目录
- 简介
- 栈
- 一、栈的基本概念
- 1、栈的定义
- 2、栈的常见基本操作
- 二、栈的顺序存储结构
- 1、栈的顺序存储
- 2、顺序栈的基本算法
- 3、共享栈(两栈共享空间)
- 三、栈的链式存储结构
- 1、链栈
- 2、链栈的基本算法
- 3、性能分析
- 四、栈的应用——递归
- 1、递归的定义
- 2、斐波那契数列
- 五、栈的应用——四则运算表达式求值
- 1、后缀表达式计算结果
- 2、中缀表达式转后缀表达式
- 队列
- 一、队列的基本概念
- 1、队列的定义
- 2、队列的常见基本操作
- 二、队列的顺序存储结构
- 1、顺序队列
- 2、循环队列
- 3、循环队列常见基本算法
- 三、队列的链式存储结构
- 1、链队列
- 2、链队列常见基本算法
- 四、双端队列
- 1、定义
- 2、特殊的双端队列
简介
【知识框架】
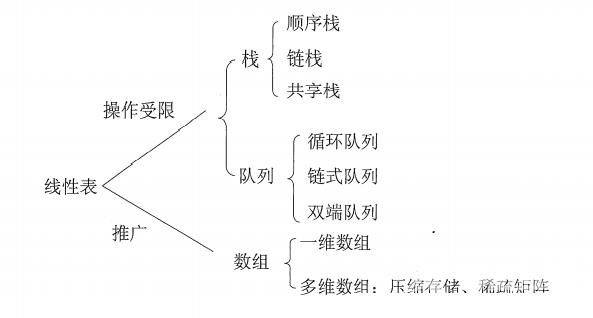
栈
一、栈的基本概念
1、栈的定义
栈(Stack):是只允许在一端进行插入或删除的线性表。首先栈是一种线性表,但限定这种线性表只能在某一端进行插入和删除操作。
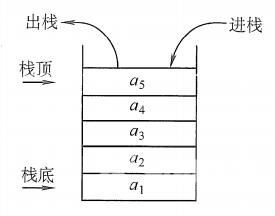
栈顶(Top):线性表允许进行插入删除的那一端。
栈底(Bottom):固定的,不允许进行插入和删除的另一端。
空栈:不含任何元素的空表。
栈又称为后进先出(Last In First Out)的线性表,简称LIFO结构
2、栈的常见基本操作
InitStack(&S):初始化一个空栈S。
StackEmpty(S):判断一个栈是否为空,若栈为空则返回true,否则返回false。
Push(&S, x):进栈(栈的插入操作),若栈S未满,则将x加入使之成为新栈顶。
Pop(&S, &x):出栈(栈的删除操作),若栈S非空,则弹出栈顶元素,并用x返回。
GetTop(S, &x):读栈顶元素,若栈S非空,则用x返回栈顶元素。
DestroyStack(&S):栈销毁,并释放S占用的存储空间(“&”表示引用调用)。
二、栈的顺序存储结构
1、栈的顺序存储
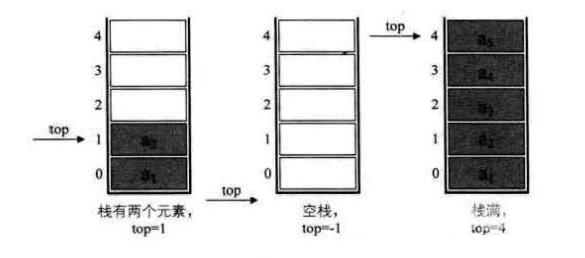
采用顺序存储的栈称为顺序栈,它利用一组地址连续的存储单元存放自栈底到栈顶的数据元素,同时附设一个指针(top)指示当前栈顶元素的位置。
若存储栈的长度为StackSize,则栈顶位置top必须小于StackSize。当栈存在一个元素时,top等于0,因此通常把空栈的判断条件定位top等于-1。
栈的顺序存储结构可描述为:
#define MAXSIZE 50 //定义栈中元素的最大个数
typedef int ElemType; //ElemType的类型根据实际情况而定,这里假定为int
typedef struct{
ElemType data[MAXSIZE];
int top; //用于栈顶指针
}SqStack;
若现在有一个栈,StackSize是5,则栈的普通情况、空栈、满栈的情况分别如下图所示:
2、顺序栈的基本算法
(1)初始化
void InitStack(SqStack *S){
S->top = -1; //初始化栈顶指针
}
(2)判栈空
bool StackEmpty(SqStack S){
if(S.top == -1){
return true; //栈空
}else{
return false; //不空
}
}
(3)进栈
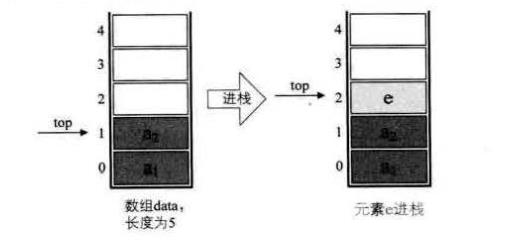
进栈操作push,代码如下:
/*插入元素e为新的栈顶元素*/
Status Push(SqStack *S, ElemType e){
//满栈
if(S->top == MAXSIZE-1){
return ERROR;
