因为该项目从始至今一直在使用GitRunner进行发版,并且基于虚机部署,所以一直没有集成到发版审核平台,但是由于项目比较重要,并且涉及的服务和机器较多,所以必须要把这个项目进行容器化并且统一发版工具才能更好的适应公司的环境,以及更好的应对下一代云计算的发展。
1.2 为什么要弃用Git Runner?
=====================
首先我们看一下Git Runner发版的页面,虽然看起来很简洁清爽,但是也难免不了会遇到一些问题。
1.2.1 多分支并行开发问题
===============
当多分支并行开发或者能够发版到生产环境的分支较多时,很容易在手动部署的阶段点错,或者看串行,当然这种概率很小。
但是我们可以看到另外一个问题,每次提交或者合并,都会触发构建,当我们使用Git Flow分支流时,可能同时有很多分支都在并行开发、并行测试、并行构建,如果Git Runner是基于虚机创建的,很有可能会出现构建排队的情况,当然这个排队的问题,也是能解决的。
1.2.2 多微服务配置维护问题
================
其次,如果一个项目稍微大一些,维护起来也不是很方便。比如这个准备要迁移的项目,一个前端和二十多个业务应用,再加上Zuul、ConfigServer、Eureka将近三十个服务,每个服务对应一个Git仓库,然后每个服务同时在开发的分支又有很多,如果想要升级GitLab CI脚本或者微服务的机器想要添加节点,这将是一个枯燥乏味的工作。
1.2.3 安全问题
==========
最后,还有一个安全的问题,GitLab的CI脚本一般都是内置在代码仓库里面的,这就意味着任何有Push或者Merge权限的人都可以随意的修改CI脚本,这会导致意想不到的结果,同时也会威胁到服务器和业务安全,针对发版而言,可能任何的开发者都可以点击发版按钮,这些可能一直都是一个安全隐患。
