在对于读写锁的认识当中,我们都认为读时加读锁,写时加写锁来保证读写和写写互斥,从而达到读写安全的目的。但是就在我翻Eureka源码的时候,发现Eureka在使用读写锁时竟然是在读时加写锁,写时加读锁,这波操作属实震惊到了我,Eureka到底是故意为之还是一个bug?于是我就花了点时间研究了一下Eureka的这波操作。
Eureka服务注册实现类
众所周知,Eureka作为一个服务注册中心,肯定会涉及到服务实例的注册和发现,从而肯定会有服务实例写操作和读操作,这是每个注册中心最基本也是最核心的功能。
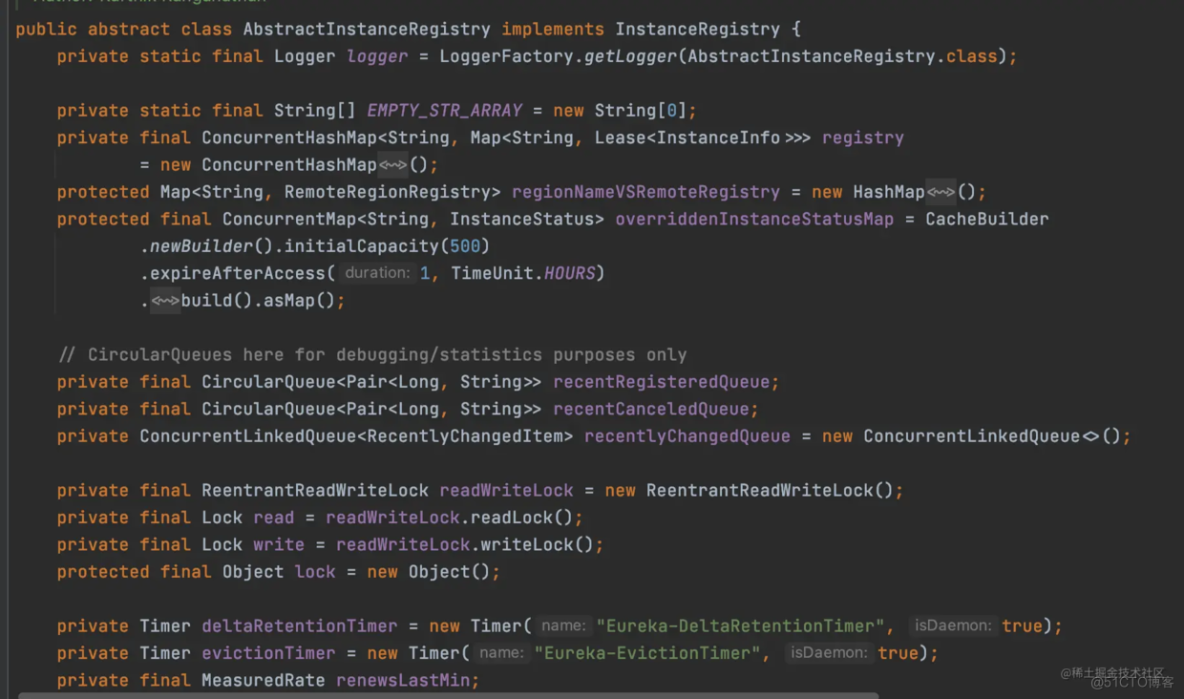
AbstractInstanceRegistry
如上图,AbstractInstanceRegistry是注册中心的服务注册核心实现类,这里面保存了服务实例的数据,封装了对于服务实例注册、下线、读取等核心方法。
这里讲解一下这个类比较重要的成员变量
服务注册表
private final ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry= new ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>();注册表就是存储的服务实例的信息。