}
S->top++; //栈顶指针增加一
S->data[S->top] = e; //将新插入元素赋值给栈顶空间
return OK;
}
(4)出栈
出栈操作pop,代码如下:
/*若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR*/
Status Pop(SqStack *S, ElemType *e){
if(S->top == -1){
return ERROR;
}
*e = S->data[S->top]; //将要删除的栈顶元素赋值给e
S->top--; //栈顶指针减一
return OK;
}
(5)读栈顶元素
/*读栈顶元素*/
Status GetTop(SqStack S, ElemType *e){
if(S->top == -1){ //栈空
return ERROR;
}
*e = S->data[S->top]; //记录栈顶元素
return OK;
}
3、共享栈(两栈共享空间)
(1)共享栈概念
利用栈底位置相对不变的特征,可让两个顺序栈共享一个一维数组空间,将两个栈的栈底分别设置在共享空间的两端,两个栈顶向共享空间的中间延伸,
如下图所示:

两个栈的栈顶指针都指向栈顶元素,top0=-1时0号栈为空,top1=MaxSize时1号栈为空;仅当两个栈顶指针相邻(top0+1=top1)时,判断为栈满。当0号栈进栈时top0先加1再赋值,1号栈进栈时top1先减一再赋值出栈时则刚好相反。
(2)共享栈的空间结构
代码如下:
/*两栈共享空间结构*/
#define MAXSIZE 50 //定义栈中元素的最大个数
typedef int ElemType; //ElemType的类型根据实际情况而定,这里假定为int
/*两栈共享空间结构*/
typedef struct{
ElemType data[MAXSIZE];
int top0; //栈0栈顶指针
int top1; //栈1栈顶指针
}SqDoubleStack;
(3)共享栈进栈
对于两栈共享空间的push方法,我们除了要插入元素值参数外,还需要有一个判断是栈0还是栈1的栈号参数stackNumber。
共享栈进栈的代码如下:
/*插入元素e为新的栈顶元素*/
Status Push(SqDoubleStack *S, Elemtype e, int stackNumber){
if(S->top0+1 == S->top1){ //栈满
return ERROR;
}
if(stackNumber == 0){ //栈0有元素进栈
S->data[++S->top0] = e; //若栈0则先top0+1后给数组元素赋值
}else if(satckNumber == 1){ //栈1有元素进栈
S->data[--S->top1] = e; //若栈1则先top1-1后给数组元素赋值
}
return OK;
}
(4)共享栈出栈
代码如下:
/*若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR*/
Status Pop(SqDoubleStack *S, ElemType *e, int stackNumber){
if(stackNumber == 0){
if(S->top0 == -1){
return ERROR; //说明栈0已经是空栈,溢出
}
*e = S->data[S->top0--]; //将栈0的栈顶元素出栈,随后栈顶指针减1
}else if(stackNumber == 1){
if(S->top1 == MAXSIZE){
return ERROR; //说明栈1是空栈,溢出
}
*e = S->data[S->top1++]; //将栈1的栈顶元素出栈,随后栈顶指针加1
}
return OK;