但是这些并不意味着Git Runner是一个不被推荐的工具,新版的GitLab内置的Auto DevOps和集成Kubernetes依旧很香。但是可能对于我们而言,使用Git Runner进行发版的项目并不多,所以我们想要统一发版工具、统一管理CI脚本,所以可能其它的CI工具更为合适。
1.3 为什么要容器化?
============
1.3.1 端口冲突问题
============
容器化之前这个项目采用虚机部署的,每个虚拟机交叉的启动了两个或者三个微服务,这会遇到一个问题,就是端口冲突的问题,在项目加入新应用时,需要考虑服务器之间端口冲突问题的,还要考虑每个微服务的端口不能一样,因为使用虚拟机部署应用时,可能会有机器节点故障需要手动迁移应用的情况,如果部分微服务端口一样,迁移的过程可能会受阻。
另外,当一个项目只有几个应用时,端口维护起来可能没有什么问题,像本项目,涉及三十多个微服务,这就会成为一件很痛苦的事情。而使用容器部署时,每个容器相互隔离,所有应用可以采用同样的端口,就无需再去关心端口的问题。
1.3.2 程序健康问题
============
使用过Java程序的人大部分都遇到过程序假死的情况,比如端口明明是通的,但是请求就是不处理,这就是一种程序假死的现象。而我们在使用虚机部署时,往往不能把健康检查做的很好,或许在虚机上面并没有做接口级的健康检查,这就会造成程序假死无法自动处理的问题,并且在虚机上面做一些接口级的健康检查及处理操作并不是一件简单的事情,同样也是一件枯燥乏味的事情,尤其是当一个项目微服务过多,健康检查接口不一致时更为痛苦。
但在k8s上面,自带的Read和Live探针用以处理上面的问题就极其简单,如图所示,我们可以看到目前支持三种方式的健康检查:

-