Eureka是使用ConcurrentHashMap来进行保存的。键值是服务的名称,值为服务的每个具体的实例id和实例数据的映射,所以也是一个Map数据结构。InstanceInfo就是每个服务实例的数据的封装对象。
服务的上线、下线、读取其实就是从注册表中读写数据。
最近变动的实例队列
private ConcurrentLinkedQueue<RecentlyChangedItem> recentlyChangedQueue = new ConcurrentLinkedQueue<>();recentlyChangedQueue保存了最近变动的服务实例的信息。如果有服务实例的变动发生,就会将这个服务实例封装到RecentlyChangedItem中,存到recentlyChangedQueue中。
什么叫服务实例发生了变动。举个例子,比如说,有个服务实例来注册了,这个新添加的实例就是变动的实例。
所以服务注册这个操作就会有两步操作,首先会往注册表中添加这个实例的信息,其次会给这个实例标记为新添加的,然后封装到RecentlyChangedItem中,存到recentlyChangedQueue中。
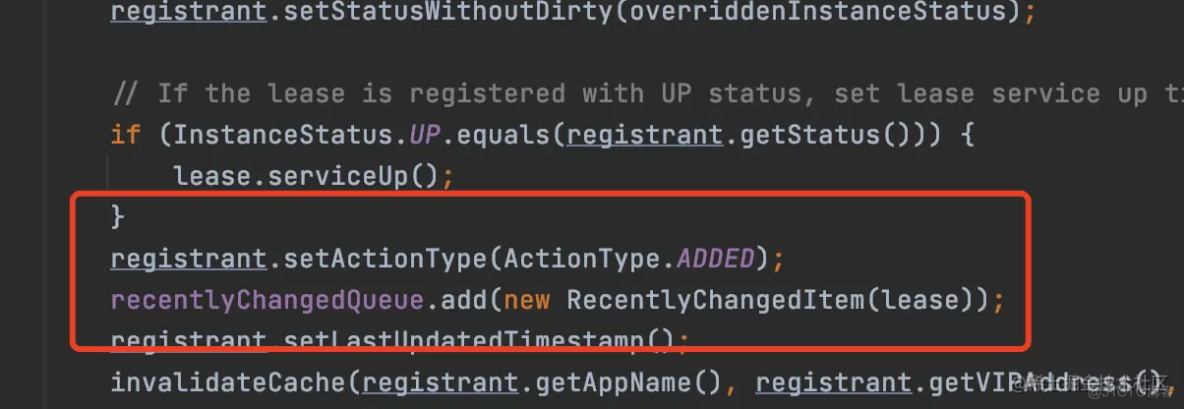
新增