}
三、栈的链式存储结构
1、链栈
采用链式存储的栈称为链栈,链栈的优点是便于多个栈共享存储空间和提高其效率,且不存在栈满上溢的情况。通常采用单链表实现,并规定所有操作都是在单链表的表头进行的。这里规定链栈没有头节点,Lhead指向栈顶元素,如下图所示。

对于空栈来说,链表原定义是头指针指向空,那么链栈的空其实就是top=NULL的时候。
链栈的结构代码如下:
/*栈的链式存储结构*/
/*构造节点*/
typedef struct StackNode{
ElemType data;
struct StackNode *next;
}StackNode, *LinkStackPrt;
/*构造链栈*/
typedef struct LinkStack{
LinkStackPrt top;
int count;
}LinkStack;
2、链栈的基本算法
(1)链栈的进栈
对于链栈的进栈push操作,假设元素值为e的新节点是s,top为栈顶指针,示意图如下:
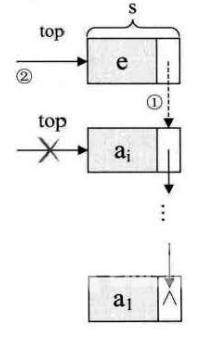
代码如下:
/*插入元素e为新的栈顶元素*/
Status Push(LinkStack *S, ElemType e){
LinkStackPrt p = (LinkStackPrt)malloc(sizeof(StackNode));
p->data = e;
p->next = S->top; //把当前的栈顶元素赋值给新节点的直接后继
S->top = p; //将新的结点S赋值给栈顶指针
S->count++;
return OK;
}
(2)链栈的出栈
链栈的出栈pop操作,也是很简单的三句操作。假设变量p用来存储要删除的栈顶结点,将栈顶指针下移以为,最后释放p即可,
如下图所示:
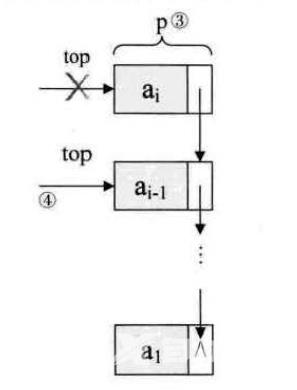
代码如下:
/*若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR*/
Status Pop(LinkStack *S, ElemType *e){
LinkStackPtr p;
if(StackEmpty(*S)){
return ERROR;
}
*e = S->top->data;
p = S->top; //将栈顶结点赋值给p
S->top = S->top->next; //使得栈顶指针下移一位,指向后一结点
free(p); //释放结点p
S->count--;
return OK;
}
3、性能分析
链栈的进栈push和出栈pop操作都很简单,时间复杂度均为O(1)。
对比一下顺序栈与链栈,它们在时间复杂度上是一样的,均为O(1)。对于空间性能,顺序栈需要事先确定一个固定的长度,可能会存在内存空间浪费的问题,但它的优势是存取时定位很方便,而链栈则要求每个元素都有指针域,这同时也增加了一些内存开销,但对于栈的长度无限制。所以它们的区别和线性表中讨论的一样,如果栈的使用过程中元素变化不可预料,有时很小,有时非常大,那么最好是用链栈,反之,如果它的变化在可控范围内,建议使用顺序栈会更好一些。
四、栈的应用——递归
1、递归的定义
递归是一种重要的程序设计方法。简单地说,若在一个函数、过程或数据结构的定义中又应用了它自身,则这个函数、过程或数据结构称为是递归定义的,简称递归。
它通常把一个大型的复杂问题层层转化为一个与原问题相似的规模较小的问题来求解,递归策略只需少量的代码就可以描述岀解题过程所需要的多次重复计算,大大减少了程序的代码量但在通常情况下,它的效率并不是太高。
2、斐波那契数列
在解释斐波那契数列之前,我们想看经典的兔子繁殖的问题:
说如果兔子在出生两个月后,就有繁殖能力,一对兔子每个月能生出一对小兔子 来。假设所有兔都不死,那么一年以后可以繁殖多少对兔子呢?
