON:某些时候,数据并不一定是放在HTML的标签中的,而是通过其他的数据接口,动态的请求加载进去的(Ajax),一般这种数据的请求类型是XHR,而数据的格式是JSON。
可以在筛选器中选择XHR,然后点击其请求,最后点击Response(响应)。可以看到服务器的响应输出是JSON格式(键值对构成)的。
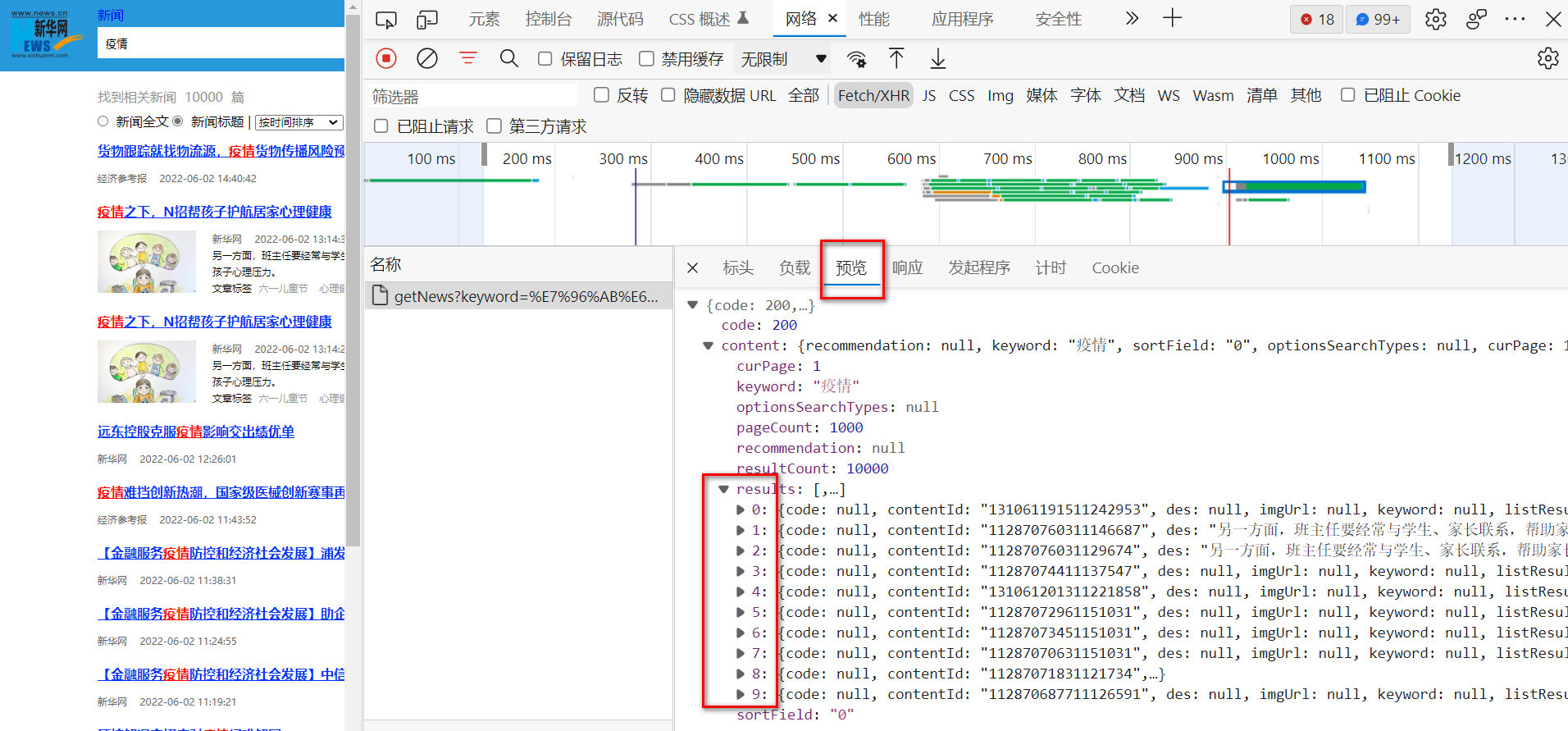
同时点击预览(Preview),可以看见其一页中的十条数据在results列表中以字典的形式存在,后续就可以在其服务器响应的数据中,在results列表中循环的爬取一页中的每一条数据。
3 爬虫构建思路
我们回到爬虫的构建中来。点击标头可以发现其请求方法是GET请求,请求的参数可以在URL中构建。
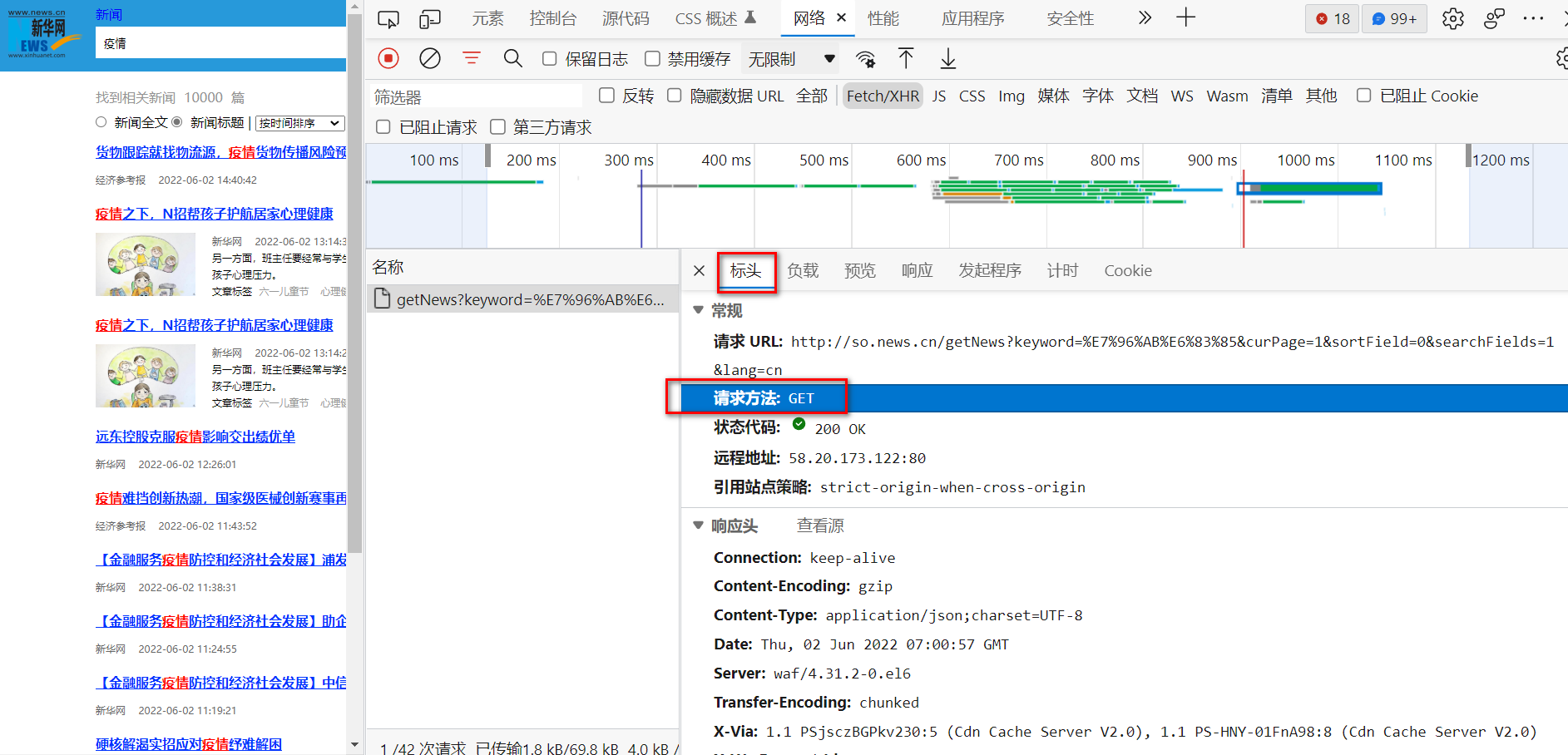
请求 URL:
http://so.news.cn/getNews?keyword=疫情&curPage=1&sortField=0&searchFields=1&lang=cn
通过分析其URL我们可以发现,其keyword就是我们的爬取的关键词“疫情”,只不过这里被按照UTF-8的格式进行编码了,UTF-8中,一个汉字对应三个字节,当然不同的网站编码不一定相同,还有按照GB2312编码的,一个汉字占用两个字节。
curPage就是我们目前所处的页数,这里就是第一页的意思。其他的参数我们可以不去考虑,这个和我们的爬虫的关系不是很大。
这里的爬虫思路可以分为两个:
第一个就是首先构建每一页的url,然后对每一页的url的response进行解析,并将数据存库(或者存本地)
第二就是首先将每一页的url构建后并存在redis中,然后利用分布式爬虫从redis中取url并进行response的解析与数据存库。
对于新华网我们采用第二种方式,而在人民网的爬取中,我们采用第一种方式。
4 具体实现
各个页面的url的构建和url存redis
在整个Scrapy项目种运行上述代码,就可以将当前关键词或者关键词组的对应的每一页的url存在Redis中,后续就可以进行多机器取url爬取,增加爬取速度,或者实现断点续爬等功能。
#!/usr/bin/env python
# encoding: utf-8
import redis
import json
import time
from scrapy import Spider
from scrapy.crawler import CrawlerProcess
from scrapy.http import Request
from scrapy.utils.project import get_project_settings
class XinhuaNewsSearchSpider(Spider):
name = "xinhua_news_search_spider"