同样的,服务实例状态的修改、删除(服务实例下线)不仅会操作注册表,同样也会进行标记,封装成一个RecentlyChangedItem并添加到recentlyChangedQueue中。
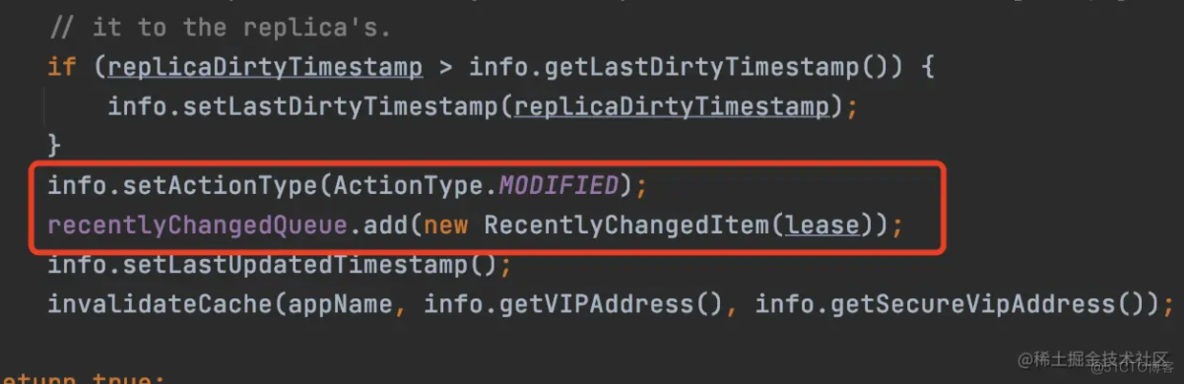
修改

下线
所以从这分析也可以看出,注册表的写操作同时也会往recentlyChangedQueue中写一条数据,这句话很重要。
后面本文提到的注册表的写操作都包含对recentlyChangedQueue的写操作。
读写锁
private final ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();private final Lock read = readWriteLock.readLock();private final Lock write = readWriteLock.writeLock();读写锁就不用说了,JDK提供的实现。
读写锁的加锁场景
上面说完了AbstractInstanceRegistry比较重要的成员变量,其中就有一个读写锁,也是本文的主题,所以接下来看看哪些操作加读锁,哪些操作加写锁。
加读锁的场景
1、服务注册
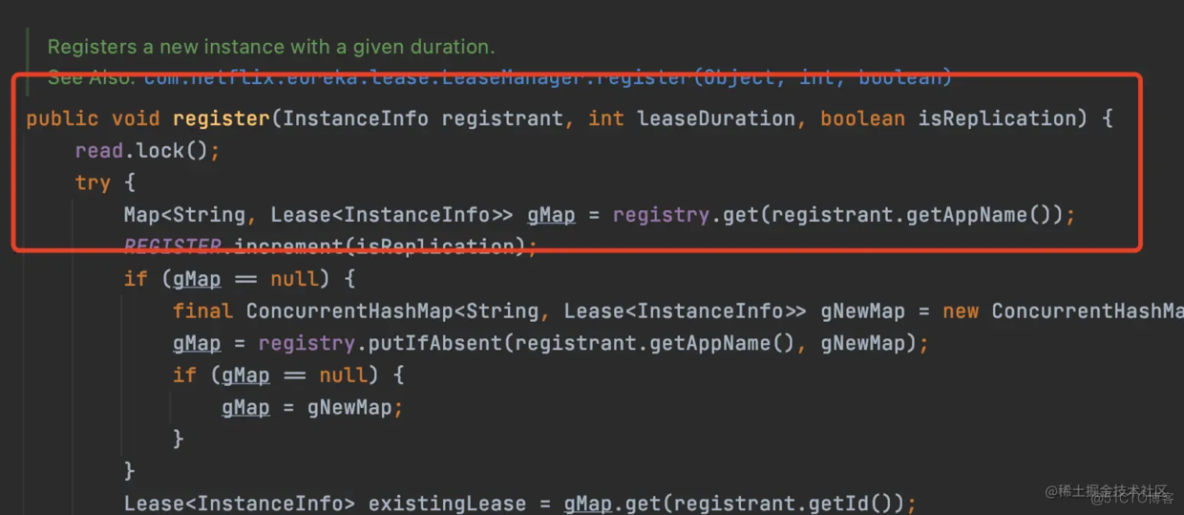
register
服务注册就是在注册表中添加一个服务实例的信息,加读锁。