tcpSocket: 端口健康检查
-
exec: 根据指定命令的返回值
- httpGet: 接口级健康检查
同时这些健康检查的灵活性也很高,可以自定义检查间隔、错误次数、成功次数、检查Host等参数,而且上面提到的接口级健康检查httpGet也支持自定义主机名、请求头、检查路径以及HTTP或者HTTPS等配置,可以看到用k8s自带的健康检查可以省去我们很大一部分工作,不用再去维护非常多令人讨厌的脚本。
1.3.3 故障恢复问题
============
在使用虚机部署应用时,有时可能会碰到宿主机故障,单节点的应用无法使用,或者多节点部署的应用由于其他副本不可用,导致自身压力大出现服务延迟的情况。而恰恰宿主机无法很快恢复,这时可能就需要手动添加节点或者需要新加服务器才能解决这类问题,这个过程可能会很漫长,或许也很痛苦。因为需要去准备依赖环境,然后才能去部署自己的应用,并且有时候你可能还需要更改CI脚本。。。
而使用k8s编排时,我们无需关心这类问题,一切的故障恢复、容灾机制都由强大的k8s负责,你可以去喝杯咖啡,或者你刚打开电脑去处理这个问题时,一切都已经恢复如初。
1.3.4 其他小问题
===========
当然k8s给我们带来的便利性和解决的问题远不止上面所说的,容器镜像帮我们解决了依赖环境的问题,服务编排帮我们解决了故障容灾的问题,我们可以使用k8s的包管理工具一键创建一套新的环境,我们可以使用k8s的服务发现让开发人员无需再关注网络部分的开发,我们可以使用k8s的权限控制让运维人员无需再去管理每台服务器的权限,我们可以使用k8s强大的应用程序发布策略让我们无需过多的考虑如何实现零宕机发布应用及应用回滚,等等,这一切的便利性正在悄悄的改变着我们的行为。
2. 迁移计划
========
2.1 蓝绿迁移
========
首先来看一下迁移之前的架构