conn = redis.Redis(host="xx.xx.xx.xx", port=6379, password="xxxx") # 链接Redis
xinhua_news_url = "http://www.xinhuanet.com/"
def __init__(self, keywords=None, *args, **kwargs):
super(XinhuaNewsSearchSpider, self).__init__(*args, **kwargs)
self.keywords = keywords
def start_requests(self):
keys = self.keywords.split("、")
for key in keys:
xinhua_search_url = "http://so.news.cn/getNews?keyword=%s&curPage=1&sortField=0&searchFields=0&lang=cn" % key
yield Request(xinhua_search_url, callback=self.xinhua_parse)
def xinhua_parse(self, response):
data = json.loads(response.text)
attr = response.url.split("curPage=1")
pageCount = int(data['content']['pageCount']) #获得当前的总页数
for page in range(1, pageCount + 1): #将所有页码对应的页面的url提取出来并保存
url = attr[0] + "curPage=" + str(page) + "&sortField=0&searchFields=0&lang=cn"
self.conn.lpush("xinhua_news_search_spider:start_urls", url)
if __name__ == "__main__":
keys = '防疫、疫情、新冠'
process = CrawlerProcess(get_project_settings())
process.crawl('xinhua_news_search_spider', keywords=keys)
process.start()
print("xinhua-search执行完毕")
页面数据的爬取
等待上一步工作完成,就可以运行下面的代码,就可以将每一页的数据源源不断的爬取到你设置的位置
这里的爬取到的数据存入了数据库,需要在Scrapy的项目中设置好数据库的相关参数。
import re
import json
import redis
from scrapy import Spider
from scrapy.crawler import CrawlerProcess
from scrapy.selector import Selector