2、服务下线
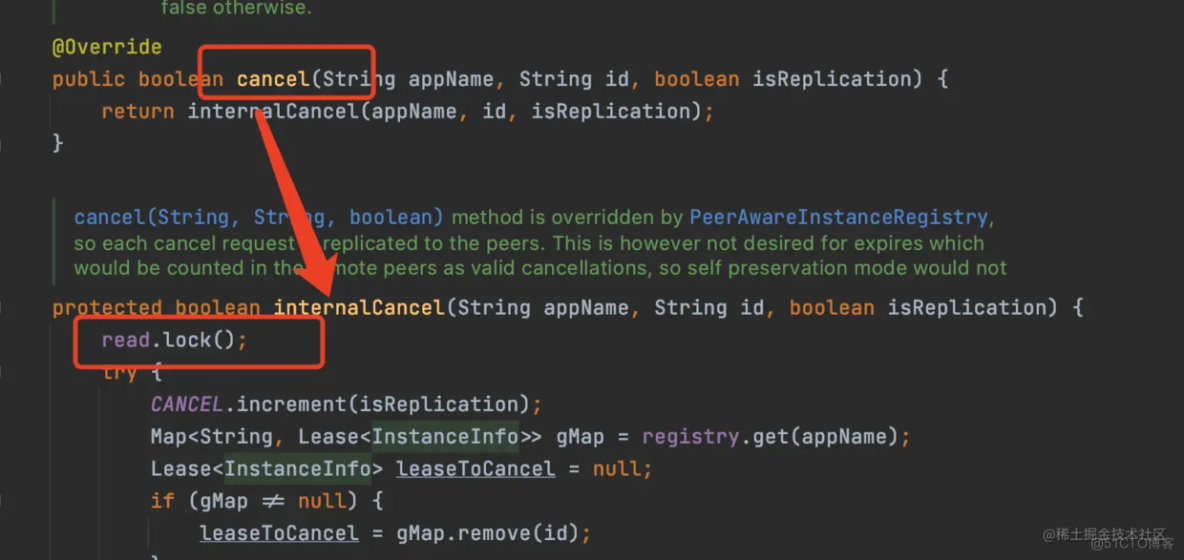
cancel和internalCancel
服务下线就是在注册表删除这个服务实例的信息,服务下线的方法最后是调用internalCancel实现的,而internalCancel是加的读锁,所以服务实例下线的时候加了读锁。
3、服务驱逐
什么叫服务驱逐,很简单,就是服务端会定时检查每个服务实例是否有向服务端发送心跳,如果服务端超过一定时间没有接收到服务实例的心跳信息,那么就会认为这个服务实例不可用,就会自动将这个服务实例从注册表删除,这就是叫服务驱逐。
服务驱逐是通过evict方法实现的,这个方法最终也是调用服务下线internalCancel方法来实现驱逐的。
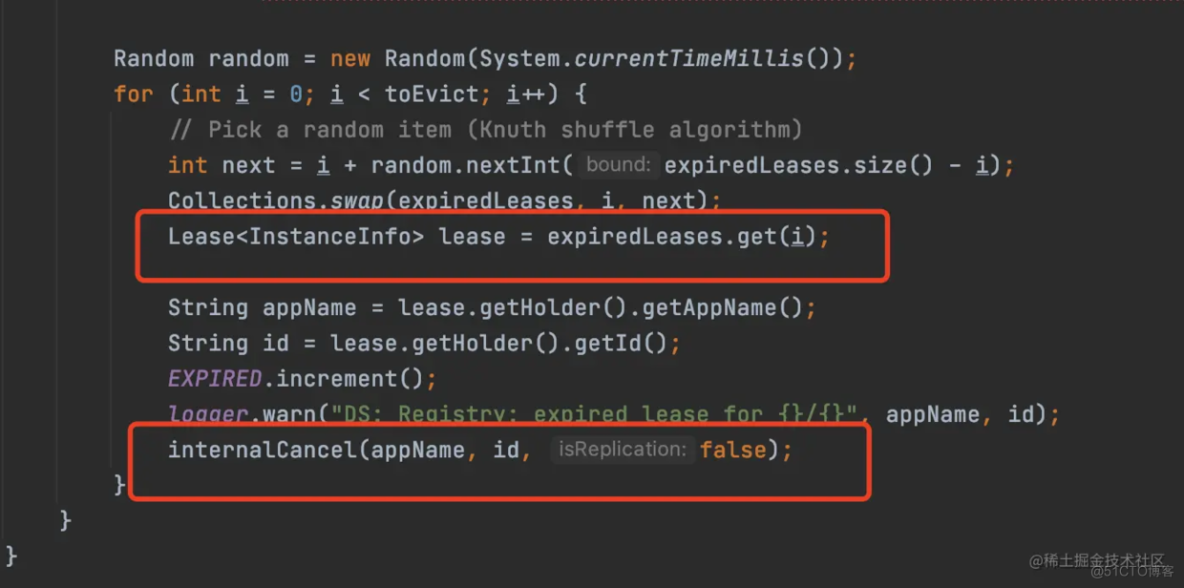
所以服务驱逐,其实也是加读锁的,因为最后是调用internalCancel方法来实现的,而internalCancel方法就是加的读锁。
4、更新服务状态
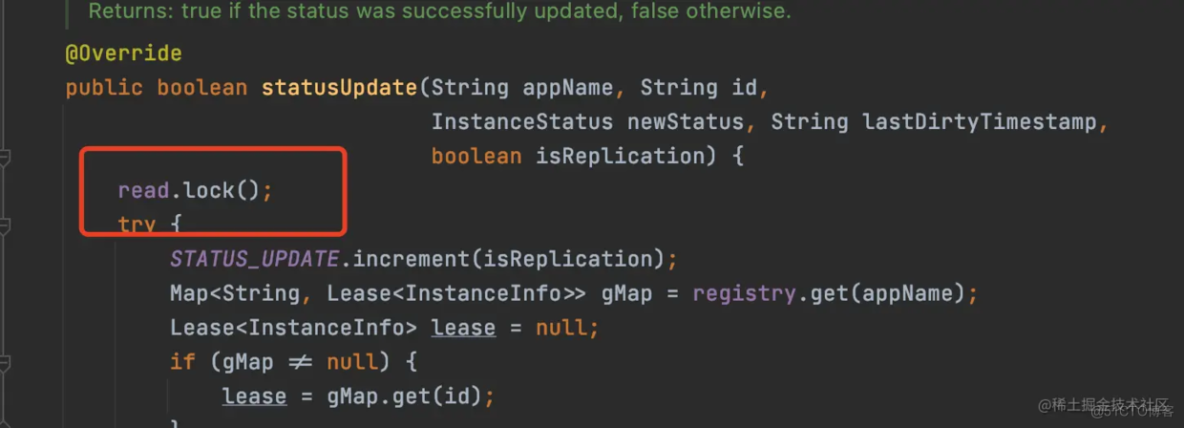
服务实例的状态变动了,进行更新操作,也是加的读锁
5、删除服务状态
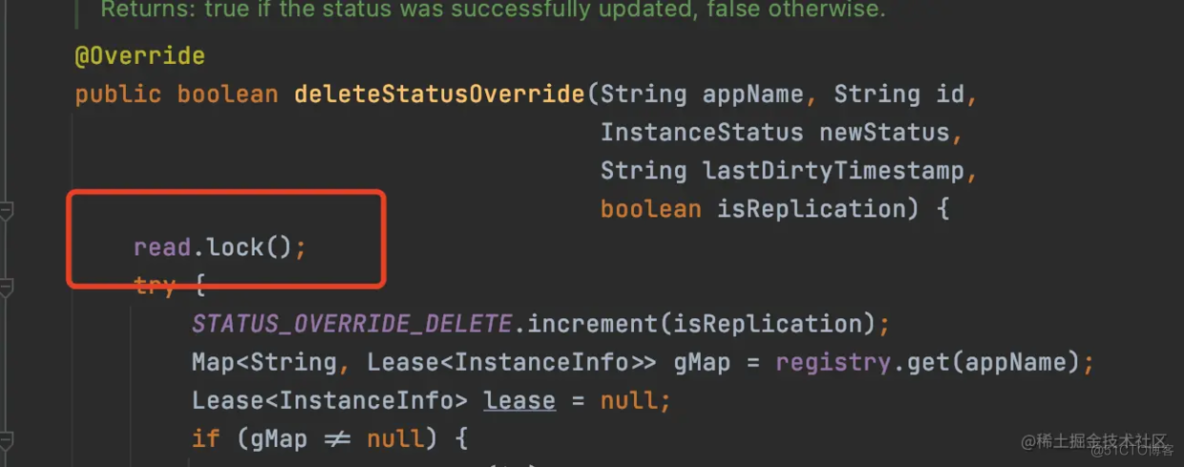