- 第一个月初有一对刚诞生的兔子第
- 二个月之后(第三个月初)它们可以生育
- 每月每对可生育的兔子会诞生下一对新兔子
- 兔子永不死去
我们拿新出生的一对小兔子分析一下:第一个月小兔子没有繁殖能力,所以还是一对;两个月后,生下一对小兔子数共有两对;三个月以后,老兔子又生下一对,因为小兔子还没有繁殖能力,所以一共是三对…依次类推得出这样一个图:
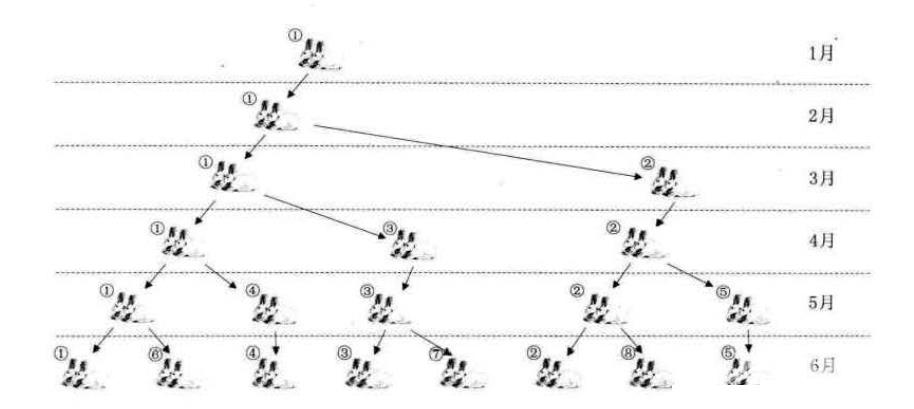
从这个图可以看出,斐波那契数列数列有一个明显的特点,即:前面两项之和,构成了后一项。
如果用数学函数定义斐波那契数列,那就是:
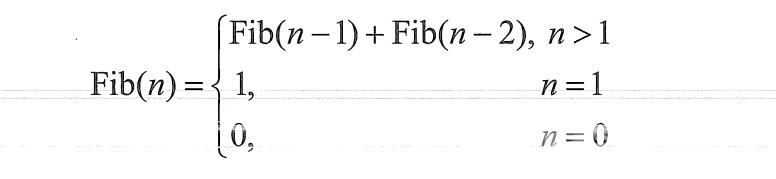
而这个,就是递归的一个典型例子,用程序实现时如下:
/*斐波那契数列的实现*/
int Fib(int n){
if(n == 0){
return 0; //边界条件
}else if(n == 1){
return 1; //边界条件
}else{
return Fib(n-1) + Fib(n-2); //递归表达式
}
}
必须注意递归模型不能是循环定义的,其必须满足下面的两个条件
- 递归表达式(递归体)
- 边界条件(递归出口)
递归的精髓在于能否将原始问题转换为属性相同但规模较小的问题
在递归调用的过程中,系统为每一层的返回点、局部变量、传入实参等开辟了递归工作栈来进行数据存储,递归次数过多容易造成栈溢出等。而其效率不高的原因是递归调用过程中包含很多重复的计算。下面以n=5为例,列出递归调用执行过程,如图所示:

如图可知,程序每往下递归一次,就会把运算结果放到栈中保存,直到程序执行到临界条件,然后便会把保存在栈中的值按照先进后出的顺序一个个返回,最终得出结果。
五、栈的应用——四则运算表达式求值
1、后缀表达式计算结果
表达式求值是程序设计语言编译中一个最基本的问题,它的实现是栈应用的一个典型范例。中缀表达式不仅依赖运算符的优先级,而且还要处理括号。后缀表达式的运算符在操作数后面,在后缀表达式中已考虑了运算符的优先级,没有括号,只有操作数和运算符。例如中缀表达式 A + B ∗ ( C − D ) − E / F A+B*(C-D)-E/F A+B∗(C−D)−E/F所对应的后缀表达式为 A B C D − ∗ + E F / − ABCD-*+EF/- ABCD−∗+EF/−。
后缀表达式计算规则:从左到右遍历表达式的每个数字和符号,遇到是数字就进栈,遇到是符号,就将处于栈顶两个数字出栈,进项运算,运算结果进栈,一直到最终获得结果。