from scrapy.http import Request
from scrapy.utils.project import get_project_settings
from scrapy_redis.spiders import RedisSpider
from newsSpider.items import NewInformationItem_xinhua
from datetime import datetime
""""如果一个关键词相关的新闻总数超过10000,则只能查询前10000条数据。目前最多只能查询以时间为顺序的前10000条数据"""
class Xinhua_News_Info_Spider(RedisSpider):
name = "xinhua_news_info_spider"
# 相对于scrapy设置的start_urls,在scrapy_redis中只需要设置redis_key就可以了,
# 爬虫会自动去redis的相应的key中取到url,然后包装成Request对象,保存在redis的待爬取队列(request # queue)中。
redis_key = "xinhua_news_search_spider:start_urls"
def __init__(self, keywords=None, *args, **kwargs):
super(Xinhua_News_Info_Spider, self).__init__(*args, **kwargs)
""" 解析响应 """
def parse(self, response):
text = "".join([response.text.strip().rsplit("}", 1)[0], "}"])
data = json.loads(text)
for item in data['content']['results']:
new_information = NewInformationItem_xinhua() # 每一个item都是一条新闻的信息
timeArray = str(item['pubtime']).split(' ')[0] # 取出新闻发布时间的年月日
new_information['title'] = re.sub("<font color=red>|</font>| |&quo|&", "", item['title']) #  这些是HTML转义字符
new_information['url'] = item['url']
new_information['author'] = item['sitename']
new_information['create_time'] = item['pubtime']
new_information['origin'] = "新华网"
dt = datetime.now()