将服务的状态删了,也是加的读锁。
这里都是对于注册表的写操作,所以进行这些操作的同时也会往recentlyChangedQueue中写一条数据,只不过方法太长,代码太多,这里就没有截出来。
加写锁的场景
获取增量的服务实例的信息。
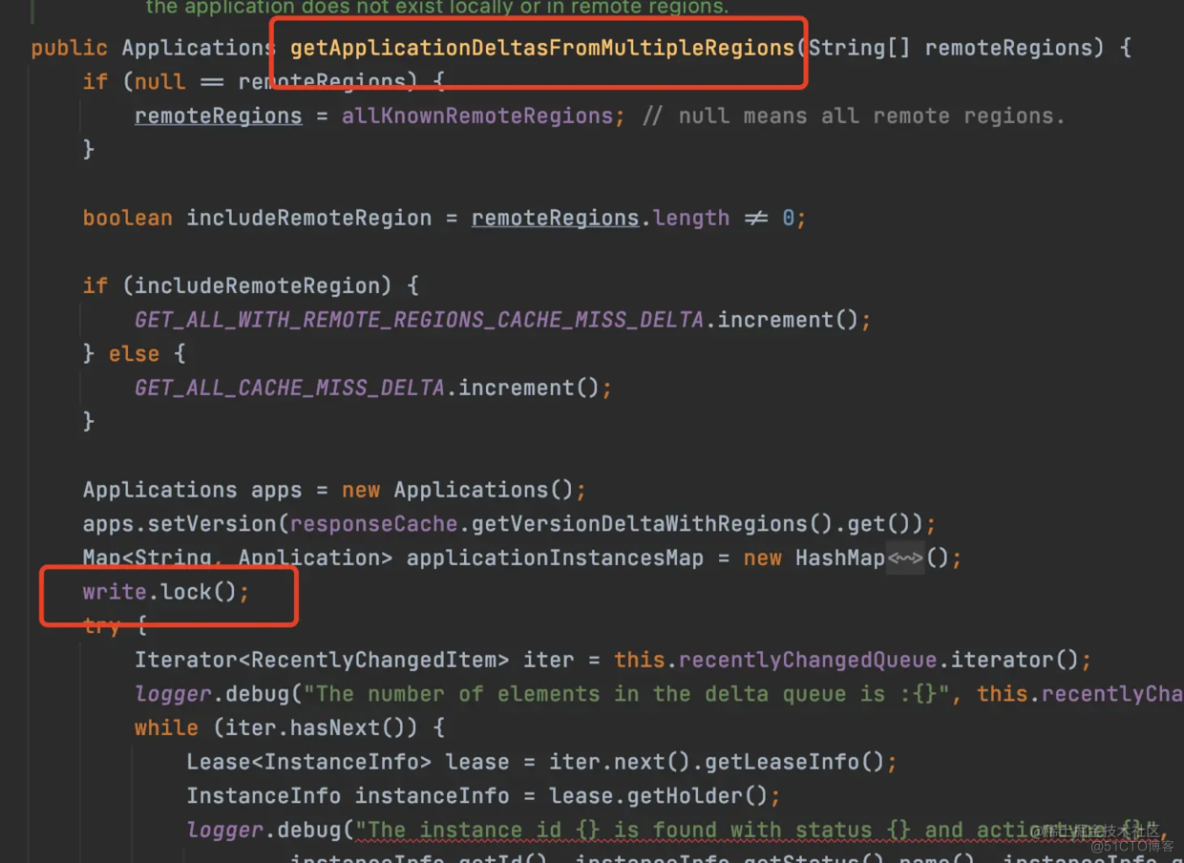
getApplicationDeltasFromMultipleRegions
所谓的增量信息,就是返回最近有变动的服务实例,而recentlyChangedQueue刚刚好保存了最近的服务实例的信息,所以这个方法的实现就是遍历recentlyChangedQueue,取出最近有变动的实例,返回。所以保存最近变动的实例,其实是为了增量拉取做准备的。
加锁总结
这里我总结一下读锁和写锁的加锁场景:
- 加读锁: 服务注册、服务下线、服务驱逐、服务状态的更新和删除
- 加写锁:获取增量的服务实例的信息
读写锁的加锁疑问
上一节讲了Eureka中加读锁和写锁的场景,有细心的小伙伴可能会有疑问,加读锁的场景主要涉及到服务注册表的增删操作,也就是写操作;而加写锁的场景是一个读的操作。
这不是很奇怪么,不按套路出牌啊,别人都是写时加写锁,读时加读锁,Eureka刚好反过来,属实是真的会玩。
写的时候加的读锁,那么就说明可以同时写,那会不会有线程安全问题呢?
