先爬取最新消息列表,再循环爬取对应url中的新闻详细数据 # -*- coding: utf-8 -*- """ Spyder Editor news.py. """ import requests from bs4 import BeautifulSoup from datetime import datetime import json import xlwt def ge
先爬取最新消息列表,再循环爬取对应url中的新闻详细数据
"""
Spyder Editor
news.py.
"""
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import json
import xlwt
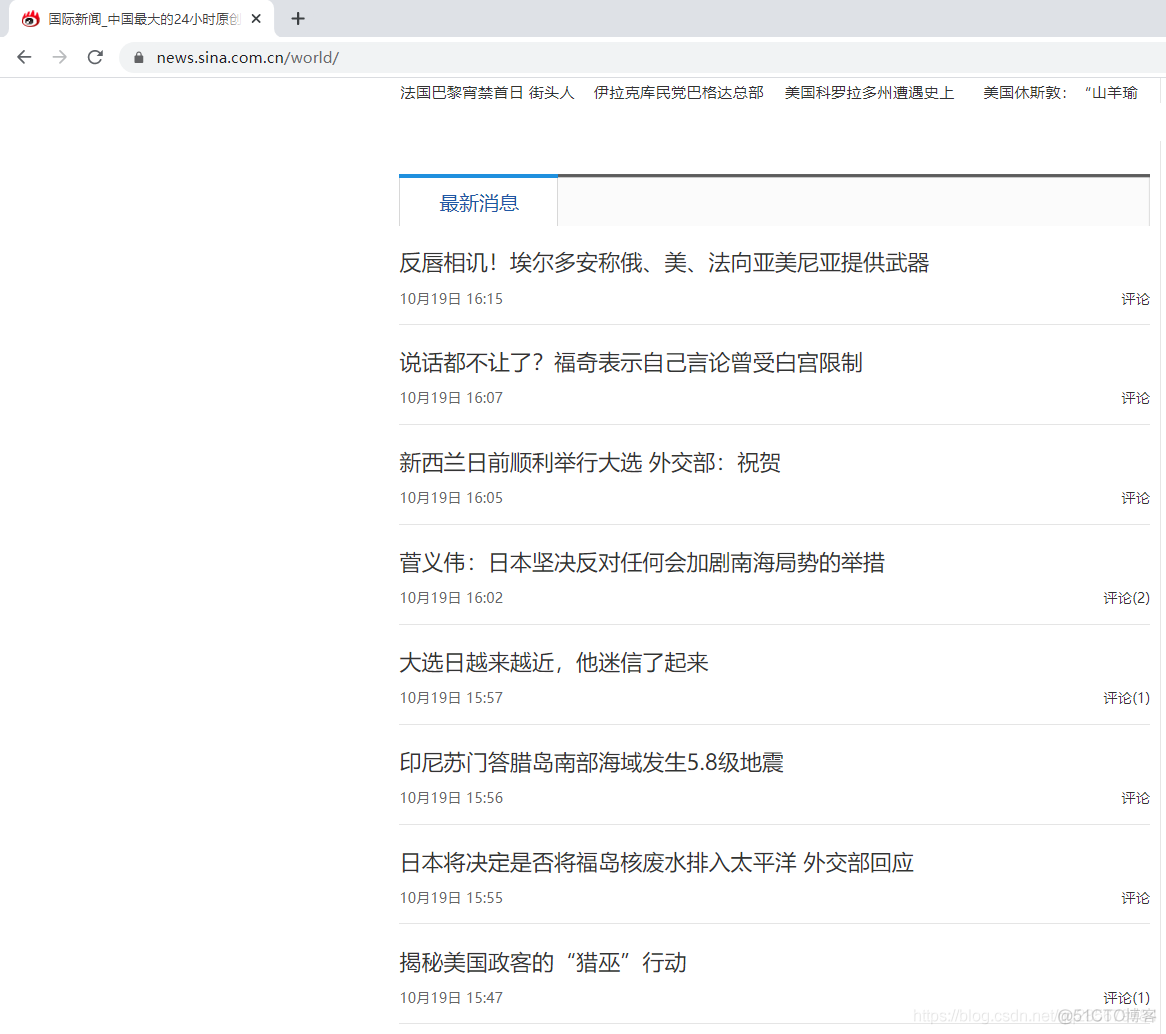
def get_list(url):
# 新闻链接
res=requests.get(url)
res.encoding='utf-8'
# 完整HTML
html=BeautifulSoup(res.text,'html.parser')
# 新闻列表
newList=[]
for item in html.select('.news-item'):
try:
newObj={}
newObj['title']=item.select('h2 a')[0].text
newObj['url']=item.select('h2 a')[0].get('href')
newList.append(newObj)
except:
print('出现异常')
return newList
def get_detail(url):
# 新闻链接
res=requests.get(url)
res.encoding='utf-8'
# 完整HTML
html=BeautifulSoup(res.text,'html.parser')
# 新闻对象
result={}
# 新闻标题
result['title']=html.select('.main-title')[0].text
# 发布时间
timesource=html.select('.date-source span')[0].text
createtime=datetime.strptime(timesource,'%Y年%m月%d日 %H:%M')
createtime.strftime('%Y-%m-%d')
result['createtime']=createtime