new_information['crawl_time'] = dt.strftime('%Y-%m-%d %H:%M:%S')
if item['keyword'] is None:
new_information['keyword'] = " "
else:
new_information['keyword'] = re.sub("<font color=red>|</font>", "", item['keyword'])
yield Request(new_information['url'], callback=self.parse_content, dont_filter=True, meta={'new_item': new_information})
def parse_content(self, response):
new_item = response.meta['new_item']
selector = Selector(response)
"""每个网页的内容有不同的id或class"""
"""每个网页的结构不相同,无法将所有的网页爬取到"""
article = selector.xpath('//p//text()').extract()
new_item['article'] = '\n'.join(article) if article else ''
if article is None or str(article).strip() == "": #str(article).strip():是把article的头和尾的空格,以及位于头尾的\n \t之类给删掉。
print(response.url)
else:
yield new_item
if __name__ == "__main__":
conn = redis.Redis(host="192.168.1.103", port=6379, password="root")
print("url数量:" + str(conn.llen('xinhua_news_search_spider:start_urls')))
process = CrawlerProcess(get_project_settings())
process.crawl('xinhua_news_info_spider', keywords=keys)
process.start()
1 分析网站结构
人民网网址:人民网_网上的人民日报 (people.com.cn)
同样的,人民网的首页也是带有关键词搜索功能的,我们搜索栏随意搜索一个关键词
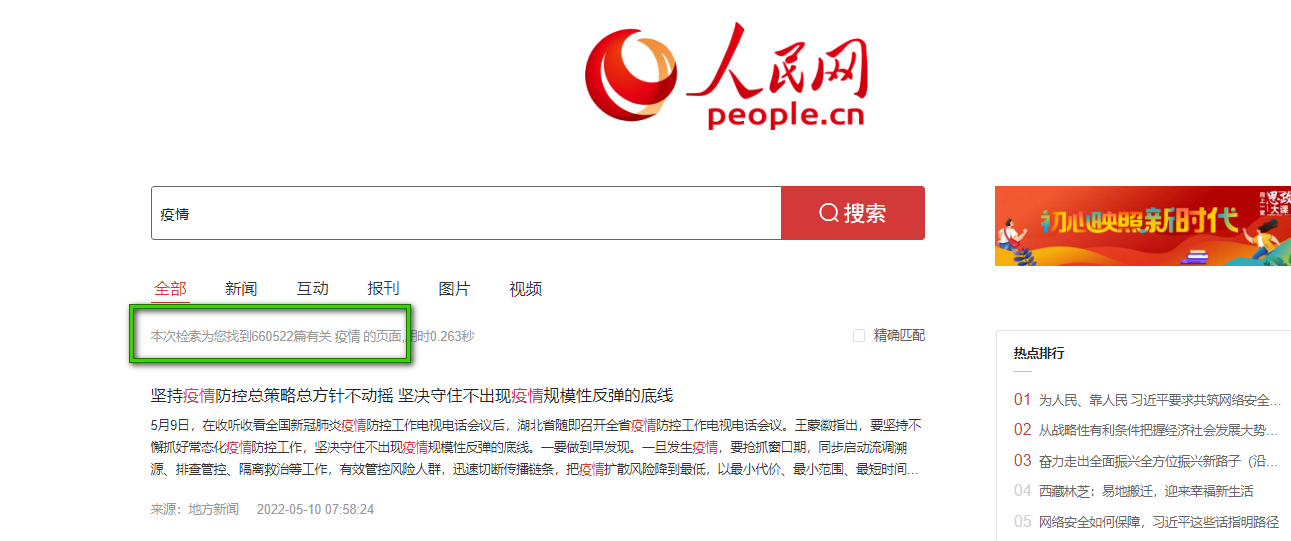
可以发现其显示的数据的形式也是分页显示的,同时我们发现其显示搜索到的数据是660522条,这个不是我们可以爬取的实际的数据大小,在人民网我们实际可以爬到的最大的数据量还是10000条,这个后续再说明。
2 分析网页具体组成