答案是不会有安全问题。
我们以一个服务注册为例。一个服务注册,涉及到注册表的写操作和recentlyChangedQueue的写操作。
注册表本身就是一个ConcurrentHashMap,线程安全的map,注册表的值的Map数据结构,其实也是一个ConcurrentHashMap,如图。
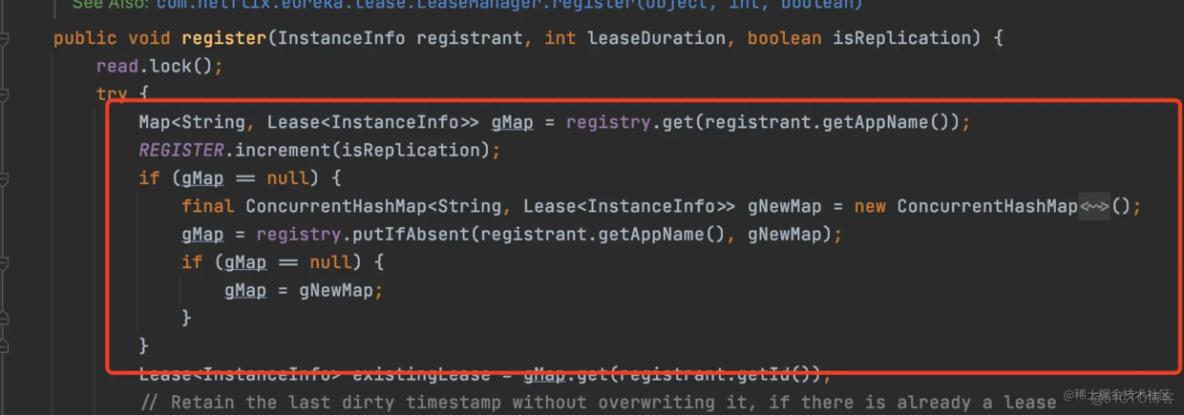
通过源码可以发现,其实也是放入的值也是一个ConcurrentHashMap,所以注册表本身就是线程安全的,所以对于注册表的写操作,本身就是安全的。
再来看一下对于recentlyChangedQueue,它本身就是一个ConcurrentLinkedQueue,并发安全的队列,也是线程安全的。
所以单独对注册表和recentlyChangedQueue的操作,其实是线程安全的。
到这里更加迷糊了,本身就是线程安全的,为什么要加锁呢,而且对于写操作,还加的是读锁,这就导致可以有很多线程同时去写,对于写来说,相当加锁加了个寂寞。
带着疑惑,接着往下看。
Eureka服务实例的拉取方式和hash对比机制
拉取方式
Eureka作为一个注册中心,客户端肯定需要知道服务端道理存了哪些服务实例吧,所以就涉及到了服务的发现,从而涉及到了客户端跟服务端数据的交互方式,pull还是push。
那么Eureka到底是pull还是push模式呢?这里我就不再卖关子了,其实是一种pull模式,也就是说客户端会定期从服务端拉取服务实例的数据。并且Eureka提供了两种拉取方式,全量和增量。
1、全量
全量其实很好理解,就是拉取注册表所有的数据。
全量一般发生在客户端启动之后第一次获取注册表的信息的时候,就会全量拉取注册表。还有一种场景也会全量拉取,后面会说。
2、增量
增量,前面在说加写锁的时候提到了,就是获取最近发生变化的实例的信息,也就是recentlyChangedQueue里面的数据。
增量相比于全量拉取的好处就是可以减少资源的浪费,假如全量拉取的时候数据压根就没有变动,那么白白浪费网络资源;但是如果是增量的话,数据没有变动,那么就没有增量信息,就不会有资源的浪费。
在客户端第一次启动的全量拉取之后,定时任务每次拉取的就是增量数据。
增量拉取的hash对比机制
如果是增量拉取,客户端在拉取到增量数据之后会多干两件事:
- 会将增量信息跟本地缓存的服务实例进行合并
- 判断合并后的服务的数据跟服务端的数据是不是一样