# 新闻来源
result['place']=html.select('.date-source a')[0].text
# 新闻内容
article=[]
for p in html.select('#article p')[:-1]:
article.append(p.text.strip())
articleText=' '.join(article)
result['article']=articleText
# 新闻作者
result['author']=html.select('.show_author')[0].text.strip('责任编辑:')
# 新闻链接
result['url']=url
return result
if __name__ == "__main__": #主函数
newList=get_list('https://news.sina.com.cn/world/')
# print(newList)
# newObj=get_detail('http://news.sina.com.cn/c/2020-10-19/doc-iiznctkc6335371.shtml')
# print(newObj)
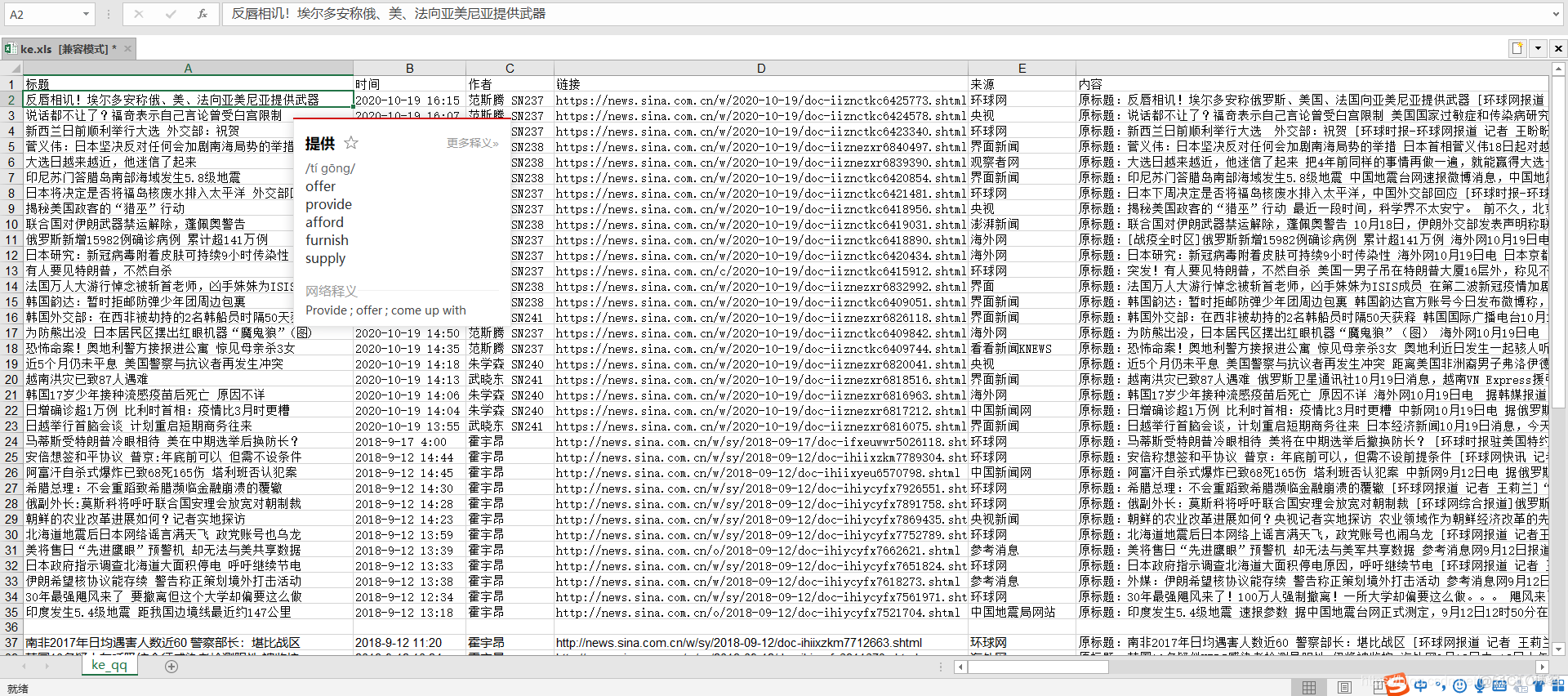
book = xlwt.Workbook(encoding='utf-8')
sheet = book.add_sheet('ke_qq')
head = ['标题','时间','作者','链接','来源','内容'] #表头
for h in range(len(head)):
sheet.write(0,h,head[h]) #写入表头
for i,item in enumerate(newList):
try:
newObj=get_detail(item['url'])
sheet.write(i+1,0,newObj['title'])
sheet.write(i+1,1,newObj['createtime'])
sheet.write(i+1,2,newObj['author'])
sheet.write(i+1,3,newObj['url'])
sheet.write(i+1,4,newObj['place'])
sheet.write(i+1,5,newObj['article'])
print (str(i),'写入成功')
except:
print (str(i),'出现异常')
book.save('F:\ke.xls')