这个在新华网的爬取部分已经简单介绍过了,就不再次说明了。同时我们本次爬取的数据格式还是按照JSON来获取。
3 爬虫构建思路
我们按下F12进入开发者页面,过滤器选中XHR,并点击search请求,再点击Header(标头),可以发现与新华网不同的是,其是POST请求,其url中并不携带参数,而是通过一个单独的参数列表进行参数的传递。
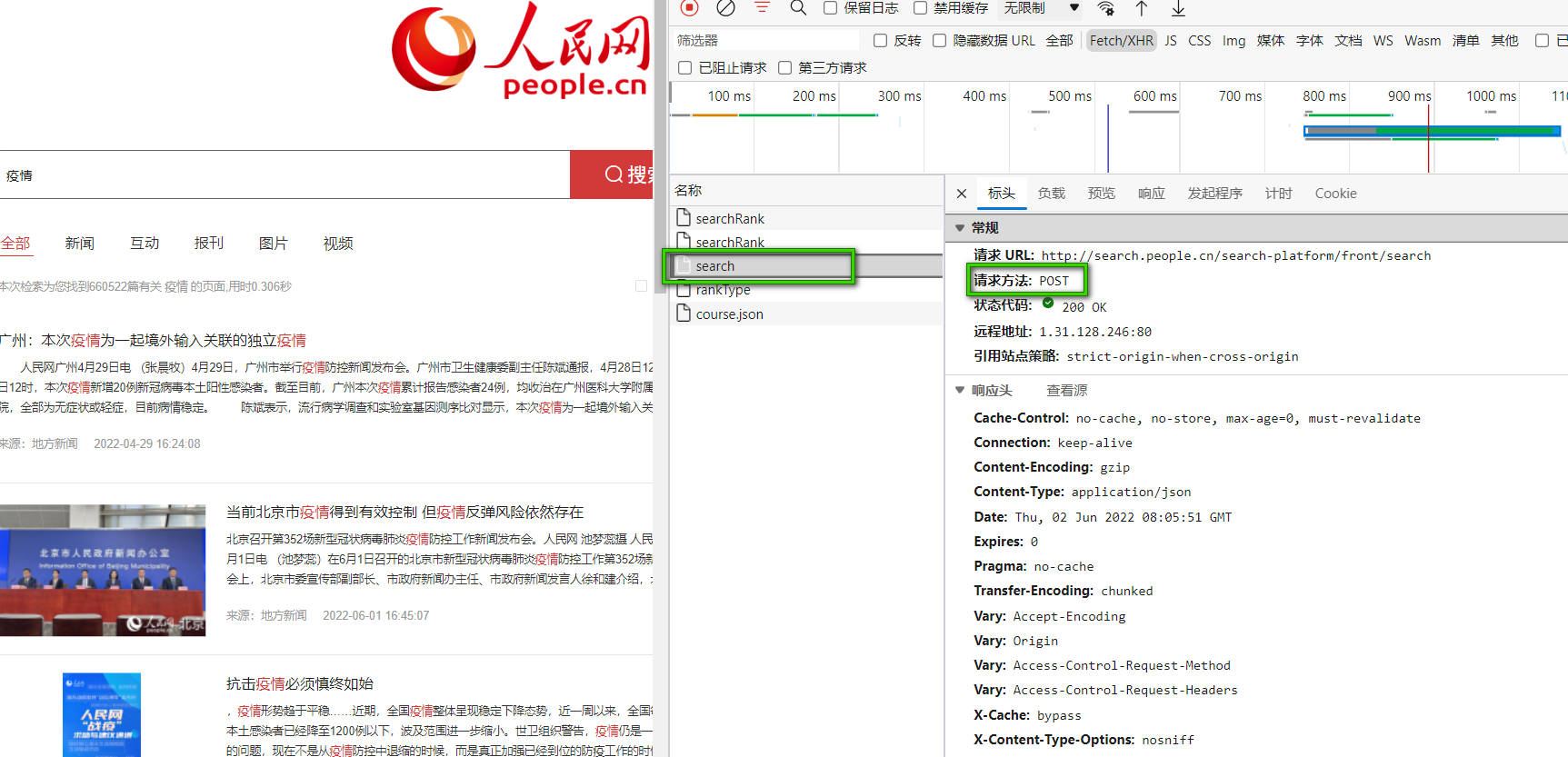
这里的爬虫思路也可以分为两个:
第一个就是首先构建每一页的request(基础的url加上请求的参数),然后对每一页的request的response进行解析,并将数据存库(或者存本地)
第二就是首先将每一页的每一页的request构建后并存在redis中,然后利用分布式爬虫从redis中取request并进行response的解析与数据存库。与新华网爬虫不同的是,redis中只能直接存url,而post请求需要有请求的url和其携带的请求参数,所以要直接间request存入redis 是行不通的,解决办法可以通过重写scrapy-redis中的make_request_from_data方法,让其可以重新将我们的url和请求参数包装成request,并向服务器请求。具体的后续再出文章说明吧。
这里我们采用第一种方法来构建人民网爬虫
4 具体实现
POST请求中参数有两个重要的部分:body, headers
body里面承载的是我们的请求参数,在payload(负载)中可以清楚的看见。其中key就是我们的关键词,page就是我们当前的页面。其他的参数我们可以保持不变,对于爬虫影响不大
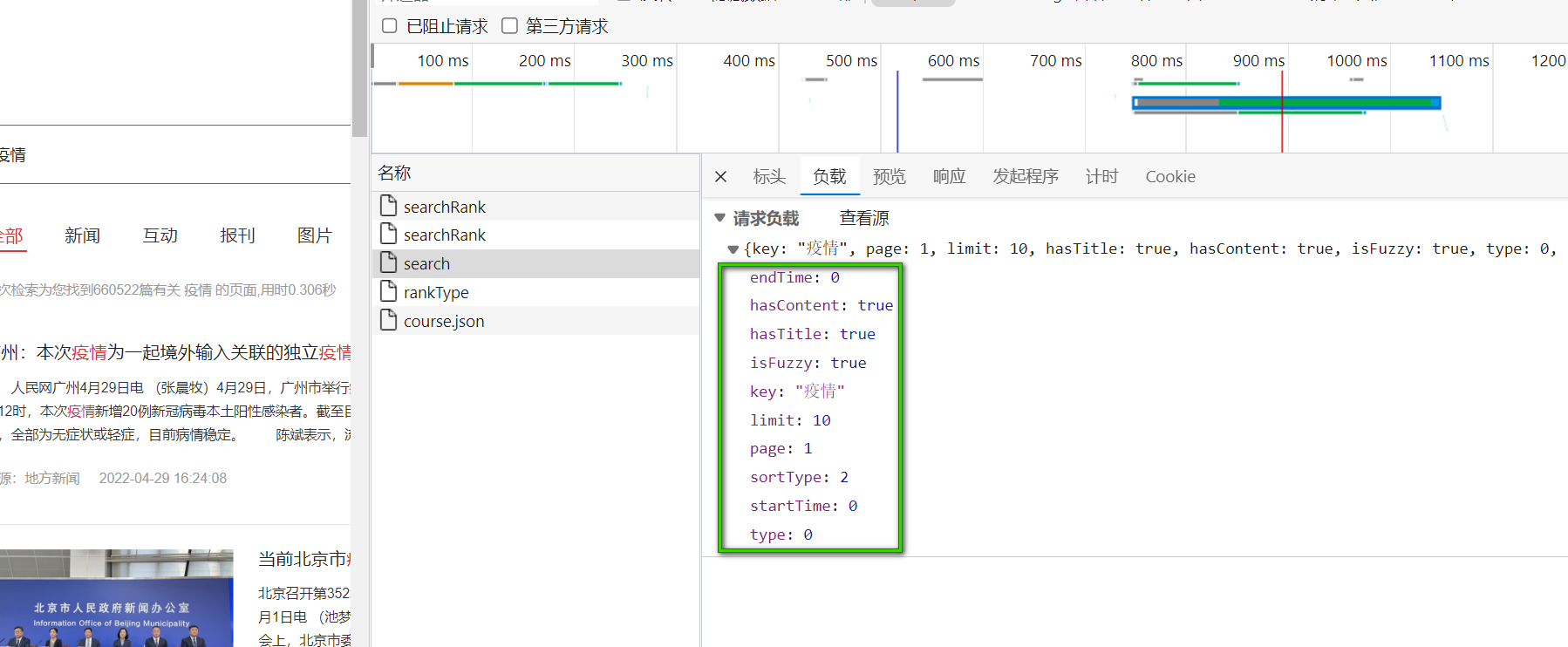
headers可以在headers栏中找到,我们需要的有Accept:希望服务器返回什么样的数据类型;Content-Type:告诉服务器给其传的数据的类型;Referer:告诉服务器该网页是从哪个页面链接过来的。不设置请求可能会被拦截从而获取不到数据。User-Agent:(这个在Scrapy中的setting中设置过了,在代码中不需要再设置一次):将爬虫伪装成浏览器进行请求,防止服务器识别出爬虫从而拦截。
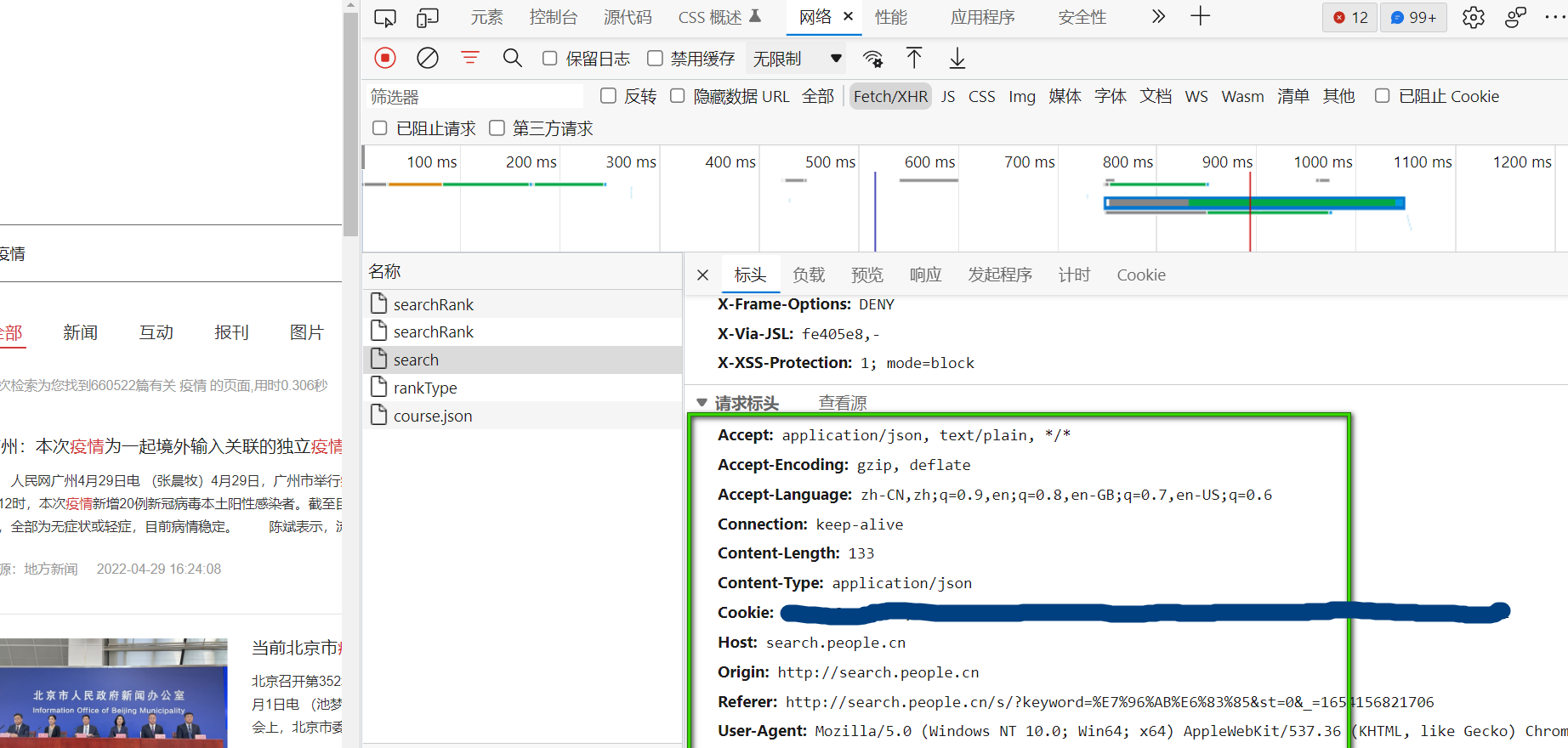
注意: 对于人民网 :1000页以后的数据无法获取,1000页以后的数据都是第一页数据的内容
#!/usr/bin/env python
# encoding: utf-8
import re
import random
import json
import time
import scrapy
from scrapy import Spider
from scrapy.crawler import CrawlerProcess
from scrapy.http import Request
from scrapy.utils.project import get_project_settings