那么如何去判定客户端的数据跟服务端的数据是不是一样呢?
Eureka是通过一种hash对比的机制来实现的。
当服务端生成增量信息的时候,同时会生成一个代表这一刻全部服务实例的hash值,设置到返回值中,代码如下
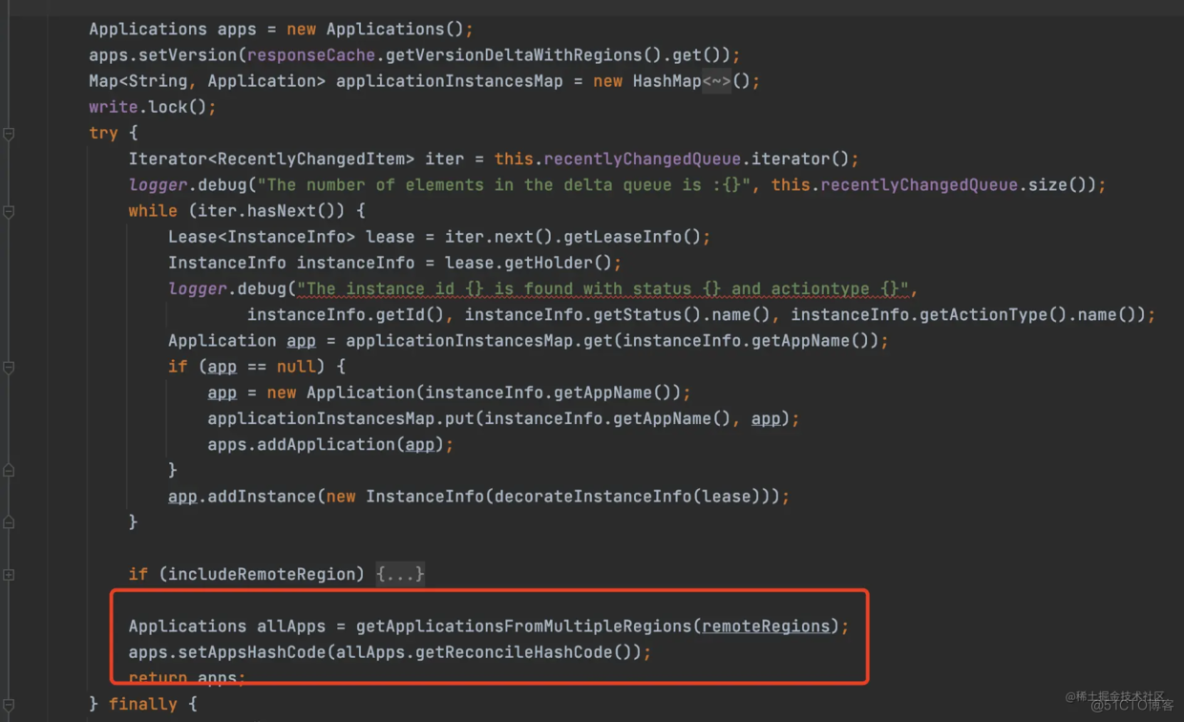
所以增量信息返回的数据有两部分,一部分是变动的实例的信息,还有就是这一刻服务端所有的实例信息生成的hash值。
当客户端拉取到增量信息并跟本地原有的老的服务实例合并完增量信息之后,客户端会用相同的方式计算出合并后服务实例的hash值,然后会跟服务端返回的hash值进行对比,如果一样,说明本次增量拉取之后,客户端缓存的服务实例跟服务端一样,如果不一样,说明两边的服务实例的数据不一样。
这就是hash对比机制,通过这个机制来判断增量拉取的时候两边的服务实例数据是不是一样。
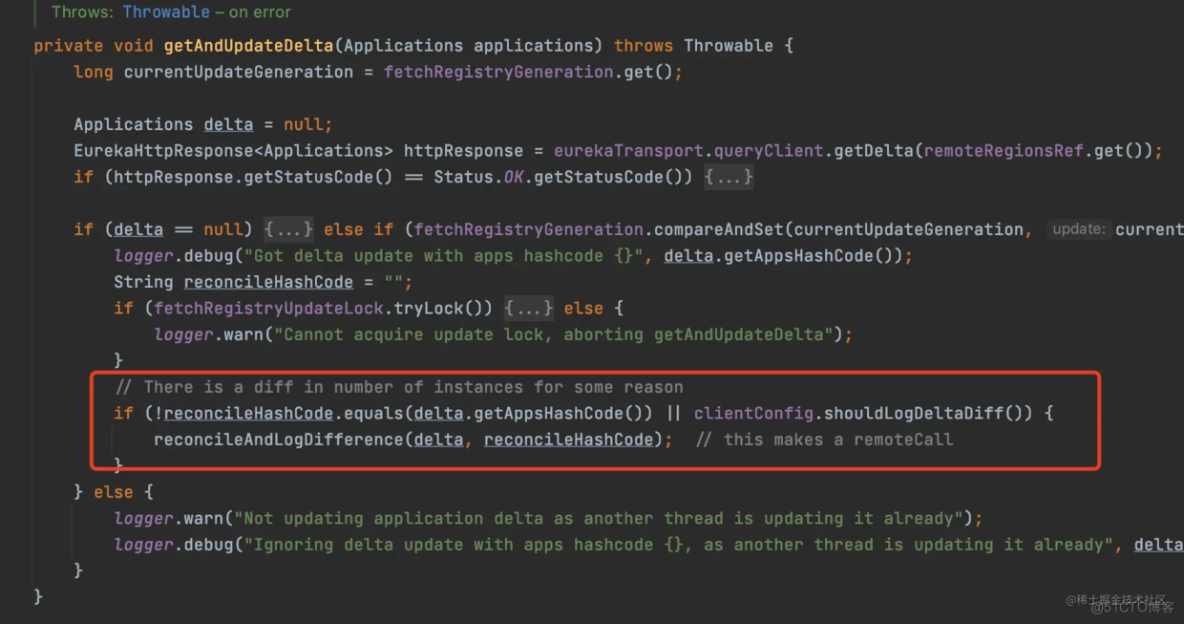
hash对比
但是,如果发现了不一样,那么此时客户端就会重新从服务端全量拉取一次服务数据,然后将该次全量拉取的数据设置到本地的缓存中,所以前面说的还有一种全量拉取的场景就在这里,源码如下
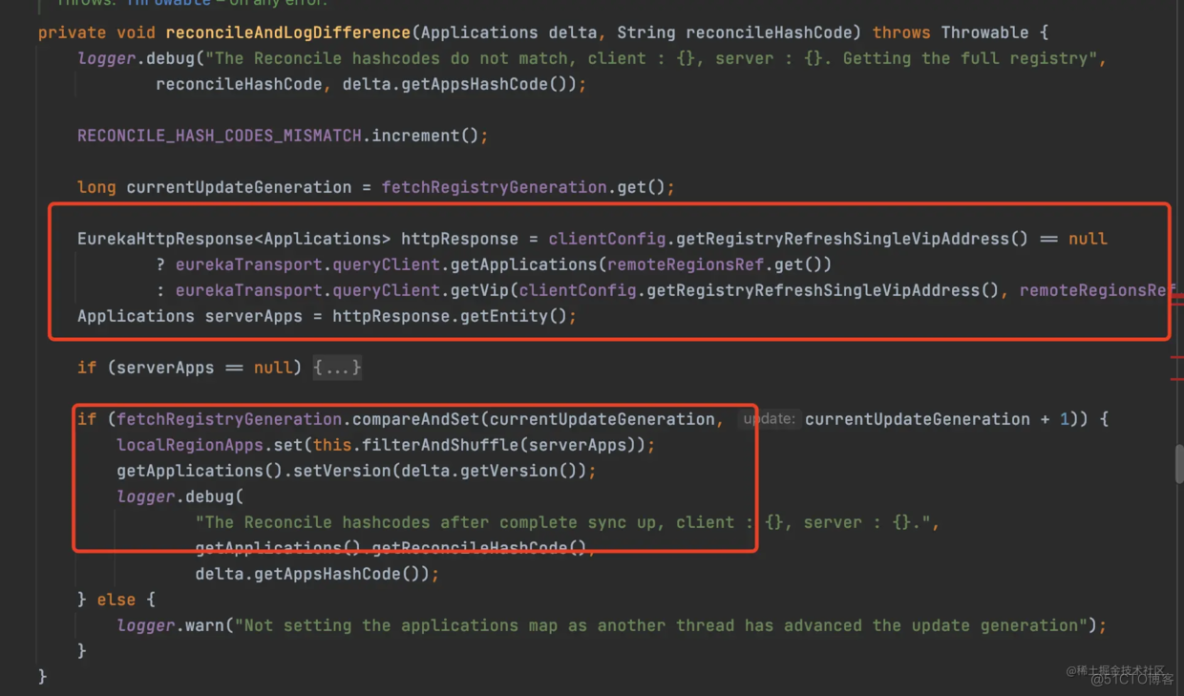
重新全量拉取
读写锁的使用揭秘
前面说了增量拉取和hash对比机制,此时我们再回过头仔细分析一下增量信息封装的两步操作:
- 第一步遍历recentlyChangedQueue,封装增量的实例信息
- 第二步生成所有服务实例数据对应的hash值,设置到增量信息返回值中
为什么要加锁
假设不加锁,那么对于注册表和recentlyChangedQueue读写都可以同时进行,那么会出现这么一种情况
当获取增量信息的时候,在第一步遍历recentlyChangedQueue时有2个变动的实例,注册表总共有5个实例
当recentlyChangedQueue遍历完之后,还没有进行第二步计算hash值时,此时有服务实例来注册了,由于不加锁,那么可以同时操作注册表和recentlyChangedQueue,于是注册成功之后注册表数据就变成了6个实例,recentlyChangedQueue也会添加一条数据
但是因为recentlyChangedQueue已经遍历完了,此时不会在遍历了,那么刚注册的这个实例在此次获取增量数据时就获取不到了,但是由于计算hash值是通过这一时刻所有的实例数据来计算,那么就会把这个新的实例计算进去了。