后缀表达式 A B C D − ∗ + E F / − ABCD-*+EF/- ABCD−∗+EF/−求值的过程需要12步,如下表所示:
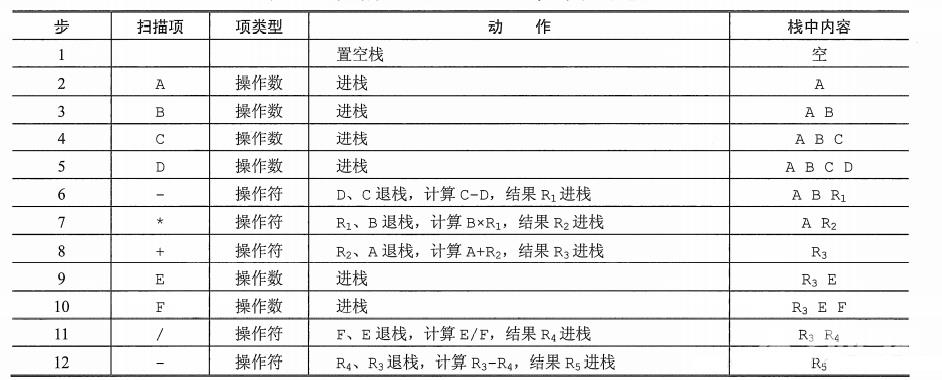
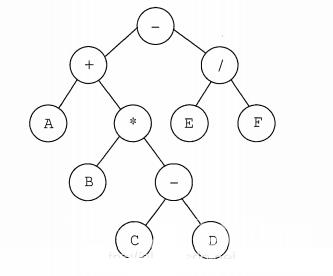
读者也可将后缀表达式与原运算式对应的表达式树(用来表示算术表达式的二元树)的后序遍历进行比较,可以发现它们有异曲同工之妙。
如下图则是 A + B ∗ ( C − D ) − E / F A+B*(C-D)-E/F A+B∗(C−D)−E/F对应的表达式,它的后序遍历即是表达式 A B C D − ∗ + E F / − ABCD-*+EF/- ABCD−∗+EF/−。
2、中缀表达式转后缀表达式
我们把平时所用的标准四则运算表达式,即 a + b − a ∗ ( ( c + d ) / e − f ) + g a+b-a*((c+d)/e-f)+g a+b−a∗((c+d)/e−f)+g叫做中缀
表达式。因为所有的运算符号都在两数字的中间,现在我们的问题就是中缀到后缀的转化。
规则:从左到右遍历中缀表达式的每个数字和符号,若是数字就输出,即成为后
缀表达式的一部分;若是符号,则判断其与栈顶符号的优先级,是右括号或优先级低于栈顶符号(乘除优先加减)则栈顶元素依次出栈并输出,并将当前符号进栈,一直到最终输出后缀表达式为止。
例:将中缀表达式 a + b − a ∗ ( ( c + d ) / e − f ) + g a+b-a*((c+d)/e-f)+g a+b−a∗((c+d)/e−f)+g转化为相应的后缀表达式。
分析:需要根据操作符
的优先级来进行栈的变化,我们用icp来表示当前扫描到的运算符ch的优先级,该运算符进栈后的优先级为isp,则运算符的优先级如下表所示[isp是栈内优先( in stack priority)数,icp是栈外优先( in coming priority)数]。

我们在表达式后面加上符号‘#’,表示表达式结束。
具体转换过程如下:
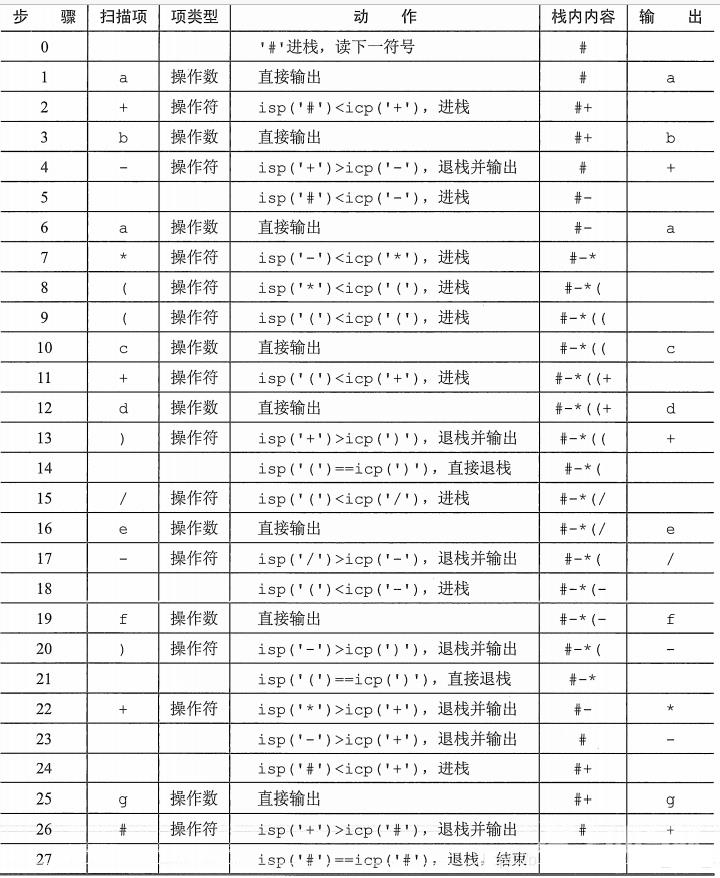
即相应的后缀表达式为 a b + a c d + e / f − ∗ − g + ab+acd+e/f-*-g+ ab+acd+e/f−∗−g+。
队列
一、队列的基本概念
1、队列的定义
队列(queue)是只允许在一端进行插入操作,而在另一端进行删除操作的线性表。
队列是一种先进先出(First In First Out)的线性表,简称FIFO。允许插入的一端称为队尾,允许删除的一端称为队头。