from newsSpider.items import NewInformationItem_people
from datetime import datetime
from bs4 import BeautifulSoup # 解析HTML文本
class PeopleNewsSpider(Spider):
name = "people_news_spider"
people_news_url = "http://www.people.com.cn/"
start_urls = 'http://search.people.cn/search-platform/front/search'
def __init__(self, keywords=None, *args, **kwargs):
super(PeopleNewsSpider, self).__init__(*args, **kwargs)
self.keywords = keywords
self.key = ' '
def start_requests(self):
keys = self.keywords.split("、")
for self.key in keys:
time_ns = int(round(time.time() * 1000))
headers={"Accept": "application/json, text/plain, */*",
"Content-Type": "application/json",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36 Edg/101.0.1210.53",
"Referer": "http://search.people.cn/s/?keyword="+self.key+"&st=0&_="+str(time_ns)
}
data = {"endTime": "0",
"hasContent": "True",
"hasTitle": "True",
"isFuzzy": "True",
"key": self.key,
"limit": "10",
"page": "1",
"sortType": "2",
"startTime": "0",
"type": "0"}
temp=json.dumps(data)
yield scrapy.Request(self.start_urls,method='POST',body=temp,headers=headers,callback=self.people_parse, meta={'time_ns': time_ns})
def people_parse(self, response):
data_news = json.loads(response.text)
print("总共页数 :", data_news['data']['pages'])