这不完犊子了么,增量信息没有,但是全部实例数据的hash值有,那么就会导致客户端在合并增量信息之后计算的hash值跟返回的hash值不一样,就会导致再次全量拉取,白白浪费了本次增量拉取操作。
所以一定要加锁,保证在获取增量数据时,不能对注册表进行改动。
为什么加读写锁而不是synchronized锁
这个其实跟Eureka没多大关系,主要是读写锁和synchronized锁特性决定的。synchronized会使得所有的操作都是串行化,虽然也能解决问题,但是也会导致并发性能降低。
为什么写时加读锁,读时加写锁
现在我们转过来,按照正常的操作,服务注册等写操作加写锁,获取增量的时候加读锁,那么可以不可呢?
其实也是可以的,因为这样注册表写操作和获取的增量信息读操作还是互斥的,那么获取的增量信息还是对的。
那么为什么Eureka要反过来?
写(锁)写(锁)是互斥的。如果注册表写操作加了写锁,那么所有的服务注册、下线、状态更新都会串行执行,并发性能就会降低,所以对于注册表写操作加了读锁,可以提高写的性能。
但是,如果获取的增量读的操作加了写锁,那岂不是读操作都串行化了,那么读的性能不是会变低么?而且注册中心其实是一个读多写少的场景,为了提升写的性能,浪费读的性能不是得不偿失么?
哈哈,其实对于这个读操作性能低的问题,Eureka也进行了优化,那就是通过缓存来优化了这个读的性能问题,读的时候先读缓存,缓存没有才会真正调用获取增量的方法来读取增量的信息,所以最后真正走到获取增量信息的方法,请求量很低。
ResponseCacheImpl
ResponseCacheImpl内部封装了缓存的操作,因为不是本文的重点,这里就不讨论了。
总结
所以,通过上面的一步一步分析,终于知道了Eureka读写锁的加锁场景、为什么要加读写锁以及为什么写时加读锁,读时加写锁。这里我再总结一下:
为什么加读写锁
是为了保证获取增量信息的读操作和注册表的写操作互斥,避免由于并发问题导致获取到的增量信息和实际注册表的数据对不上,从而引发客户端的多余的一次全量拉取的操作。
为什么写时加读锁,读时加写锁
其实是为了提升写的性能,而读由于有缓存的原因,真正走到获取增量信息的请求很少,所以读的时候就算加写锁,对于读的性能也没有多大的影响。
从Eureka对于读写锁的使用也可以看出,一个技术什么时候用,如何使用都是根据具体的场景来判断的,不能要一概而论。