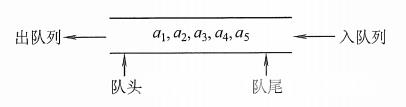
队头(Front):允许删除的一端,又称队首。
队尾(Rear):允许插入的一端。
空队列:不包含任何元素的空表。
2、队列的常见基本操作
- InitQueue(&Q):初始化队列,构造一个空队列Q。
- QueueEmpty(Q):判队列空,若队列Q为空返回true,否则返回
- false。EnQueue(&Q, x):入队,若队列Q未满,将x加入,使之成为新的队尾。
- DeQueue(&Q, &x):出队,若队列Q非空,删除队头元素,并用x返回。
- GetHead(Q, &x):读队头元素,若队列Q非空,则将队头元素赋值给x
二、队列的顺序存储结构
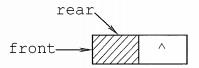
队列的顺序实现是指分配一块连续的存储单元存放队列中的元素,并附设两个指针:队头指针 front指向队头元素,队尾指针 rear 指向队尾元素的下一个位置。
1、顺序队列
队列的顺序存储类型可描述为:
#define MAXSIZE 50 //定义队列中元素的最大个数
typedef struct{
ElemType data[MAXSIZE]; //存放队列元素
int front,rear;
}SqQueue;
初始状态(队空条件):Q->front == Q->rear == 0。
进队操作:队不满时,先送值到队尾元素,再将队尾指针加1。
出队操作:队不空时,先取队头元素值,再将队头指针加1。
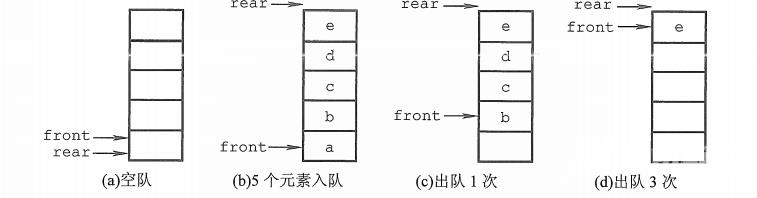
如图d,队列出现“上溢出”,然而却又不是真正的溢出,所以是一种“假溢出”。
2、循环队列
解决假溢出的方法就是后面满了,就再从头开始,也就是头尾相接的循环。我们把队列的这种头尾相接的顺序存储结构称为循环队列。
当队首指针Q->front = MAXSIZE-1后,再前进一个位置就自动到0,这可以利用除法取余运算(%)来实现。
初始时:Q->front = Q->rear=0。队首指针进1:Q->front = (Q->front + 1) % MAXSIZE。队尾指针进1:Q->rear = (Q->rear + 1) % MAXSIZE。队列长度:(Q->rear - Q->front + MAXSIZE) % MAXSIZE。
出队入队时,指针都按照顺时针方向前进1,如下图所示:
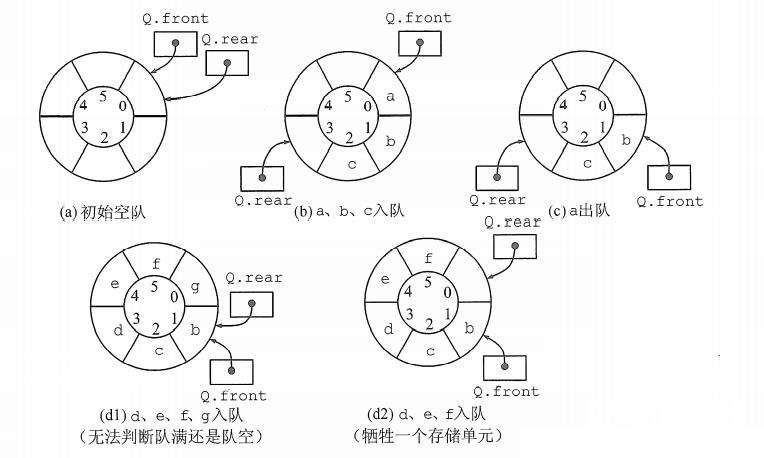
那么,循环队列队空和队满的判断条件是什么呢?