print("当前页 :", data_news['data']['current'])
time_ns = response.meta['time_ns']
key_value = self.key
page_flag = 1
while True:
if page_flag < data_news['data']['pages']:
page_flag = page_flag + 1
# 1000页以后的数据无法获取,1000页以后的数据都是第一页数据的内容
if page_flag > 1000:
break
headers={"Accept": "application/json, text/plain, */*",
"Content-Type": "application/json",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36 Edg/101.0.1210.53",
"Referer": "http://search.people.cn/s/?keyword="+key_value+"&st=0&_="+str(time_ns)
}
data = {"endTime": "0",
"hasContent": "True",
"hasTitle": "True",
"isFuzzy": "True",
"key": key_value,
"limit": "10",
"page": page_flag,
"sortType": "2",
"startTime": "0",
"type": "0"}
temp=json.dumps(data)
# 在爬取多关键词时需要延时下,不延时 会出现很多重复数据,这是因为每一页的请求的速度过快,而item持久化的速度较慢,造成数据的覆盖
time.sleep(0.1)
# 每爬1000条数据,随机停几秒(演示用)
if page_flag % 100 == 0:
time.sleep(random.randint(1,10))
yield scrapy.Request(self.start_urls,method='POST',body=temp,headers=headers,callback=self.people_parse_content, meta={'key_value': key_value})
else:
break
def people_parse_content(self, response):
key_value = response.meta['key_value']
data_news = json.loads(response.text)
records = data_news['data']['records']
for item in records:
new_information = NewInformationItem_people() # 每一个item都是一条新闻的信息