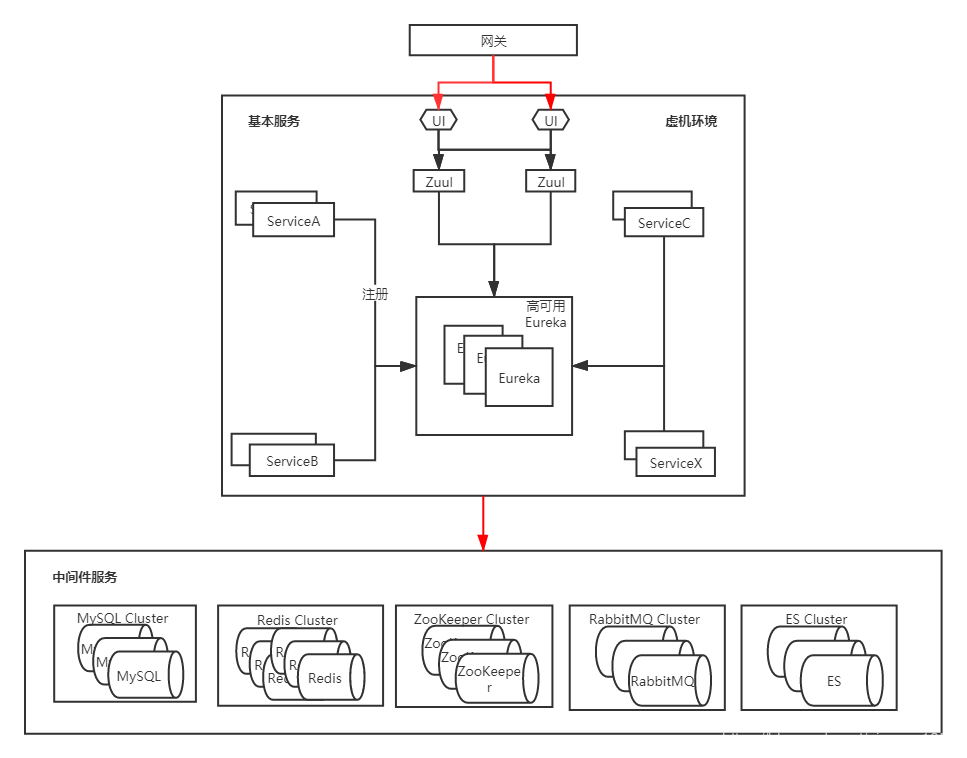
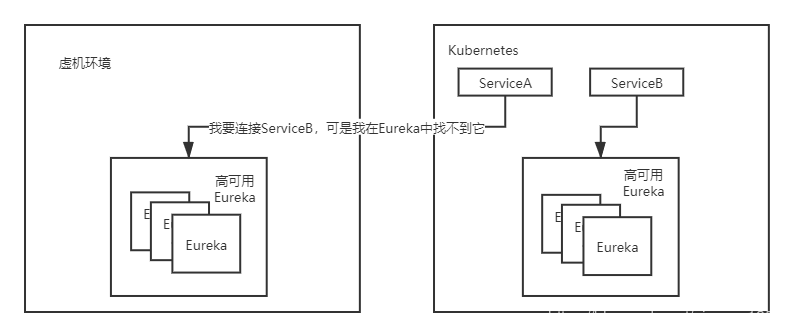
和大多数SpringCloud架构一样,使用NodeJS作为前端,Eureka用作服务发现,Zuul进行路由分发,ConfigServer作为配置中心。这种架构也是SpringCloud在企业中最普遍的架构,没有使用更多额外的组件,所以我们在第一次迁移时,也没有考虑太多,还是按照迁移其他项目使用的方案,即在k8s上新建一套环境(本次迁移没有涉及到中间件),也就是容器化环境,配置一个同样的域名,然后添加hosts解析进行测试,没有问题的话直接进行域名切换即可完成迁移。这种方式是最简单也是最常用的方式,类似于程序发版的蓝绿部署,此时在k8s新建一套环境对应的架构图如下:
在进行测试时,此项目同时并行了两套环境,一套虚机环境,一套容器环境,容器环境只接收测试人员的流量,两套环境连接的是同一套中间件服务,因为其他项目大部分也是按照这种方式迁移的,并且该项目在测试环境也进行过同样的流程,没有出现什么问题,所以也同样认为这种方式在本项目也不会出现什么问题。但往往现实总会与预期有所差异,在测试过程中由于两套环境并存,导致了部分生产数据出现问题,由于容器环境没有经过完整性测试,也没有强制切换域名,后来紧急关停了所有的容器问题才得以恢复。由于时间比较紧迫,我们并没有仔细排查问题所在,只是修复了部分数据,后来我们认为可能是迁移过程中部分微服务master分支和生产代码不一致造成的,当然也可能并不是这么简单。为了规避这类问题再次发生只能去修改迁移方案。
2.2 灰度迁移
========
由于上面的迁移方案出了点问题,就重新定了一个方案,较上次略微麻烦,采用逐个微服务迁移至k8s,类似于应用程序发版的灰度发布。