显然,队空的条件是 Q->front == Q->rear 。若入队元素的速度快于出队元素的速度,则队尾指针很快就会赶上队首指针,如图( d1 )所示,此时可以看出队满时也有 Q ->front == Q -> rear 。
为了区分队空还是队满的情况,有三种处理方式:
(1)牺牲一个单元来区分队空和队满,入队时少用一个队列单元,这是种较为普遍的做法,约定以“队头指针在队尾指针的下一位置作为队满的标志”,如图 ( d2 )所示。
- 队满条件: (Q->rear + 1)%Maxsize == Q->front
- 队空条件仍: Q->front == Q->rear
- 队列中元素的个数: (Q->rear - Q ->front + Maxsize)% Maxsize
(2)类型中增设表示元素个数的数据成员。这样,队空的条件为 Q->size == O ;队满的条件为 Q->size == Maxsize 。这两种情况都有 Q->front == Q->rear
(3)类型中增设tag 数据成员,以区分是队满还是队空。tag 等于0时,若因删除导致 Q->front == Q->rear ,则为队空;tag 等于 1 时,若因插入导致 Q ->front == Q->rear ,则为队满。
我们重点讨论第一种方法
3、循环队列常见基本算法
(1)循环队列的顺序存储结构
typedef int ElemType; //ElemType的类型根据实际情况而定,这里假定为int
#define MAXSIZE 50 //定义元素的最大个数
/*循环队列的顺序存储结构*/
typedef struct{
ElemType data[MAXSIZE];
int front; //头指针
int rear; //尾指针,若队列不空,指向队列尾元素的下一个位置
}SqQueue;
(2)循环队列的初始化
/*初始化一个空队列Q*/
Status InitQueue(SqQueue *Q){
Q->front = 0;
Q->rear = 0;
return OK;
}
(3)循环队列判队空
/*判队空*/
bool isEmpty(SqQueue Q){
if(Q.rear == Q.front){
return true;
}else{
return false;
}
}
(4)求循环队列长度
/*返回Q的元素个数,也就是队列的当前长度*/
int QueueLength(SqQueue Q){
return (Q.rear - Q.front + MAXSIZE) % MAXSIZE;
}
(5)循环队列入队
/*若队列未满,则插入元素e为Q新的队尾元素*/
Status EnQueue(SqQueue *Q, ElemType e){
if((Q->real + 1) % MAXSIZE == Q->front){
return ERROR; //队满
}
Q->data[Q->rear] = e; //将元素e赋值给队尾
Q->rear = (Q->rear + 1) % MAXSIZE; //rear指针向后移一位置,若到最后则转到数组头部
return OK;
}
(6)循环队列出队
/*若队列不空,则删除Q中队头元素,用e返回其值*/
Status DeQueue(SqQueue *Q, ElemType *e){
if(isEmpty(Q)){
return REEOR; //队列空的判断
}
*e = Q->data[Q->front]; //将队头元素赋值给e
Q->front = (Q->front + 1) % MAXSIZE; //front指针向后移一位置,若到最后则转到数组头部
}
三、队列的链式存储结构
1、链队列
队列的链式存储结构表示为链队列,它实际上是一个同时带有队头指针和队尾指针的单链表,只不过它只能尾进头出而已。
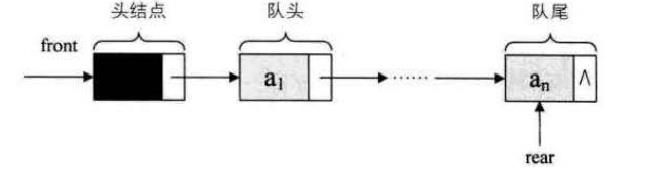
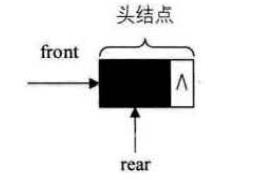
空队列时,front和real都指向头结点。
2、链队列常见基本算法
(1)链队列存储类型
/*链式队列结点*/
typedef struct {
ElemType data;
struct LinkNode *next;
}LinkNode;
/*链式队列*/
typedef struct{
LinkNode *front, *rear; //队列的队头和队尾指针
}LinkQueue;
当Q->front == NULL 并且 Q->rear == NULL 时,链队列为空。
(2)链队列初始化
void InitQueue(LinkQueue *Q){
Q->front = Q->rear = (LinkNode)malloc(sizeof(LinkNode)); //建立头结点
Q->front->next = NULL; //初始为空
}
(3)链队列入队

Status EnQueue(LinkQueue *Q, ElemType e){
LinkNode s = (LinkNode)malloc(sizeof(LinkNode));
s->data = e;
s->next = NULL;
Q->rear->next = s; //把拥有元素e新结点s赋值给原队尾结点的后继
Q->rear = s; //把当前的s设置为新的队尾结点
return OK;
}
(4)链队列出队
出队操作时,就是头结点的后继结点出队,将头结点的后继改为它后面的结点,若链表除头结点外只剩一个元素时,则需将rear指向头结点。
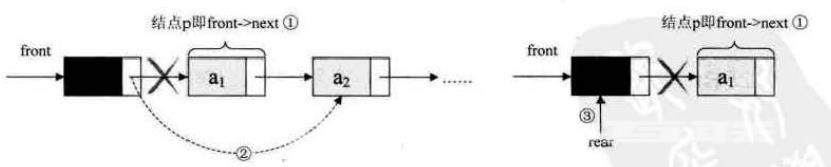
/*若队列不空,删除Q的队头元素,用e返回其值,并返回OK,否则返回ERROR*/
Status DeQueue(LinkQueue *Q, Elemtype *e){
LinkNode p;
if(Q->front == Q->rear){
return ERROR;
}
p = Q->front->next; //将欲删除的队头结点暂存给p
*e = p->data; //将欲删除的队头结点的值赋值给e
Q->front->next = p->next; //将原队头结点的后继赋值给头结点后继
//若删除的队头是队尾,则删除后将rear指向头结点
if(Q->rear == p){
Q->rear = Q->front;
}
free(p);
return OK;
}
四、双端队列
1、定义
双端队列是指允许两端都可以进行入队和出队操作的队列,如下图所示。其元素的逻辑结构仍是线性结构。将队列的两端分别称为前端和后端,两端都可以入队和出队。

在双端队列进队时,前端进的元素排列在队列中后端进的元素的前面,后端进的元素排列在队列中前端进的元素的后面。在双端队列出队时,无论是前端还是后端出队,先出的元素排列在后出的元素的前面。
2、特殊的双端队列
在实际使用中,根据使用场景的不同,存在某些特殊的双端队列。
输出受限的双端队列:允许在一端进行插入和删除, 但在另一端只允许插入的双端队列称为输出受限的双端队列,如下图所示。

输入受限的双端队列:允许在一端进行插入和删除,但在另一端只允许删除的双端队列称为输入受限的双端队列,如下图所示。若限定双端队列从某个端点插入的元素只能从该端点删除,则该双端队列就蜕变为两个栈底相邻接的栈。

到此这篇关于c语言数据结构之栈和队列详解(Stack & Queue)的文章就介绍到这了,更多相关c语言据结构内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!