new_information['title'] = re.sub("<em>|</em>| |&quo|&", "", item['title']) #  这些是HTML转义字符
new_information['url'] = item['url']
new_information['author'] = item['author']
new_information['create_time'] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(item["displayTime"]/1000))
new_information['origin'] = "人民网"
new_information['point'] = key_value
new_information['keyword'] = re.sub("<em>|</em>| |&quo|&", "", item['keyword'])
dt = datetime.now()
new_information['crawl_time'] = dt.strftime('%Y-%m-%d %H:%M:%S')
new_information['article'] = BeautifulSoup(item["content"], "html.parser").text
new_information['category'] = re.sub("#| |&quo|&", "", item["belongsName"])
yield new_information # 提交到item通道进行持久化
if __name__ == "__main__":
keywords = '防疫、疫情、新冠'
process = CrawlerProcess(get_project_settings())
process.crawl('people_news_spider', keywords=keywords)
process.start()
print("peoplenews-search执行完毕")
1 每个网站的搜索的url或者html标签都有可能改变,在进行爬虫设置的时候,一定要根据各位当时的url进行正确的设置
2 F12进入开发者模式,由于各个浏览器,浏览器的版本各不相同,可能与本文说明的有些许差异,各位可以根据实际情况实际操作
3 各个网站都是存在一定的反爬措施的(新华网和人民网的反爬措施均不强),比如:
爬取频率限制
长时间高频率地爬取数据会被服务器就视为爬虫,对其 IP 进行访问限制,因为正常人访问无法做到这么高强度的访问(比如一秒访问十次网站)。如果要避免可以降低爬取的频率
4 两个完整的爬虫可以见如下,其中数据库相关信息需要填写成各自对应的:
jack-nie-23/Scrapy-Spider: 新华网和人民网的简单关键词Scrapy爬虫 (github.com)