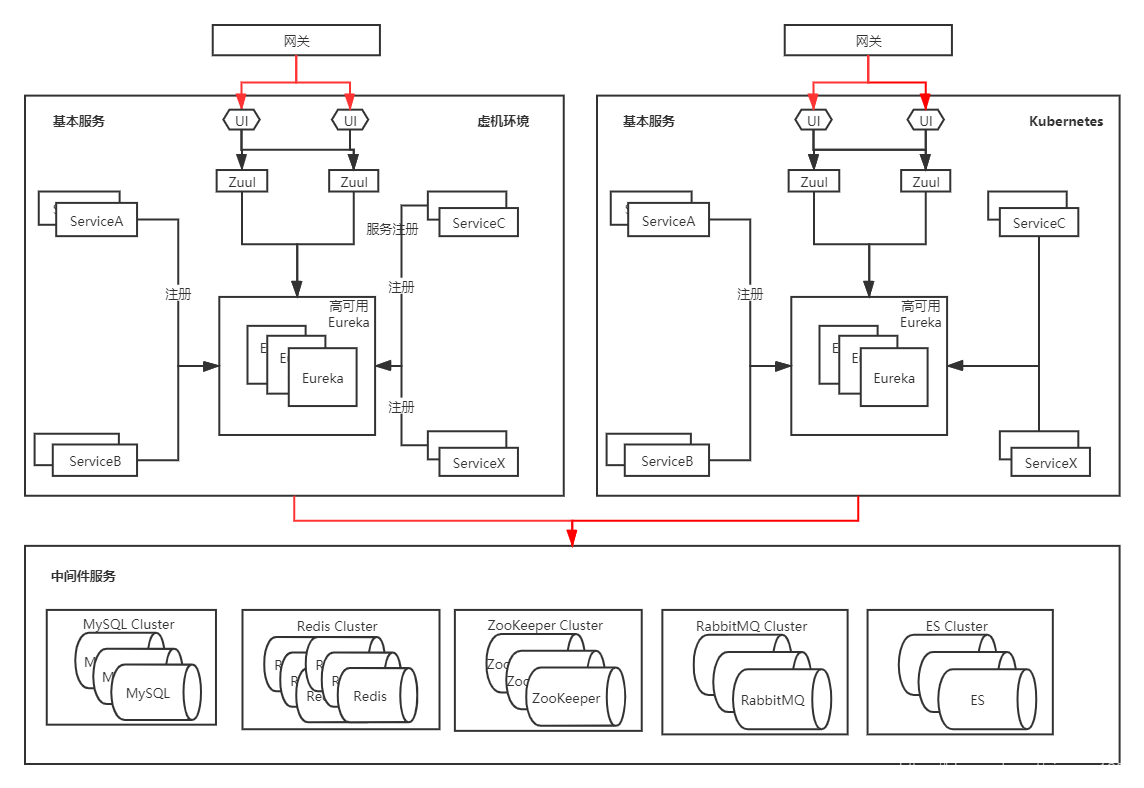
单个应用迁移时,需要确保容器环境和虚机环境的代码一致,在迁移时微服务采用域名注册的方式。也就是每个微服务都配置一个内部域名,通过域名去注册到Eureka,而不是采用容器的IP和端口去注册(因为k8s内部的IP和虚拟机未打通),此时的环境如下图所示:
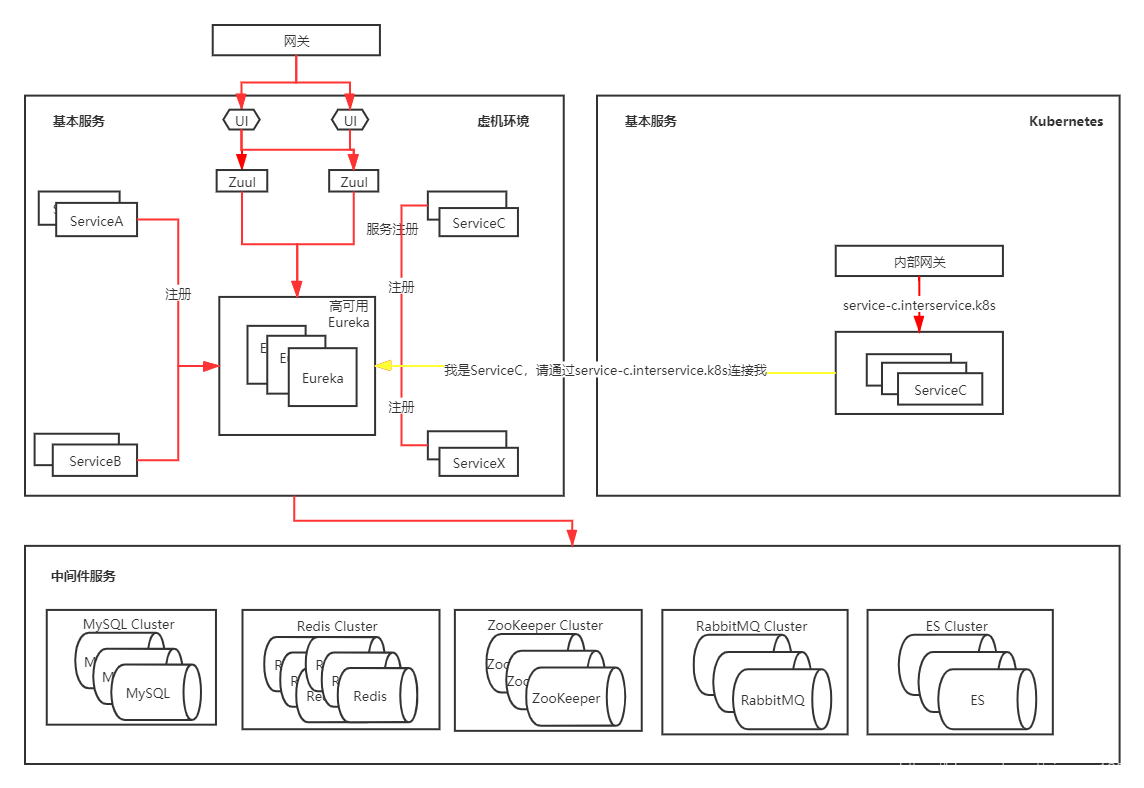
此时有一个域名
service-c.interservice.k8s指向ServiceC,然后ServiceC注册到Eureka时修改自己的地址为该域名(默认是宿主机IP+端口),之后别的应用通过该地址调用ServiceC,当ServiceC测试无问题后,下线虚拟机里面的ServiceC,最后的架构如图所示:
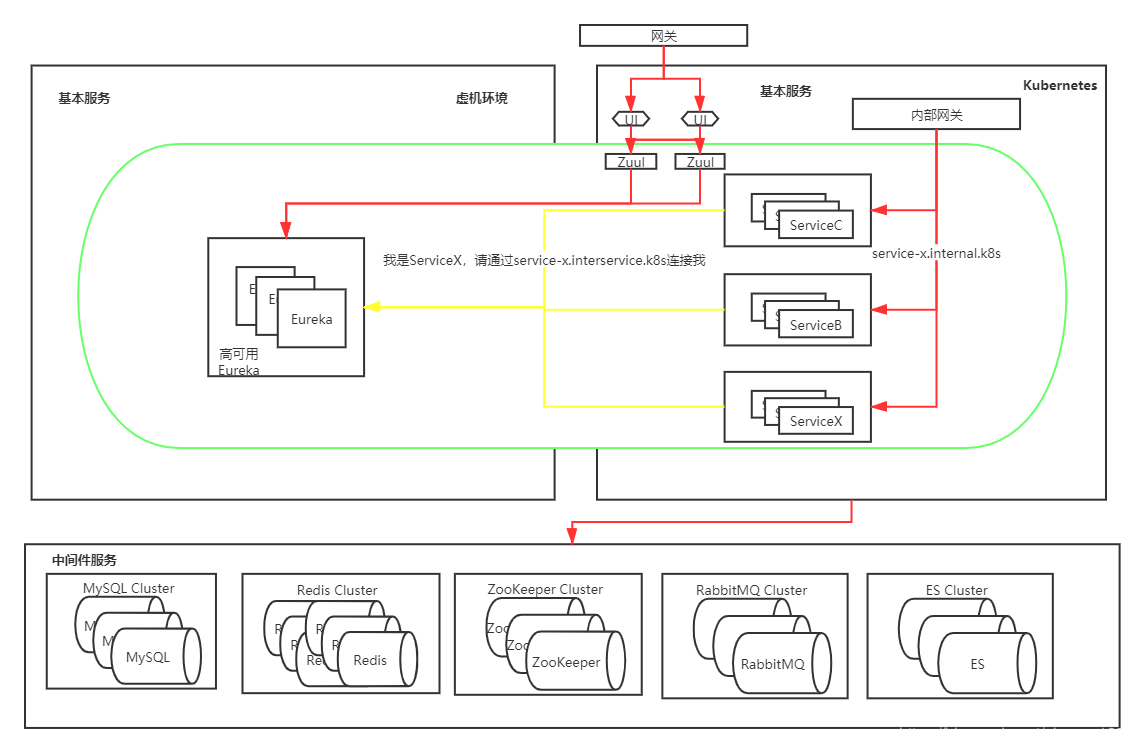
除了Zuul、前端UI和Eureka,其他服务都使用灰度的方式迁移到k8s,比蓝绿的形式更为复杂,需要为每个微服务单独创建Service、域名,在迁移完成之后还需要删除。到这一步后,除了Eureka其他服务都已经部署在k8s上,而对于Eureka的迁移,涉及的细节更多。
2.3 Eureka迁移
============
到这一步后,服务访问没有出现其他问题,除了Eureka之外的服务,都已经部署在k8s,而Eureka的过渡性迁移设计的问题可能会更多。因为我们不能直接在k8s上部署一套高可用的Eureka集群,然后直接把ConfigServer里面的微服务注册地址改成k8s中的Eureka地址,因为此时两个Eureka集群都是独立的Zone,注册信息并不会共享,这种会在更改配置的过程中丢失注册信息,此时架构图可能会出现如下情况: